 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDictionary Learning with Accumulator Neurons
May 30, 2022
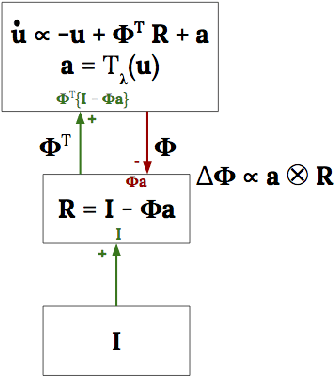
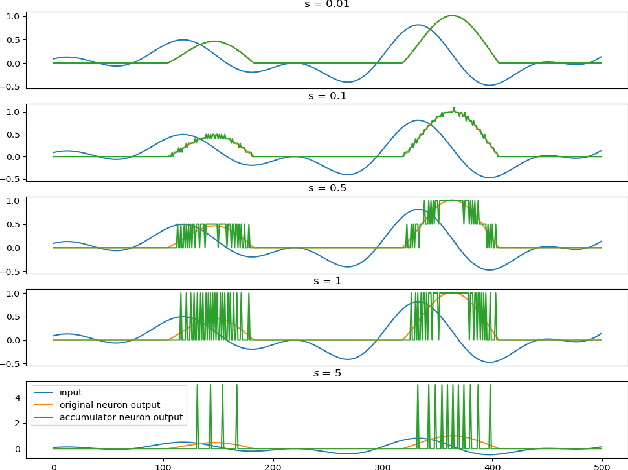

The Locally Competitive Algorithm (LCA) uses local competition between non-spiking leaky integrator neurons to infer sparse representations, allowing for potentially real-time execution on massively parallel neuromorphic architectures such as Intel's Loihi processor. Here, we focus on the problem of inferring sparse representations from streaming video using dictionaries of spatiotemporal features optimized in an unsupervised manner for sparse reconstruction. Non-spiking LCA has previously been used to achieve unsupervised learning of spatiotemporal dictionaries composed of convolutional kernels from raw, unlabeled video. We demonstrate how unsupervised dictionary learning with spiking LCA (\hbox{S-LCA}) can be efficiently implemented using accumulator neurons, which combine a conventional leaky-integrate-and-fire (\hbox{LIF}) spike generator with an additional state variable that is used to minimize the difference between the integrated input and the spiking output. We demonstrate dictionary learning across a wide range of dynamical regimes, from graded to intermittent spiking, for inferring sparse representations of both static images drawn from the CIFAR database as well as video frames captured from a DVS camera. On a classification task that requires identification of the suite from a deck of cards being rapidly flipped through as viewed by a DVS camera, we find essentially no degradation in performance as the LCA model used to infer sparse spatiotemporal representations migrates from graded to spiking. We conclude that accumulator neurons are likely to provide a powerful enabling component of future neuromorphic hardware for implementing online unsupervised learning of spatiotemporal dictionaries optimized for sparse reconstruction of streaming video from event based DVS cameras.
EvoSTS Forecasting: Evolutionary Sparse Time-Series Forecasting
Apr 14, 2022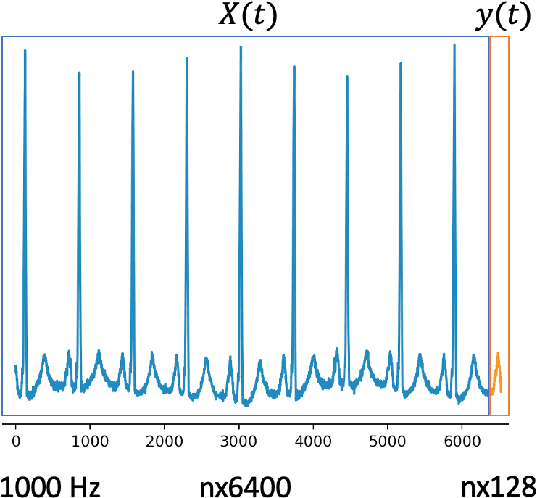
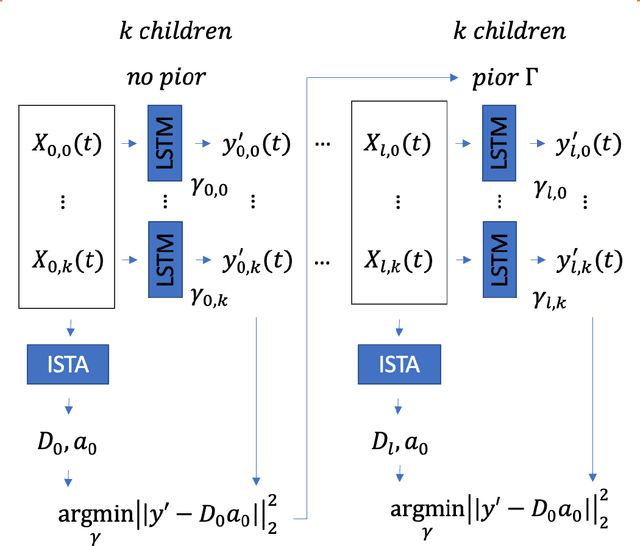

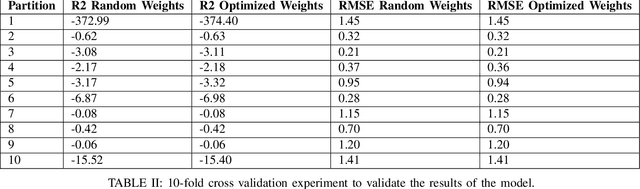
In this work, we highlight our novel evolutionary sparse time-series forecasting algorithm also known as EvoSTS. The algorithm attempts to evolutionary prioritize weights of Long Short-Term Memory (LSTM) Network that best minimize the reconstruction loss of a predicted signal using a learned sparse coded dictionary. In each generation of our evolutionary algorithm, a set number of children with the same initial weights are spawned. Each child undergoes a training step and adjusts their weights on the same data. Due to stochastic back-propagation, the set of children has a variety of weights with different levels of performance. The weights that best minimize the reconstruction loss with a given signal dictionary are passed to the next generation. The predictions from the best-performing weights of the first and last generation are compared. We found improvements while comparing the weights of these two generations. However, due to several confounding parameters and hyperparameter limitations, some of the weights had negligible improvements. To the best of our knowledge, this is the first attempt to use sparse coding in this way to optimize time series forecasting model weights, such as those of an LSTM network.
Perception Over Time: Temporal Dynamics for Robust Image Understanding
Mar 11, 2022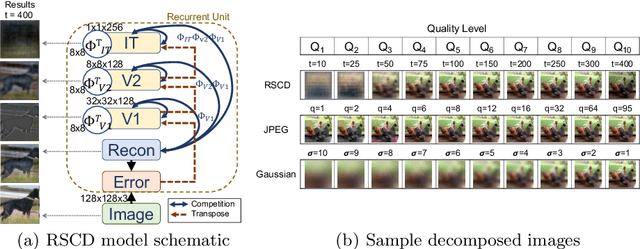

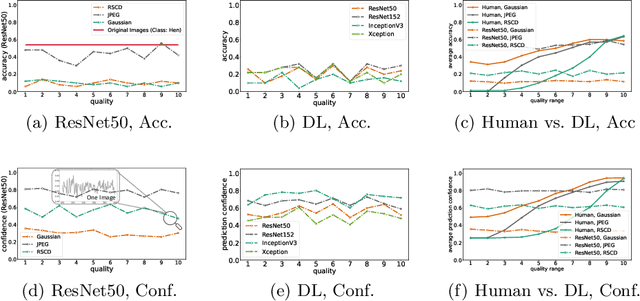
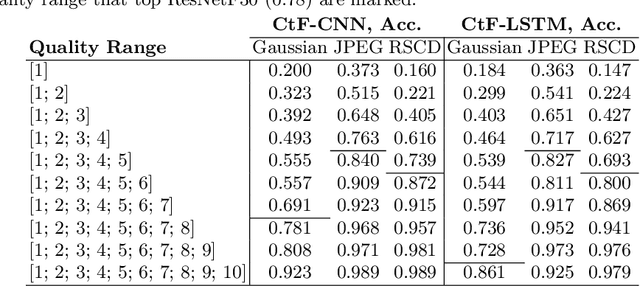
While deep learning surpasses human-level performance in narrow and specific vision tasks, it is fragile and over-confident in classification. For example, minor transformations in perspective, illumination, or object deformation in the image space can result in drastically different labeling, which is especially transparent via adversarial perturbations. On the other hand, human visual perception is orders of magnitude more robust to changes in the input stimulus. But unfortunately, we are far from fully understanding and integrating the underlying mechanisms that result in such robust perception. In this work, we introduce a novel method of incorporating temporal dynamics into static image understanding. We describe a neuro-inspired method that decomposes a single image into a series of coarse-to-fine images that simulates how biological vision integrates information over time. Next, we demonstrate how our novel visual perception framework can utilize this information "over time" using a biologically plausible algorithm with recurrent units, and as a result, significantly improving its accuracy and robustness over standard CNNs. We also compare our proposed approach with state-of-the-art models and explicitly quantify our adversarial robustness properties through multiple ablation studies. Our quantitative and qualitative results convincingly demonstrate exciting and transformative improvements over the standard computer vision and deep learning architectures used today.
Querying Labelled Data with Scenario Programs for Sim-to-Real Validation
Dec 01, 2021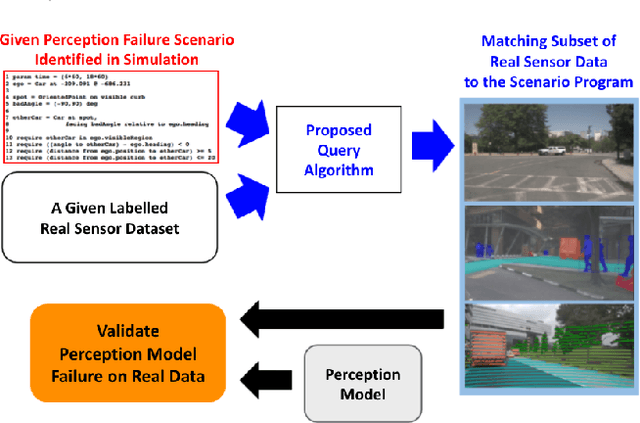

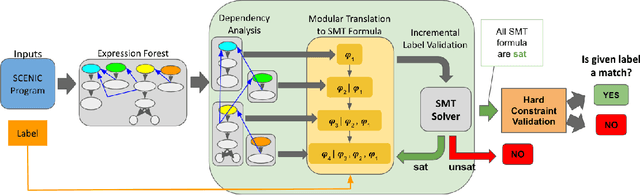
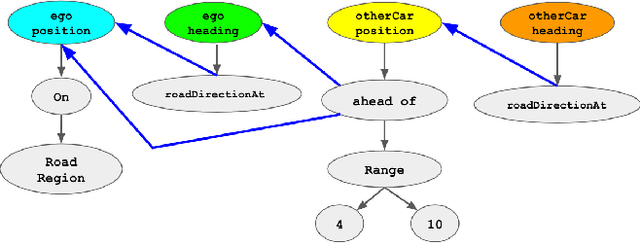
Simulation-based testing of autonomous vehicles (AVs) has become an essential complement to road testing to ensure safety. Consequently, substantial research has focused on searching for failure scenarios in simulation. However, a fundamental question remains: are AV failure scenarios identified in simulation meaningful in reality, i.e., are they reproducible on the real system? Due to the sim-to-real gap arising from discrepancies between simulated and real sensor data, a failure scenario identified in simulation can be either a spurious artifact of the synthetic sensor data or an actual failure that persists with real sensor data. An approach to validate simulated failure scenarios is to identify instances of the scenario in a corpus of real data, and check if the failure persists on the real data. To this end, we propose a formal definition of what it means for a labelled data item to match an abstract scenario, encoded as a scenario program using the SCENIC probabilistic programming language. Using this definition, we develop a querying algorithm which, given a scenario program and a labelled dataset, finds the subset of data matching the scenario. Experiments demonstrate that our algorithm is accurate and efficient on a variety of realistic traffic scenarios, and scales to a reasonable number of agents.
A Scenario-Based Platform for Testing Autonomous Vehicle Behavior Prediction Models in Simulation
Nov 14, 2021

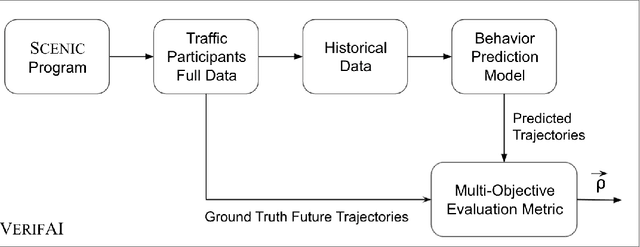
Behavior prediction remains one of the most challenging tasks in the autonomous vehicle (AV) software stack. Forecasting the future trajectories of nearby agents plays a critical role in ensuring road safety, as it equips AVs with the necessary information to plan safe routes of travel. However, these prediction models are data-driven and trained on data collected in real life that may not represent the full range of scenarios an AV can encounter. Hence, it is important that these prediction models are extensively tested in various test scenarios involving interactive behaviors prior to deployment. To support this need, we present a simulation-based testing platform which supports (1) intuitive scenario modeling with a probabilistic programming language called Scenic, (2) specifying a multi-objective evaluation metric with a partial priority ordering, (3) falsification of the provided metric, and (4) parallelization of simulations for scalable testing. As a part of the platform, we provide a library of 25 Scenic programs that model challenging test scenarios involving interactive traffic participant behaviors. We demonstrate the effectiveness and the scalability of our platform by testing a trained behavior prediction model and searching for failure scenarios.
Multi-Agent Algorithmic Recourse
Oct 01, 2021


The recent adoption of machine learning as a tool in real world decision making has spurred interest in understanding how these decisions are being made. Counterfactual Explanations are a popular interpretable machine learning technique that aims to understand how a machine learning model would behave if given alternative inputs. Many explanations attempt to go further and recommend actions an individual could take to obtain a more desirable output from the model. These recommendations are known as algorithmic recourse. Past work has largely focused on the effect algorithmic recourse has on a single agent. In this work, we show that when the assumption of a single agent environment is relaxed, current approaches to algorithmic recourse fail to guarantee certain ethically desirable properties. Instead, we propose a new game theory inspired framework for providing algorithmic recourse in a multi-agent environment that does guarantee these properties.
Addressing the IEEE AV Test Challenge with Scenic and VerifAI
Aug 20, 2021

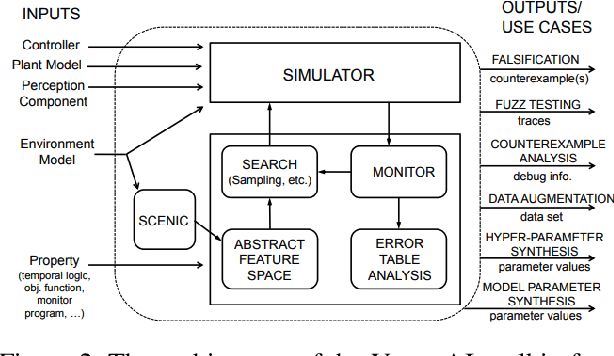
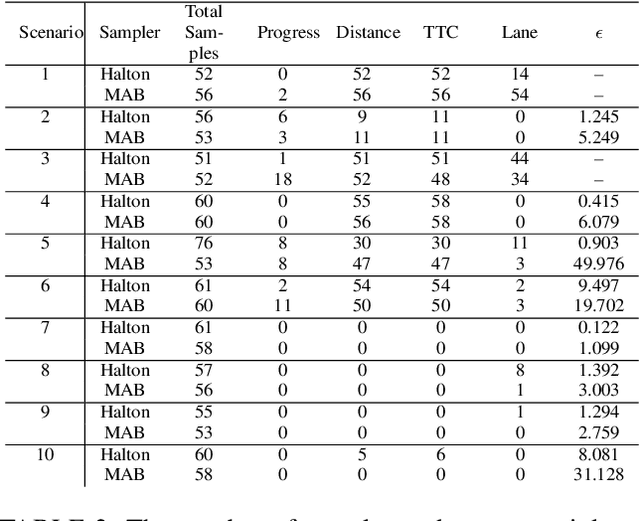
This paper summarizes our formal approach to testing autonomous vehicles (AVs) in simulation for the IEEE AV Test Challenge. We demonstrate a systematic testing framework leveraging our previous work on formally-driven simulation for intelligent cyber-physical systems. First, to model and generate interactive scenarios involving multiple agents, we used Scenic, a probabilistic programming language for specifying scenarios. A Scenic program defines an abstract scenario as a distribution over configurations of physical objects and their behaviors over time. Sampling from an abstract scenario yields many different concrete scenarios which can be run as test cases for the AV. Starting from a Scenic program encoding an abstract driving scenario, we can use the VerifAI toolkit to search within the scenario for failure cases with respect to multiple AV evaluation metrics. We demonstrate the effectiveness of our testing framework by identifying concrete failure scenarios for an open-source autopilot, Apollo, starting from a variety of realistic traffic scenarios.
Parallel and Multi-Objective Falsification with Scenic and VerifAI
Jul 09, 2021

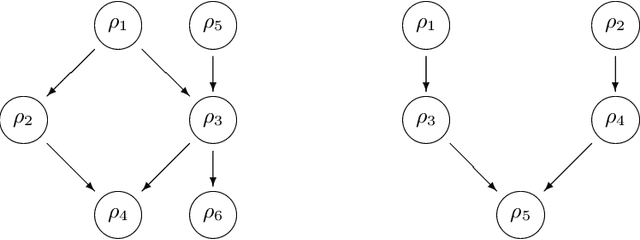
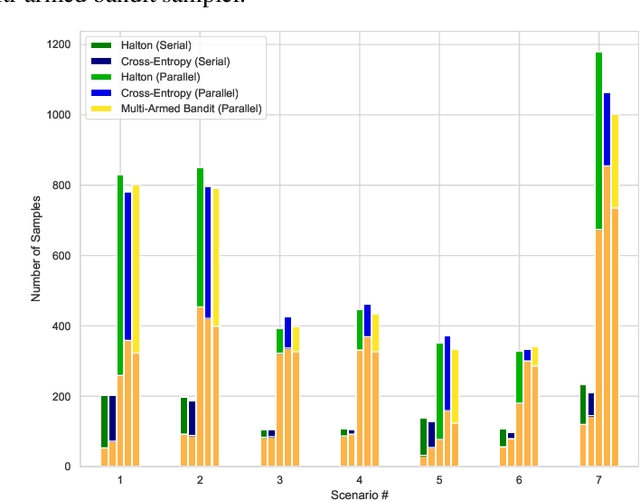
Falsification has emerged as an important tool for simulation-based verification of autonomous systems. In this paper, we present extensions to the Scenic scenario specification language and VerifAI toolkit that improve the scalability of sampling-based falsification methods by using parallelism and extend falsification to multi-objective specifications. We first present a parallelized framework that is interfaced with both the simulation and sampling capabilities of Scenic and the falsification capabilities of VerifAI, reducing the execution time bottleneck inherently present in simulation-based testing. We then present an extension of VerifAI's falsification algorithms to support multi-objective optimization during sampling, using the concept of rulebooks to specify a preference ordering over multiple metrics that can be used to guide the counterexample search process. Lastly, we evaluate the benefits of these extensions with a comprehensive set of benchmarks written in the Scenic language.
Scenic4RL: Programmatic Modeling and Generation of Reinforcement Learning Environments
Jun 18, 2021
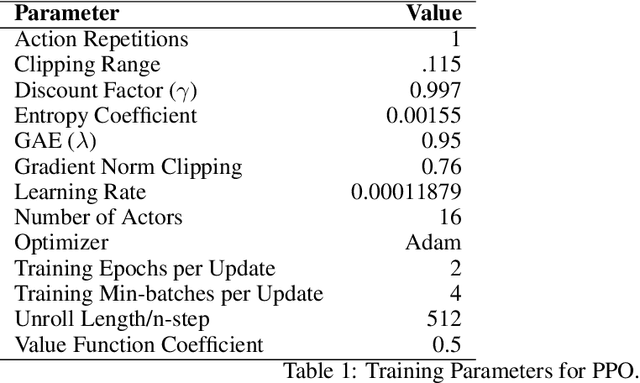

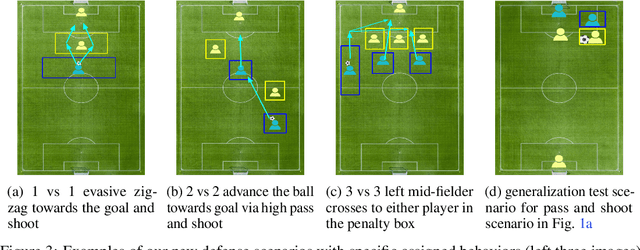
The capability of reinforcement learning (RL) agent directly depends on the diversity of learning scenarios the environment generates and how closely it captures real-world situations. However, existing environments/simulators lack the support to systematically model distributions over initial states and transition dynamics. Furthermore, in complex domains such as soccer, the space of possible scenarios is infinite, which makes it impossible for one research group to provide a comprehensive set of scenarios to train, test, and benchmark RL algorithms. To address this issue, for the first time, we adopt an existing formal scenario specification language, SCENIC, to intuitively model and generate interactive scenarios. We interfaced SCENIC to Google Research Soccer environment to create a platform called SCENIC4RL. Using this platform, we provide a dataset consisting of 36 scenario programs encoded in SCENIC and demonstration data generated from a subset of them. We share our experimental results to show the effectiveness of our dataset and the platform to train, test, and benchmark RL algorithms. More importantly, we open-source our platform to enable RL community to collectively contribute to constructing a comprehensive set of scenarios.
ATRAS: Adversarially Trained Robust Architecture Search
Jun 13, 2021

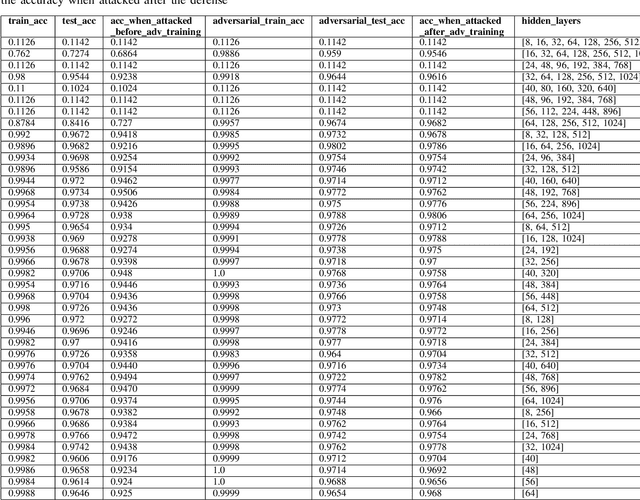
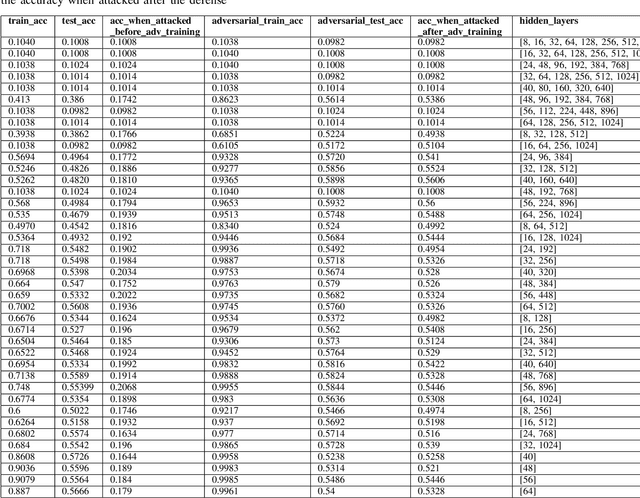
In this paper, we explore the effect of architecture completeness on adversarial robustness. We train models with different architectures on CIFAR-10 and MNIST dataset. For each model, we vary different number of layers and different number of nodes in the layer. For every architecture candidate, we use Fast Gradient Sign Method (FGSM) to generate untargeted adversarial attacks and use adversarial training to defend against those attacks. For each architecture candidate, we report pre-attack, post-attack and post-defense accuracy for the model as well as the architecture parameters and the impact of completeness to the model accuracies.