 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Energy-based Generative Adversarial Networks
Feb 24, 2017
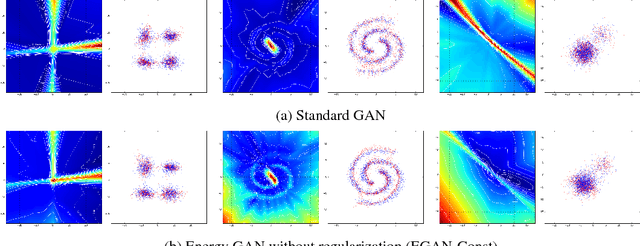
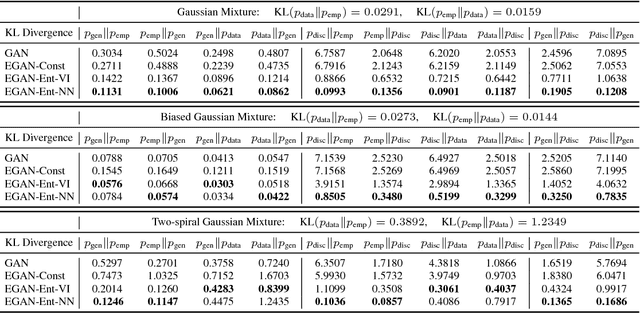
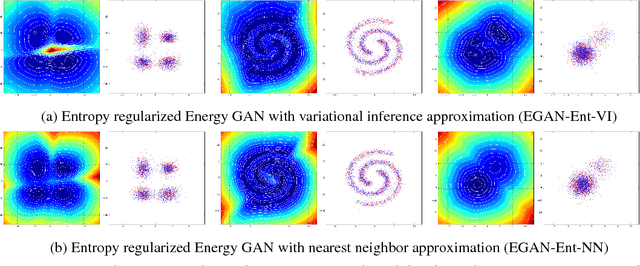
In this paper, we propose to equip Generative Adversarial Networks with the ability to produce direct energy estimates for samples.Specifically, we propose a flexible adversarial training framework, and prove this framework not only ensures the generator converges to the true data distribution, but also enables the discriminator to retain the density information at the global optimal. We derive the analytic form of the induced solution, and analyze the properties. In order to make the proposed framework trainable in practice, we introduce two effective approximation techniques. Empirically, the experiment results closely match our theoretical analysis, verifying the discriminator is able to recover the energy of data distribution.
Experiment Segmentation in Scientific Discourse as Clause-level Structured Prediction using Recurrent Neural Networks
Feb 17, 2017

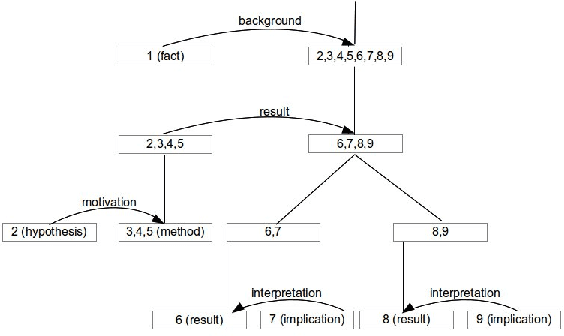
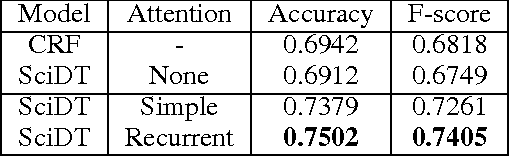
We propose a deep learning model for identifying structure within experiment narratives in scientific literature. We take a sequence labeling approach to this problem, and label clauses within experiment narratives to identify the different parts of the experiment. Our dataset consists of paragraphs taken from open access PubMed papers labeled with rhetorical information as a result of our pilot annotation. Our model is a Recurrent Neural Network (RNN) with Long Short-Term Memory (LSTM) cells that labels clauses. The clause representations are computed by combining word representations using a novel attention mechanism that involves a separate RNN. We compare this model against LSTMs where the input layer has simple or no attention and a feature rich CRF model. Furthermore, we describe how our work could be useful for information extraction from scientific literature.
Dropout with Expectation-linear Regularization
Feb 15, 2017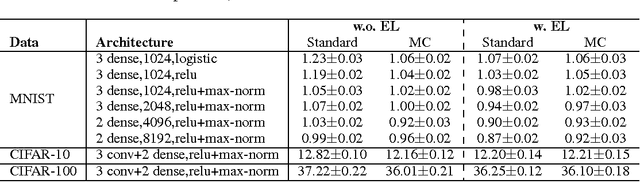
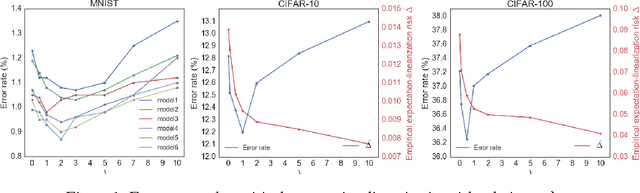

Dropout, a simple and effective way to train deep neural networks, has led to a number of impressive empirical successes and spawned many recent theoretical investigations. However, the gap between dropout's training and inference phases, introduced due to tractability considerations, has largely remained under-appreciated. In this work, we first formulate dropout as a tractable approximation of some latent variable model, leading to a clean view of parameter sharing and enabling further theoretical analysis. Then, we introduce (approximate) expectation-linear dropout neural networks, whose inference gap we are able to formally characterize. Algorithmically, we show that our proposed measure of the inference gap can be used to regularize the standard dropout training objective, resulting in an \emph{explicit} control of the gap. Our method is as simple and efficient as standard dropout. We further prove the upper bounds on the loss in accuracy due to expectation-linearization, describe classes of input distributions that expectation-linearize easily. Experiments on three image classification benchmark datasets demonstrate that reducing the inference gap can indeed improve the performance consistently.
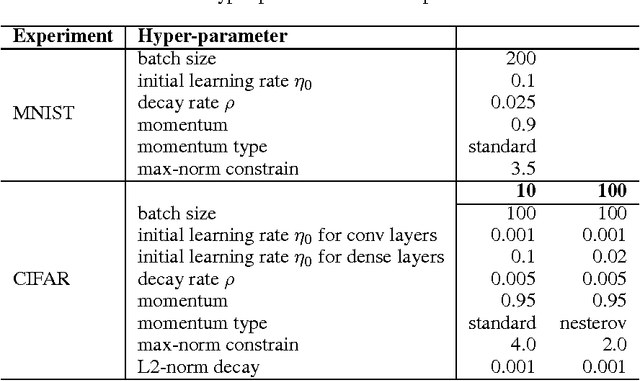
Visualizing and Understanding Curriculum Learning for Long Short-Term Memory Networks
Nov 18, 2016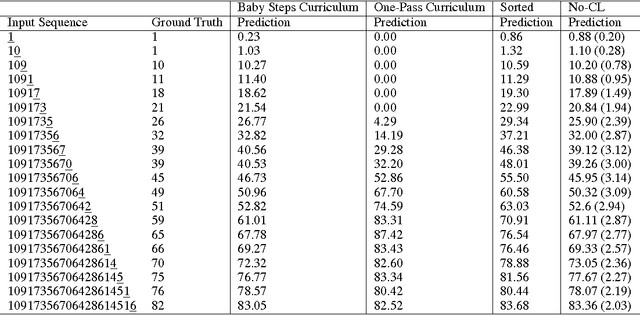
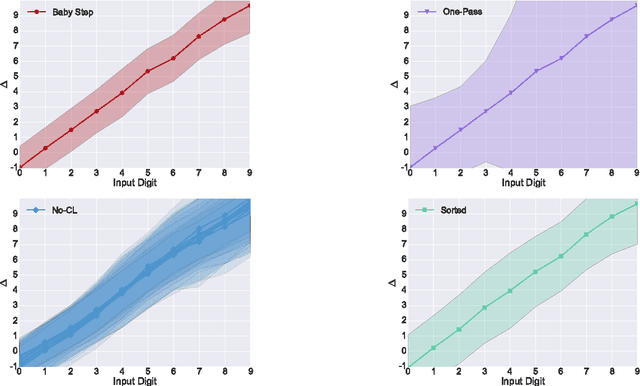

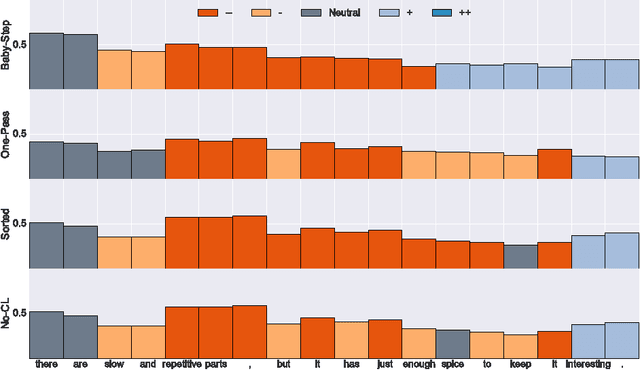
Curriculum Learning emphasizes the order of training instances in a computational learning setup. The core hypothesis is that simpler instances should be learned early as building blocks to learn more complex ones. Despite its usefulness, it is still unknown how exactly the internal representation of models are affected by curriculum learning. In this paper, we study the effect of curriculum learning on Long Short-Term Memory (LSTM) networks, which have shown strong competency in many Natural Language Processing (NLP) problems. Our experiments on sentiment analysis task and a synthetic task similar to sequence prediction tasks in NLP show that curriculum learning has a positive effect on the LSTM's internal states by biasing the model towards building constructive representations i.e. the internal representation at the previous timesteps are used as building blocks for the final prediction. We also find that smaller models significantly improves when they are trained with curriculum learning. Lastly, we show that curriculum learning helps more when the amount of training data is limited.
Harnessing Deep Neural Networks with Logic Rules
Nov 15, 2016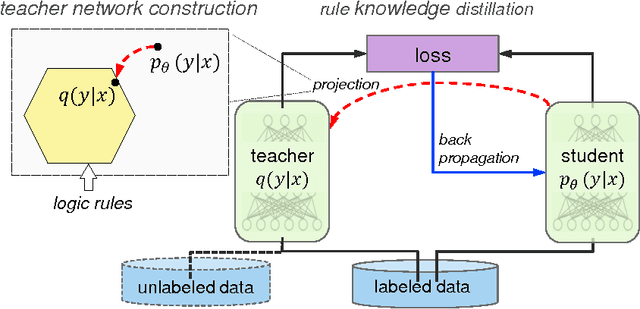
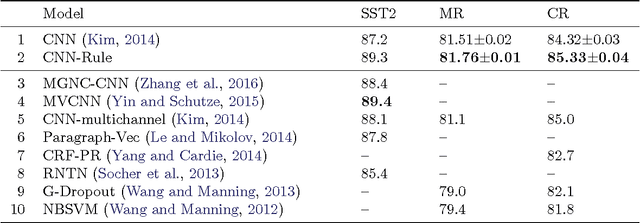
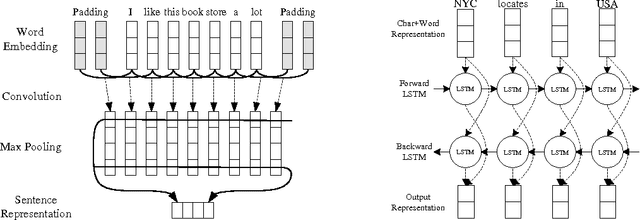
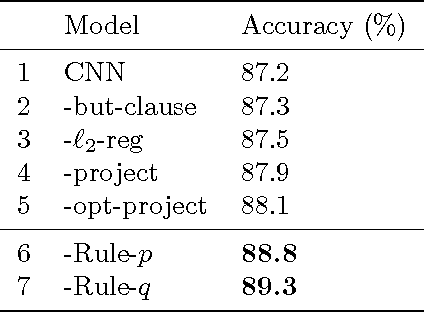
Combining deep neural networks with structured logic rules is desirable to harness flexibility and reduce uninterpretability of the neural models. We propose a general framework capable of enhancing various types of neural networks (e.g., CNNs and RNNs) with declarative first-order logic rules. Specifically, we develop an iterative distillation method that transfers the structured information of logic rules into the weights of neural networks. We deploy the framework on a CNN for sentiment analysis, and an RNN for named entity recognition. With a few highly intuitive rules, we obtain substantial improvements and achieve state-of-the-art or comparable results to previous best-performing systems.
End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF
May 29, 2016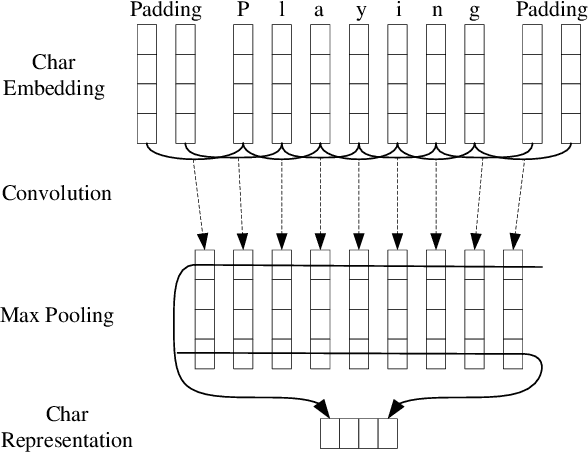
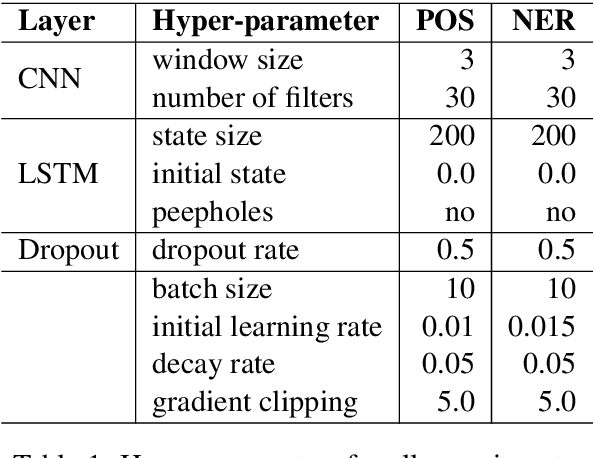
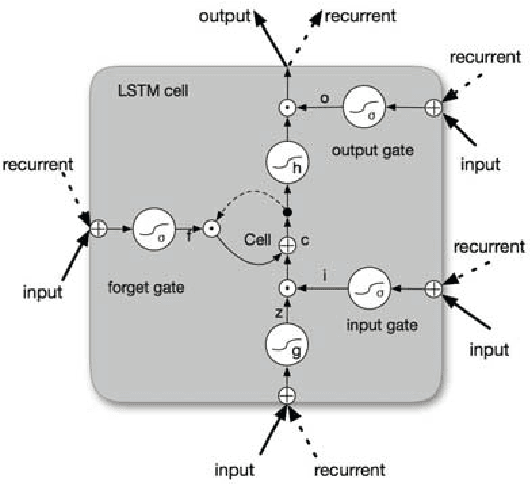
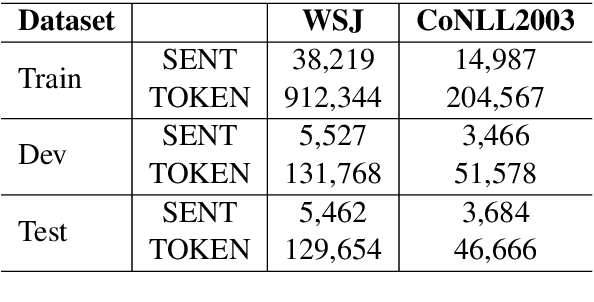
State-of-the-art sequence labeling systems traditionally require large amounts of task-specific knowledge in the form of hand-crafted features and data pre-processing. In this paper, we introduce a novel neutral network architecture that benefits from both word- and character-level representations automatically, by using combination of bidirectional LSTM, CNN and CRF. Our system is truly end-to-end, requiring no feature engineering or data pre-processing, thus making it applicable to a wide range of sequence labeling tasks. We evaluate our system on two data sets for two sequence labeling tasks --- Penn Treebank WSJ corpus for part-of-speech (POS) tagging and CoNLL 2003 corpus for named entity recognition (NER). We obtain state-of-the-art performance on both the two data --- 97.55\% accuracy for POS tagging and 91.21\% F1 for NER.
Unsupervised Ranking Model for Entity Coreference Resolution
Mar 15, 2016
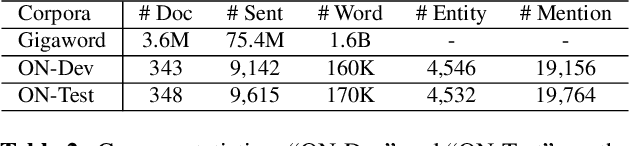
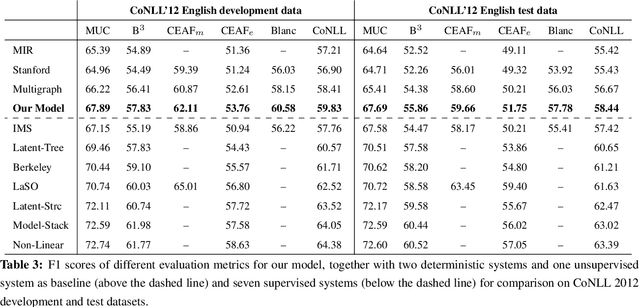
Coreference resolution is one of the first stages in deep language understanding and its importance has been well recognized in the natural language processing community. In this paper, we propose a generative, unsupervised ranking model for entity coreference resolution by introducing resolution mode variables. Our unsupervised system achieves 58.44% F1 score of the CoNLL metric on the English data from the CoNLL-2012 shared task (Pradhan et al., 2012), outperforming the Stanford deterministic system (Lee et al., 2013) by 3.01%.
TabMCQ: A Dataset of General Knowledge Tables and Multiple-choice Questions
Feb 12, 2016
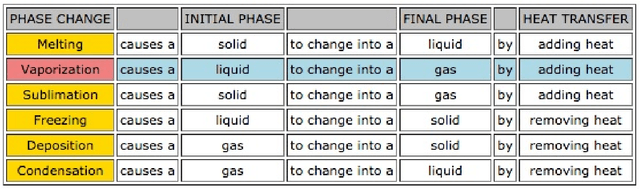

We describe two new related resources that facilitate modelling of general knowledge reasoning in 4th grade science exams. The first is a collection of curated facts in the form of tables, and the second is a large set of crowd-sourced multiple-choice questions covering the facts in the tables. Through the setup of the crowd-sourced annotation task we obtain implicit alignment information between questions and tables. We envisage that the resources will be useful not only to researchers working on question answering, but also to people investigating a diverse range of other applications such as information extraction, question parsing, answer type identification, and lexical semantic modelling.
Visualizing and Understanding Neural Models in NLP
Jan 08, 2016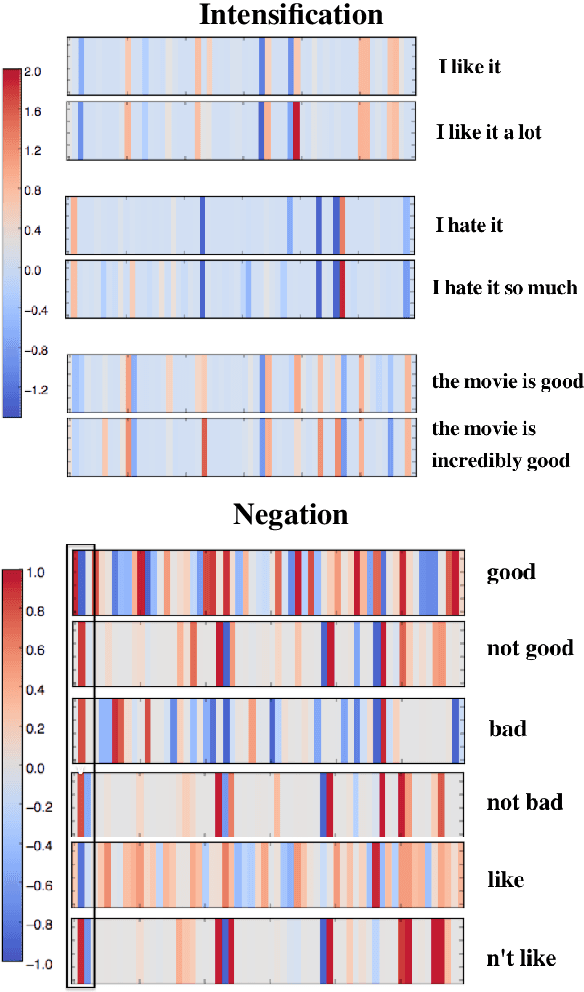
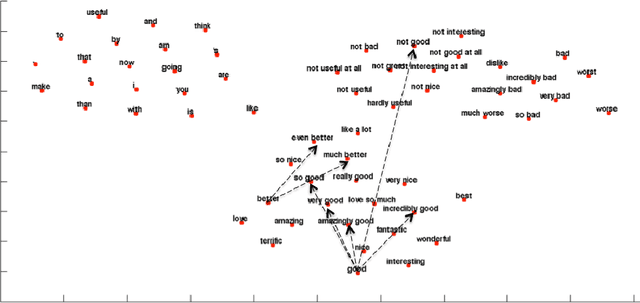
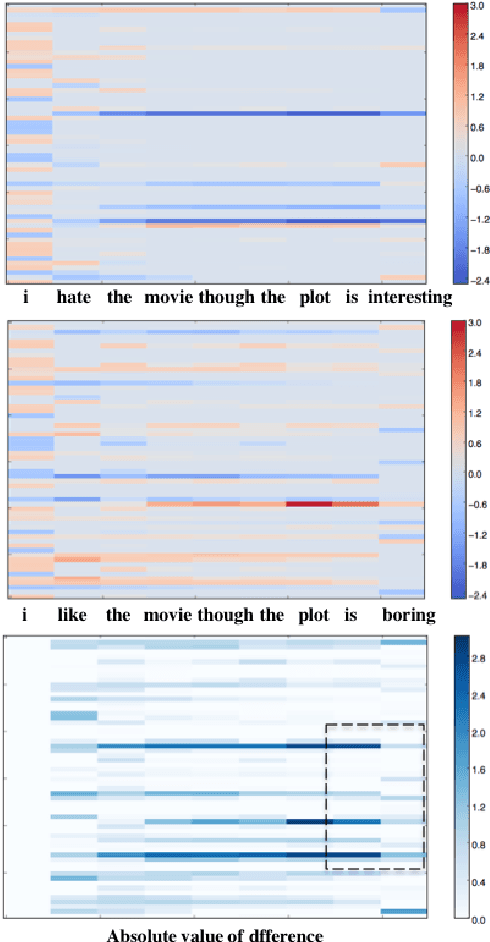

While neural networks have been successfully applied to many NLP tasks the resulting vector-based models are very difficult to interpret. For example it's not clear how they achieve {\em compositionality}, building sentence meaning from the meanings of words and phrases. In this paper we describe four strategies for visualizing compositionality in neural models for NLP, inspired by similar work in computer vision. We first plot unit values to visualize compositionality of negation, intensification, and concessive clauses, allow us to see well-known markedness asymmetries in negation. We then introduce three simple and straightforward methods for visualizing a unit's {\em salience}, the amount it contributes to the final composed meaning: (1) gradient back-propagation, (2) the variance of a token from the average word node, (3) LSTM-style gates that measure information flow. We test our methods on sentiment using simple recurrent nets and LSTMs. Our general-purpose methods may have wide applications for understanding compositionality and other semantic properties of deep networks , and also shed light on why LSTMs outperform simple recurrent nets,
Reflections on Sentiment/Opinion Analysis
Jul 06, 2015
In this paper, we described possible directions for deeper understanding, helping bridge the gap between psychology / cognitive science and computational approaches in sentiment/opinion analysis literature. We focus on the opinion holder's underlying needs and their resultant goals, which, in a utilitarian model of sentiment, provides the basis for explaining the reason a sentiment valence is held. While these thoughts are still immature, scattered, unstructured, and even imaginary, we believe that these perspectives might suggest fruitful avenues for various kinds of future work.