 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCDE: Sentence Cloze Dataset with High Quality Distractors From Examinations
Apr 27, 2020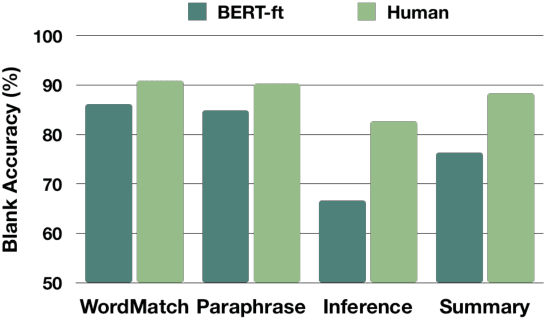
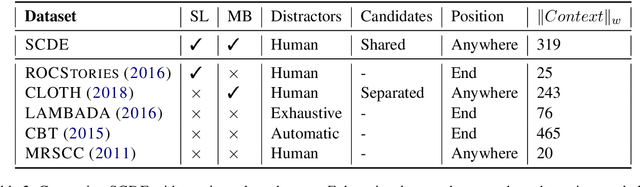
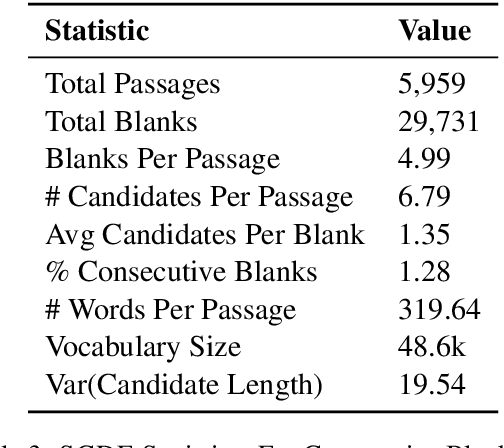
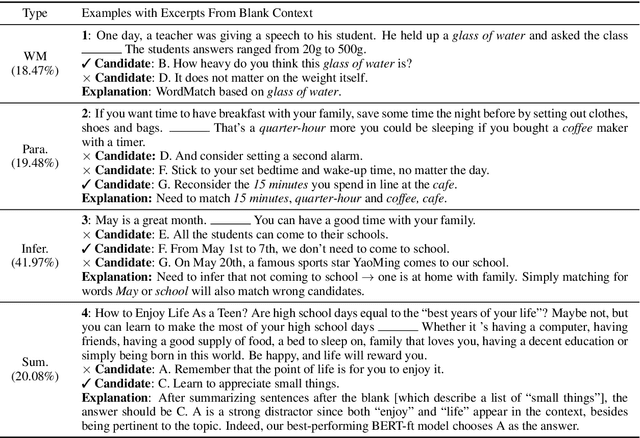
We introduce SCDE, a dataset to evaluate the performance of computational models through sentence prediction. SCDE is a human-created sentence cloze dataset, collected from public school English examinations. Our task requires a model to fill up multiple blanks in a passage from a shared candidate set with distractors designed by English teachers. Experimental results demonstrate that this task requires the use of non-local, discourse-level context beyond the immediate sentence neighborhood. The blanks require joint solving and significantly impair each other's context. Furthermore, through ablations, we show that the distractors are of high quality and make the task more challenging. Our experiments show that there is a significant performance gap between advanced models (72%) and humans (87%), encouraging future models to bridge this gap.
Decoupling Global and Local Representations from/for Image Generation
Apr 12, 2020
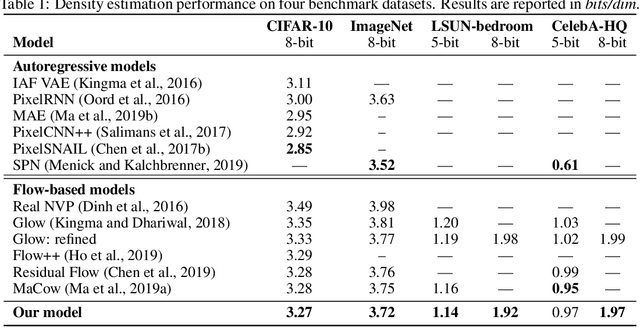
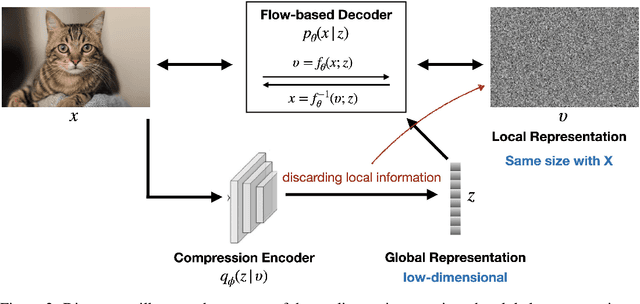

In this work, we propose a new generative model that is capable of automatically decoupling global and local representations of images in an entirely unsupervised setting. The proposed model utilizes the variational auto-encoding framework to learn a (low-dimensional) vector of latent variables to capture the global information of an image, which is fed as a conditional input to a flow-based invertible decoder with architecture borrowed from style transfer literature. Experimental results on standard image benchmarks demonstrate the effectiveness of our model in terms of density estimation, image generation and unsupervised representation learning. Importantly, this work demonstrates that with only architectural inductive biases, a generative model with a plain log-likelihood objective is capable of learning decoupled representations, requiring no explicit supervision. The code for our model is available at https://github.com/XuezheMax/wolf.
Decompressing Knowledge Graph Representations for Link Prediction
Nov 19, 2019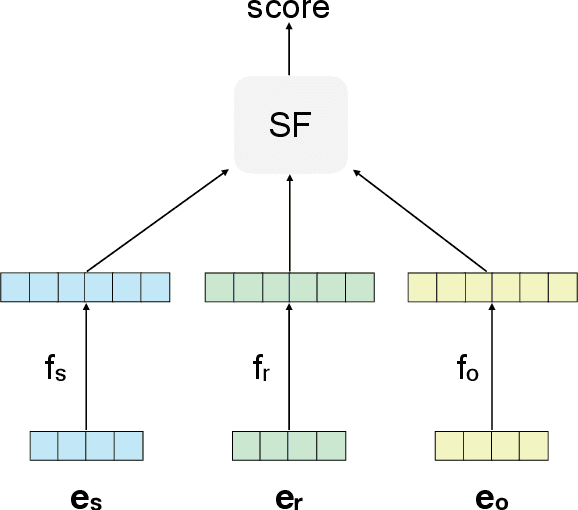

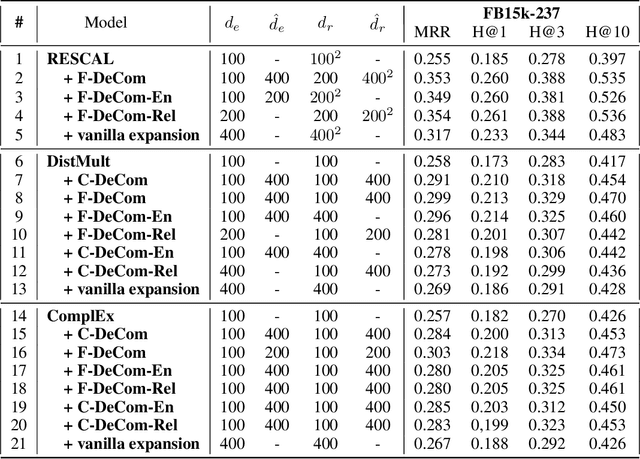
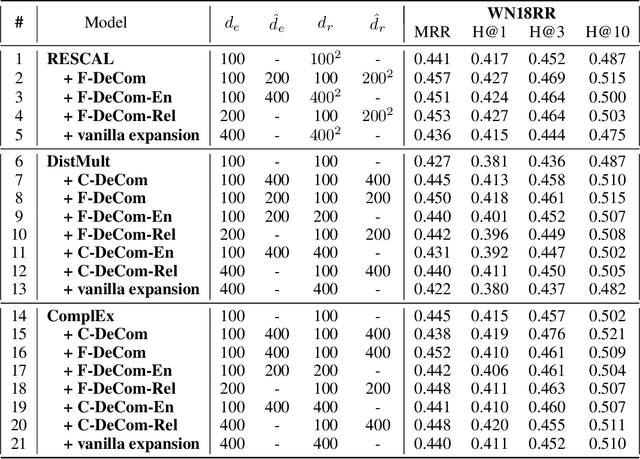
This paper studies the problem of predicting missing relationships between entities in knowledge graphs through learning their representations. Currently, the majority of existing link prediction models employ simple but intuitive scoring functions and relatively small embedding size so that they could be applied to large-scale knowledge graphs. However, these properties also restrict the ability to learn more expressive and robust features. Therefore, diverging from most of the prior works which focus on designing new objective functions, we propose, DeCom, a simple but effective mechanism to boost the performance of existing link predictors such as DistMult, ComplEx, etc, through extracting more expressive features while preventing overfitting by adding just a few extra parameters. Specifically, embeddings of entities and relationships are first decompressed to a more expressive and robust space by decompressing functions, then knowledge graph embedding models are trained in this new feature space. Experimental results on several benchmark knowledge graphs and advanced link prediction systems demonstrate the generalization and effectiveness of our method. Especially, RESCAL + DeCom achieves state-of-the-art performance on the FB15k-237 benchmark across all evaluation metrics. In addition, we also show that compared with DeCom, explicitly increasing the embedding size significantly increase the number of parameters but could not achieve promising performance improvement.
Self-training with Noisy Student improves ImageNet classification
Nov 11, 2019
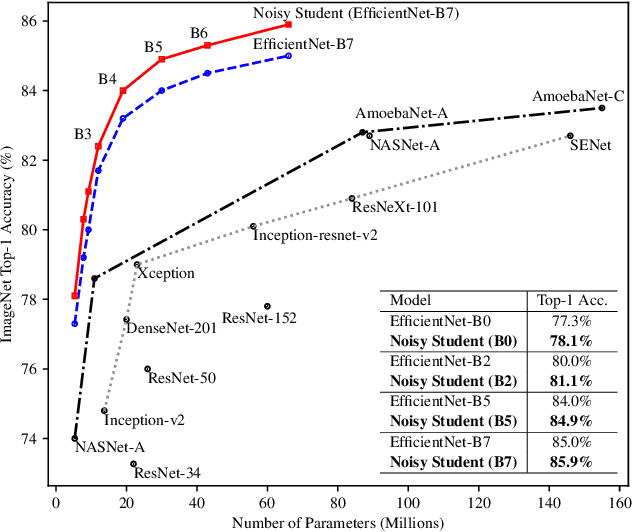
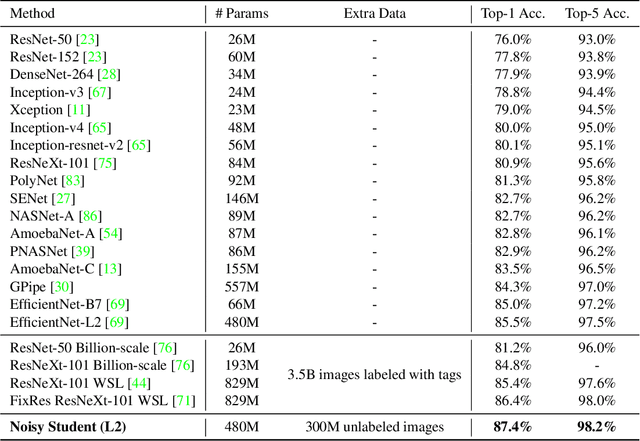

We present a simple self-training method that achieves 87.4% top-1 accuracy on ImageNet, which is 1.0% better than the state-of-the-art model that requires 3.5B weakly labeled Instagram images. On robustness test sets, it improves ImageNet-A top-1 accuracy from 16.6% to 74.2%, reduces ImageNet-C mean corruption error from 45.7 to 31.2, and reduces ImageNet-P mean flip rate from 27.8 to 16.1. To achieve this result, we first train an EfficientNet model on labeled ImageNet images and use it as a teacher to generate pseudo labels on 300M unlabeled images. We then train a larger EfficientNet as a student model on the combination of labeled and pseudo labeled images. We iterate this process by putting back the student as the teacher. During the generation of the pseudo labels, the teacher is not noised so that the pseudo labels are as good as possible. But during the learning of the student, we inject noise such as data augmentation, dropout, stochastic depth to the student so that the noised student is forced to learn harder from the pseudo labels.
xSLUE: A Benchmark and Analysis Platform for Cross-Style Language Understanding and Evaluation
Nov 09, 2019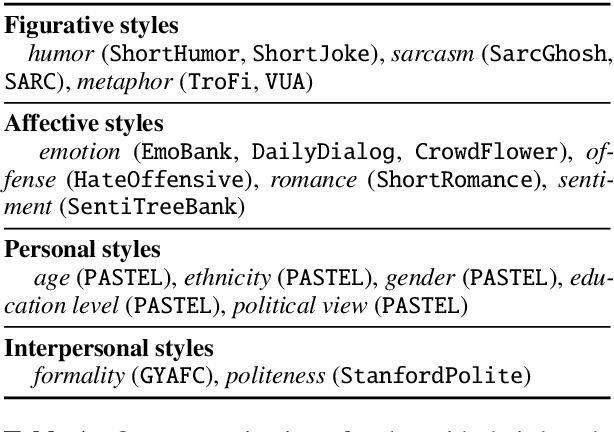
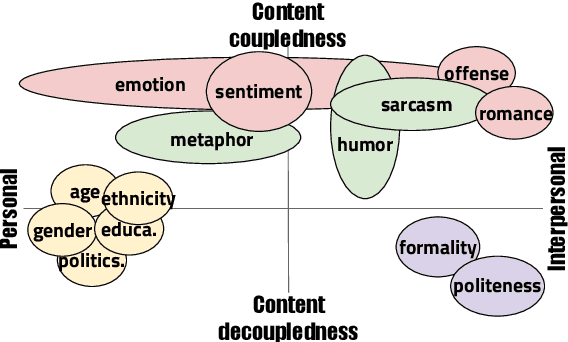
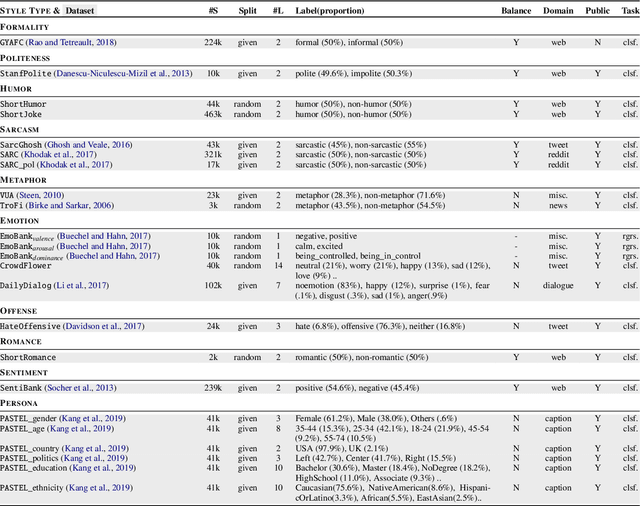
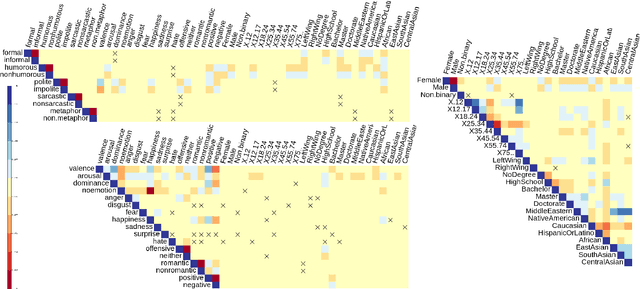
Every natural text is written in some style. The style is formed by a complex combination of different stylistic factors, including formality markers, emotions, metaphors, etc. Some factors implicitly reflect the author's personality, while others are explicitly controlled by the author's choices in order to achieve some personal or social goal. One cannot form a complete understanding of a text and its author without considering these factors. The factors combine and co-vary in complex ways to form styles. Studying the nature of the covarying combinations sheds light on stylistic language in general, sometimes called cross-style language understanding. This paper provides a benchmark corpus (xSLUE) with an online platform (http://xslue.com) for cross-style language understanding and evaluation. The benchmark contains text in 15 different styles and 23 classification tasks. For each task, we provide the fine-tuned classifier for further analysis. Our analysis shows that some styles are highly dependent on each other (e.g., impoliteness and offense), and some domains (e.g., tweets, political debates) are stylistically more diverse than others (e.g., academic manuscripts). We discuss the technical challenges of cross-style understanding and potential directions for future research: cross-style modeling which shares the internal representation for low-resource or low-performance styles and other applications such as cross-style generation.
Do Sentence Interactions Matter? Leveraging Sentence Level Representations for Fake News Classification
Oct 27, 2019


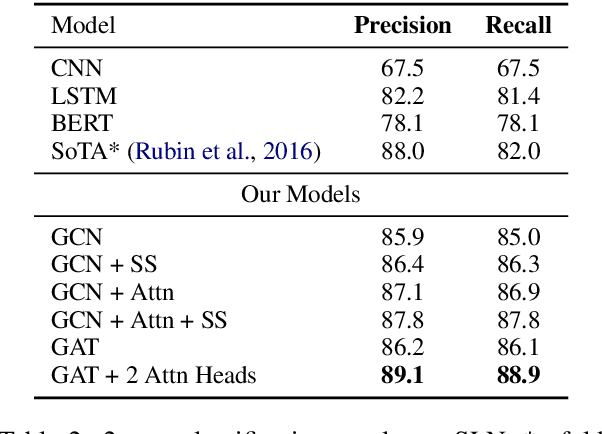
The rising growth of fake news and misleading information through online media outlets demands an automatic method for detecting such news articles. Of the few limited works which differentiate between trusted vs other types of news article (satire, propaganda, hoax), none of them model sentence interactions within a document. We observe an interesting pattern in the way sentences interact with each other across different kind of news articles. To capture this kind of information for long news articles, we propose a graph neural network-based model which does away with the need of feature engineering for fine grained fake news classification. Through experiments, we show that our proposed method beats strong neural baselines and achieves state-of-the-art accuracy on existing datasets. Moreover, we establish the generalizability of our model by evaluating its performance in out-of-domain scenarios. Code is available at https://github.com/MysteryVaibhav/fake_news_semantics
FlowSeq: Non-Autoregressive Conditional Sequence Generation with Generative Flow
Oct 09, 2019
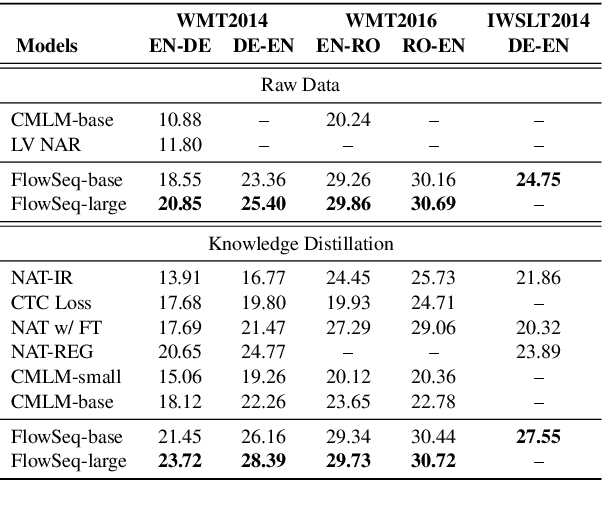
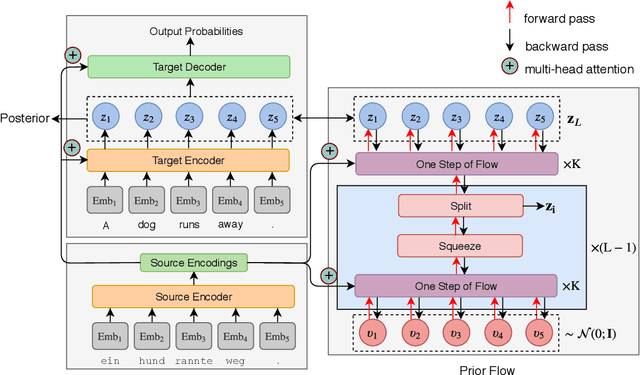
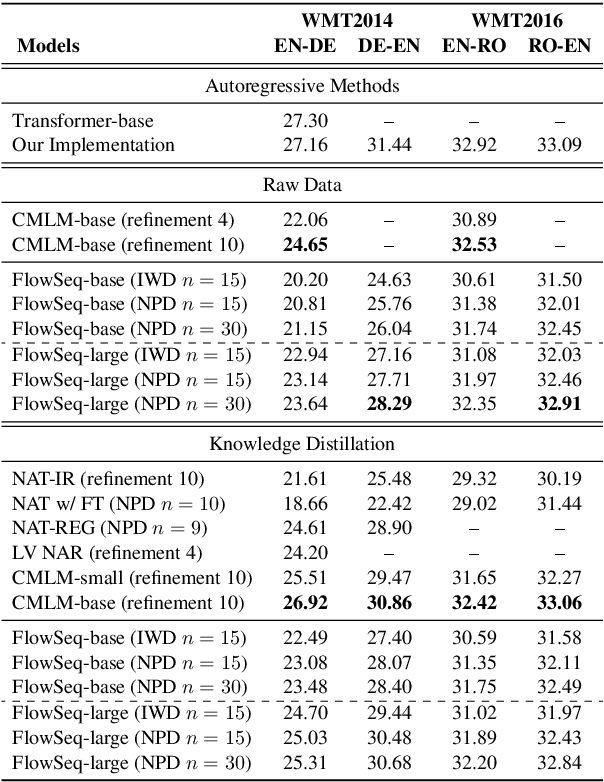
Most sequence-to-sequence (seq2seq) models are autoregressive; they generate each token by conditioning on previously generated tokens. In contrast, non-autoregressive seq2seq models generate all tokens in one pass, which leads to increased efficiency through parallel processing on hardware such as GPUs. However, directly modeling the joint distribution of all tokens simultaneously is challenging, and even with increasingly complex model structures accuracy lags significantly behind autoregressive models. In this paper, we propose a simple, efficient, and effective model for non-autoregressive sequence generation using latent variable models. Specifically, we turn to generative flow, an elegant technique to model complex distributions using neural networks, and design several layers of flow tailored for modeling the conditional density of sequential latent variables. We evaluate this model on three neural machine translation (NMT) benchmark datasets, achieving comparable performance with state-of-the-art non-autoregressive NMT models and almost constant decoding time w.r.t the sequence length.
* Accepted by EMNLP 2019 (Long Paper)
Learning the Difference that Makes a Difference with Counterfactually-Augmented Data
Sep 26, 2019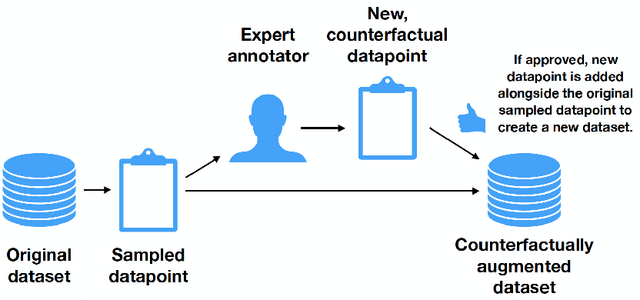
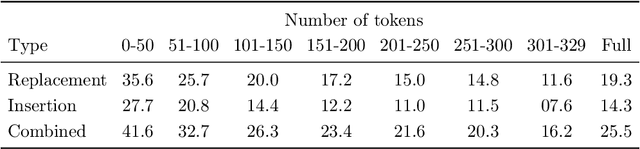
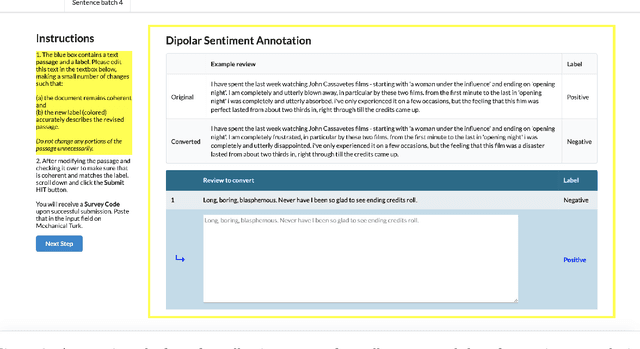

Despite alarm over the reliance of machine learning systems on so-called spurious patterns in training data, the term lacks coherent meaning in standard statistical frameworks. However, the language of causality offers clarity: spurious associations are those due to a common cause (confounding) vs direct or indirect effects. In this paper, we focus on NLP, introducing methods and resources for training models insensitive to spurious patterns. Given documents and their initial labels, we task humans with revise each document to accord with a counterfactual target label, asking that the revised documents be internally coherent while avoiding any gratuitous changes. Interestingly, on sentiment analysis and natural language inference tasks, classifiers trained on original data fail on their counterfactually-revised counterparts and vice versa. Classifiers trained on combined datasets perform remarkably well, just shy of those specialized to either domain. While classifiers trained on either original or manipulated data alone are sensitive to spurious features (e.g., mentions of genre), models trained on the combined data are insensitive to this signal. We will publicly release both datasets.
Definition Frames: Using Definitions for Hybrid Concept Representations
Sep 10, 2019
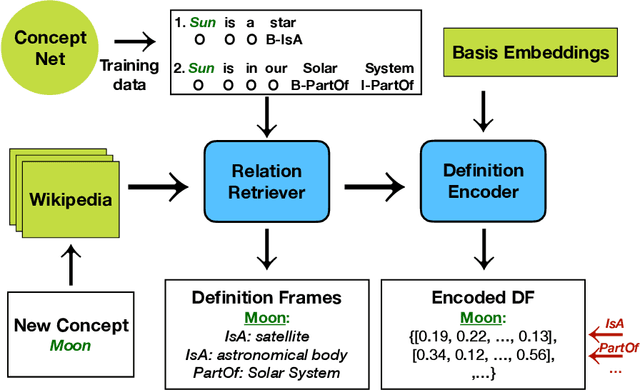
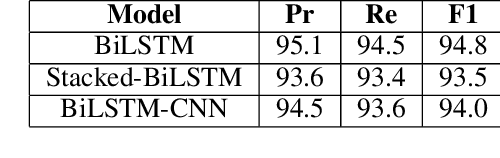
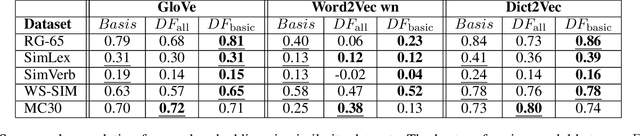
Concept representations is a particularly active area in NLP. Although recent advances in distributional semantics have shown tremendous improvements in performance, they still lack semantic interpretability. In this paper, we introduce a novel hybrid representation called Definition Frames, which is extracted from definitions under the formulation of domain-transfer Relation Extraction. Definition Frames are easily reformulated to a matrix representation where each row is semantically meaningful. This results in a fluid representation, where we can prune dimension(s) according to the type of information we want to retain for any specific task. Our results show that Definition Frames (1) maintain the significant semantic information of the original definition (human evaluation) and (2) have competitive performance with other distributional semantic approaches on word similarity tasks. Furthermore, our experiments show substantial improvements over word-embeddings when fine-tuned to a task even using only a linear transform.
Nested Named Entity Recognition via Second-best Sequence Learning and Decoding
Sep 05, 2019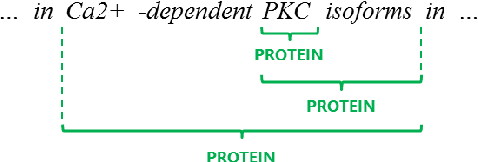
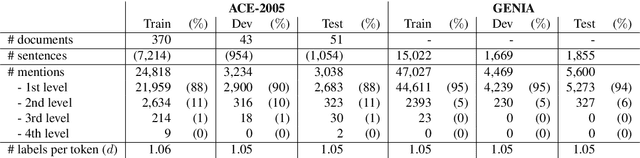
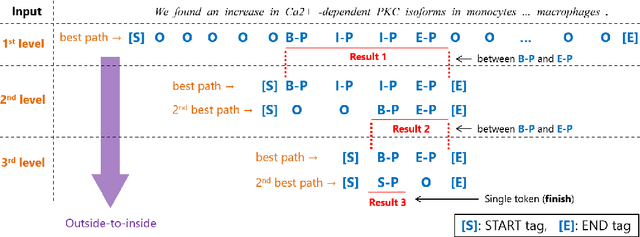
When an entity name contains other names within it, the identification of all combinations of names can become difficult and expensive. We propose a new method to recognize not only outermost named entities but also inner nested ones. We design an objective function for training a neural model that treats the tag sequence for nested entities as the second best path within the span of their parent entity. In addition, we provide the decoding method for inference that extracts entities iteratively from outermost ones to inner ones in an outside-to-inside way. Our method has no additional hyperparameters to the conditional random field based model widely used for flat named entity recognition tasks. Experiments demonstrate that our method outperforms existing methods capable of handling nested entities, achieving the F1-scores of 82.81%, 82.70%, and 77.25% on ACE-2004, ACE-2005, and GENIA datasets, respectively.