 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-Adaptive Transformer
Oct 22, 2019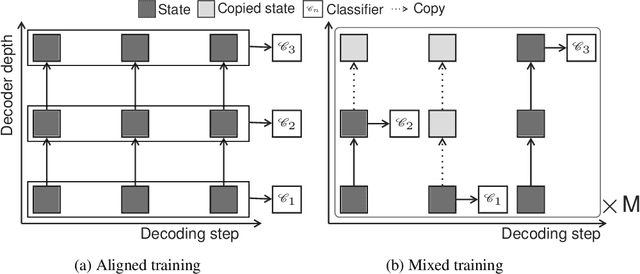
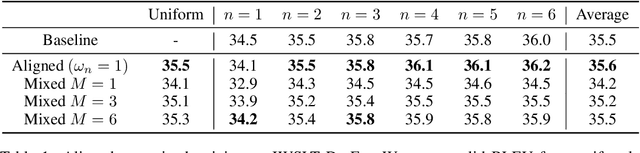
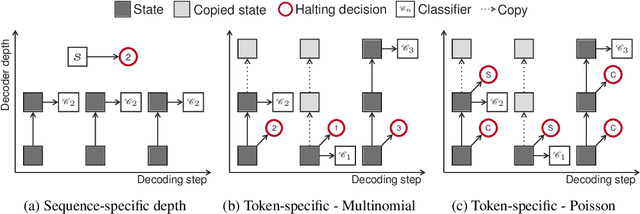
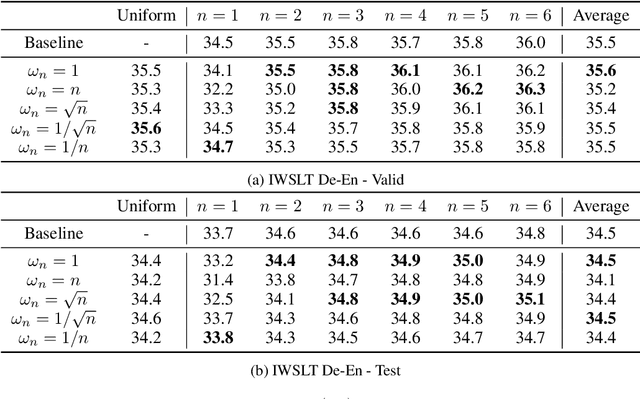
State of the art sequence-to-sequence models perform a fixed number of computations for each input sequence regardless of whether it is easy or hard to process. In this paper, we train Transformer models which can make output predictions at different stages of the network and we investigate different ways to predict how much computation is required for a particular sequence. Unlike dynamic computation in Universal Transformers, which applies the same set of layers iteratively, we apply different layers at every step to adjust both the amount of computation as well as the model capacity. Experiments on machine translation benchmarks show that this approach can match the accuracy of a baseline Transformer while using only half the number of decoder layers.
Updating Pre-trained Word Vectors and Text Classifiers using Monolingual Alignment
Oct 15, 2019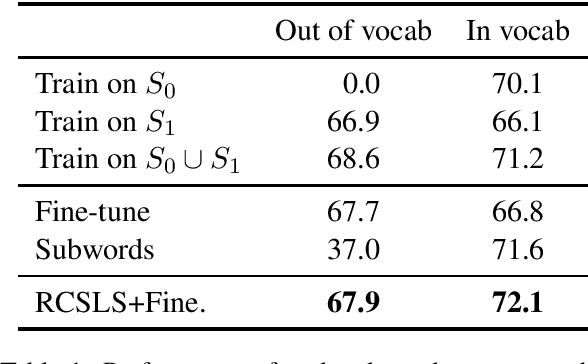
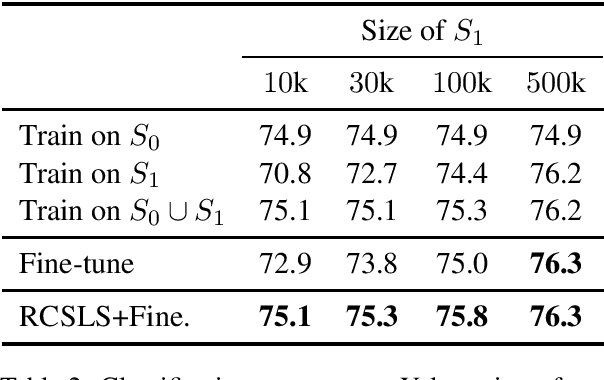
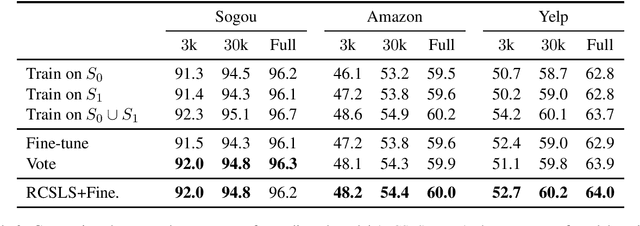
In this paper, we focus on the problem of adapting word vector-based models to new textual data. Given a model pre-trained on large reference data, how can we adapt it to a smaller piece of data with a slightly different language distribution? We frame the adaptation problem as a monolingual word vector alignment problem, and simply average models after alignment. We align vectors using the RCSLS criterion. Our formulation results in a simple and efficient algorithm that allows adapting general-purpose models to changing word distributions. In our evaluation, we consider applications to word embedding and text classification models. We show that the proposed approach yields good performance in all setups and outperforms a baseline consisting in fine-tuning the model on new data.
Reducing Transformer Depth on Demand with Structured Dropout
Sep 25, 2019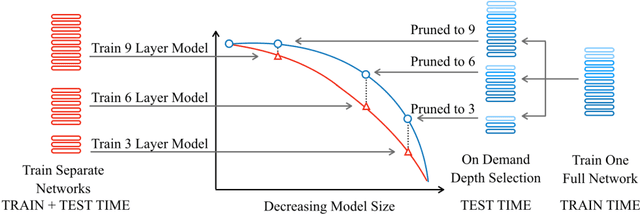
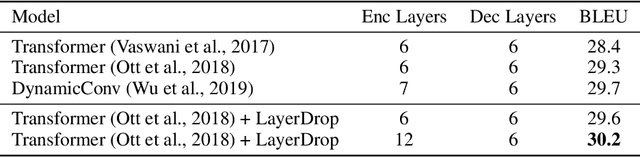

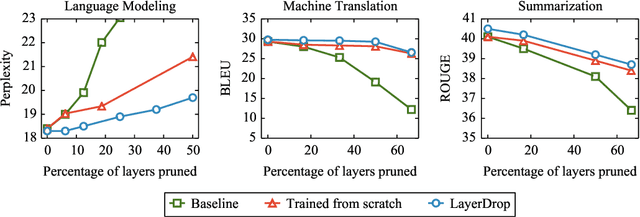
Overparameterized transformer networks have obtained state of the art results in various natural language processing tasks, such as machine translation, language modeling, and question answering. These models contain hundreds of millions of parameters, necessitating a large amount of computation and making them prone to overfitting. In this work, we explore LayerDrop, a form of structured dropout, which has a regularization effect during training and allows for efficient pruning at inference time. In particular, we show that it is possible to select sub-networks of any depth from one large network without having to finetune them and with limited impact on performance. We demonstrate the effectiveness of our approach by improving the state of the art on machine translation, language modeling, summarization, question answering, and language understanding benchmarks. Moreover, we show that our approach leads to small BERT-like models of higher quality compared to training from scratch or using distillation.
Don't Forget the Long Tail! A Comprehensive Analysis of Morphological Generalization in Bilingual Lexicon Induction
Sep 06, 2019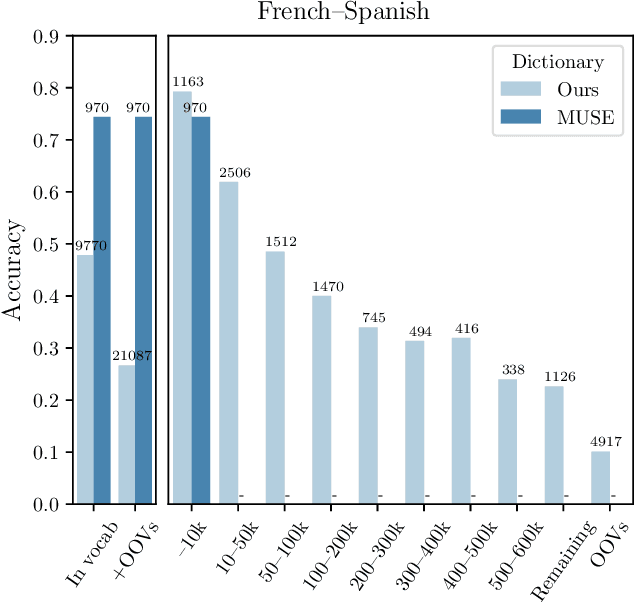
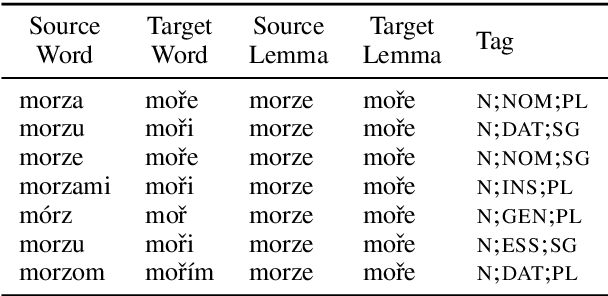

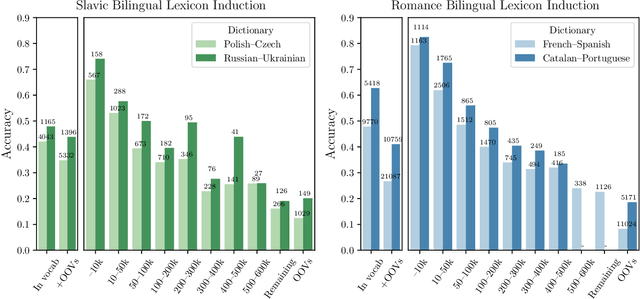
Human translators routinely have to translate rare inflections of words - due to the Zipfian distribution of words in a language. When translating from Spanish, a good translator would have no problem identifying the proper translation of a statistically rare inflection such as habl\'aramos. Note the lexeme itself, hablar, is relatively common. In this work, we investigate whether state-of-the-art bilingual lexicon inducers are capable of learning this kind of generalization. We introduce 40 morphologically complete dictionaries in 10 languages and evaluate three of the state-of-the-art models on the task of translation of less frequent morphological forms. We demonstrate that the performance of state-of-the-art models drops considerably when evaluated on infrequent morphological inflections and then show that adding a simple morphological constraint at training time improves the performance, proving that the bilingual lexicon inducers can benefit from better encoding of morphology.
Augmenting Self-attention with Persistent Memory
Jul 02, 2019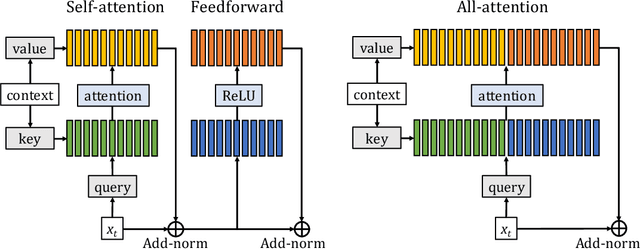
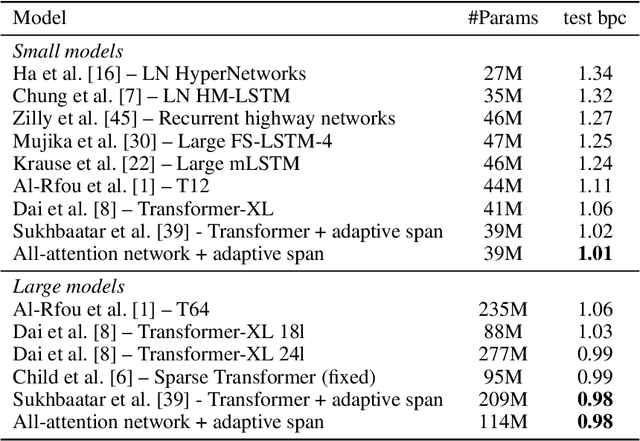

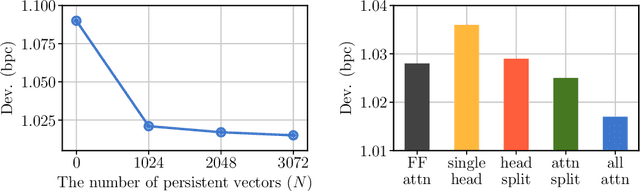
Transformer networks have lead to important progress in language modeling and machine translation. These models include two consecutive modules, a feed-forward layer and a self-attention layer. The latter allows the network to capture long term dependencies and are often regarded as the key ingredient in the success of Transformers. Building upon this intuition, we propose a new model that solely consists of attention layers. More precisely, we augment the self-attention layers with persistent memory vectors that play a similar role as the feed-forward layer. Thanks to these vectors, we can remove the feed-forward layer without degrading the performance of a transformer. Our evaluation shows the benefits brought by our model on standard character and word level language modeling benchmarks.
Misspelling Oblivious Word Embeddings
May 23, 2019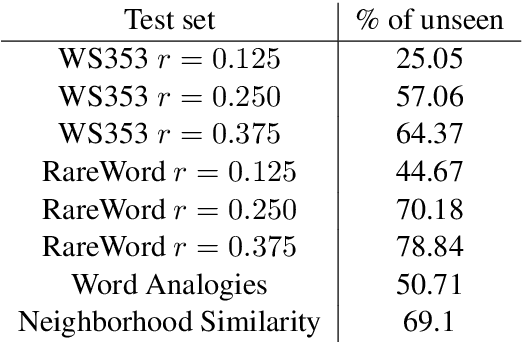
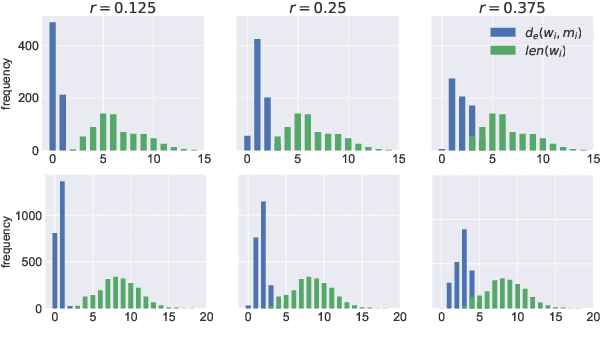
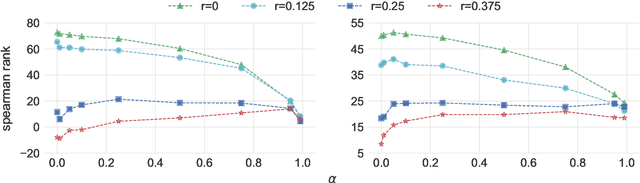
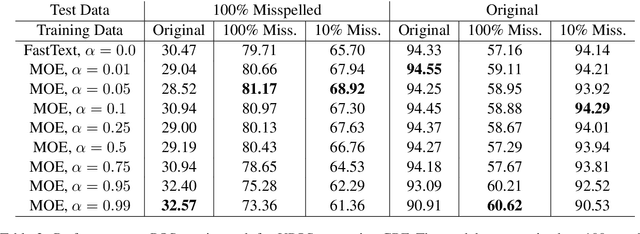
In this paper we present a method to learn word embeddings that are resilient to misspellings. Existing word embeddings have limited applicability to malformed texts, which contain a non-negligible amount of out-of-vocabulary words. We propose a method combining FastText with subwords and a supervised task of learning misspelling patterns. In our method, misspellings of each word are embedded close to their correct variants. We train these embeddings on a new dataset we are releasing publicly. Finally, we experimentally show the advantages of this approach on both intrinsic and extrinsic NLP tasks using public test sets.
Adaptive Attention Span in Transformers
May 19, 2019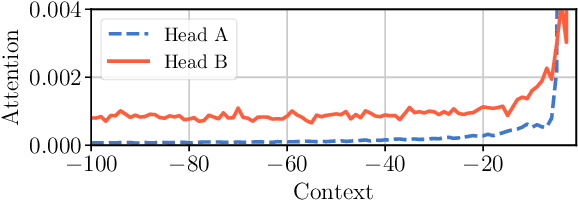
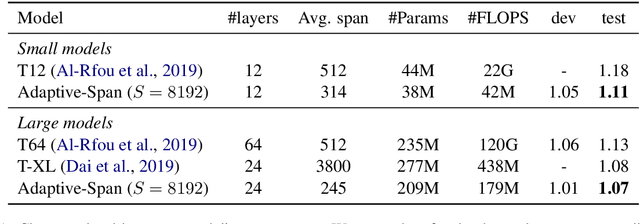
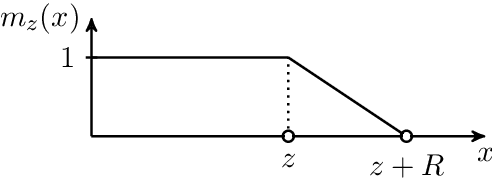
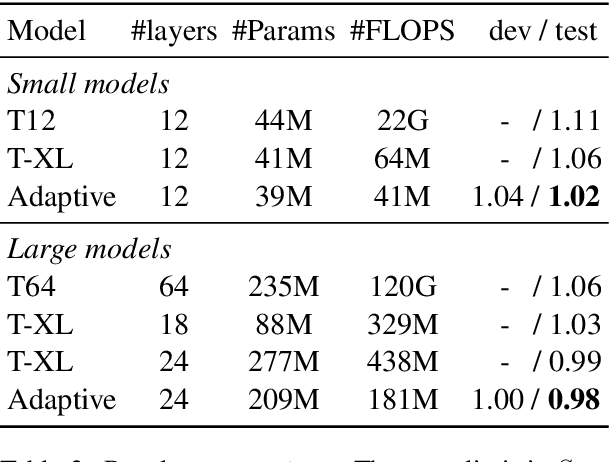
We propose a novel self-attention mechanism that can learn its optimal attention span. This allows us to extend significantly the maximum context size used in Transformer, while maintaining control over their memory footprint and computational time. We show the effectiveness of our approach on the task of character level language modeling, where we achieve state-of-the-art performances on text8 and enwiki8 by using a maximum context of 8k characters.
Looking for ELMo's friends: Sentence-Level Pretraining Beyond Language Modeling
Dec 28, 2018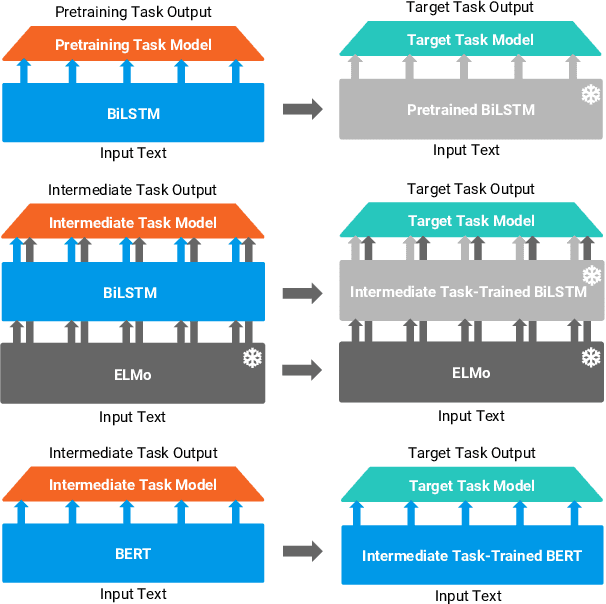
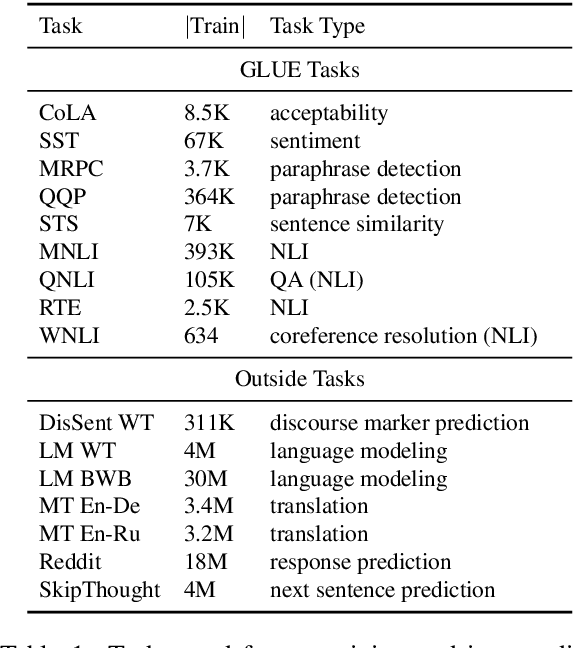
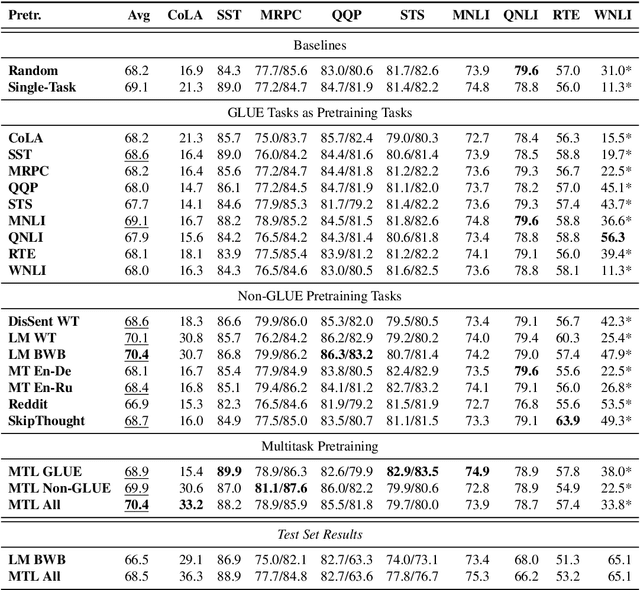
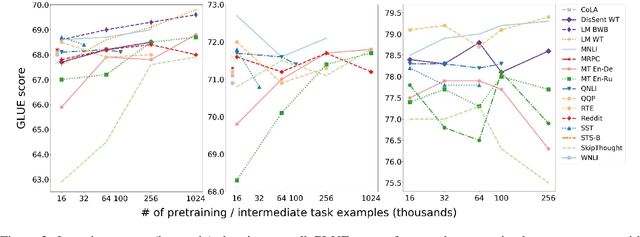
Work on the problem of contextualized word representation -- the development of reusable neural network components for sentence understanding -- has recently seen a surge of progress centered on the unsupervised pretraining task of language modeling with methods like ELMo. This paper contributes the first large-scale systematic study comparing different pretraining tasks in this context, both as complements to language modeling and as potential alternatives. The primary results of the study support the use of language modeling as a pretraining task and set a new state of the art among comparable models using multitask learning with language models. However, a closer look at these results reveals worryingly strong baselines and strikingly varied results across target tasks, suggesting that the widely-used paradigm of pretraining and freezing sentence encoders may not be an ideal platform for further work.
Unsupervised Hyperalignment for Multilingual Word Embeddings
Nov 02, 2018

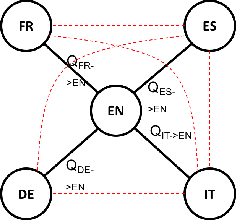
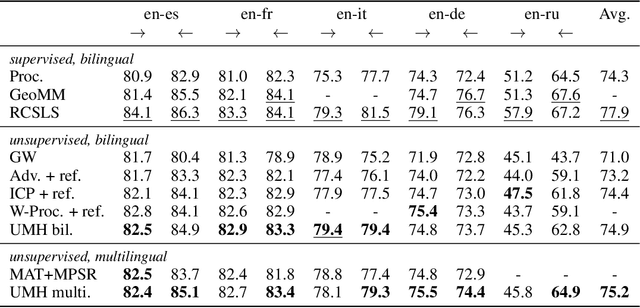
We consider the problem of aligning continuous word representations, learned in multiple languages, to a common space. It was recently shown that, in the case of two languages, it is possible to learn such a mapping without supervision. This paper extends this line of work to the problem of aligning multiple languages to a common space. A solution is to independently map all languages to a pivot language. Unfortunately, this degrades the quality of indirect word translation. We thus propose a novel formulation that ensures composable mappings, leading to better alignments. We evaluate our method by jointly aligning word vectors in eleven languages, showing consistent improvement with indirect mappings while maintaining competitive performance on direct word translation.
Lightweight Adaptive Mixture of Neural and N-gram Language Models
Oct 26, 2018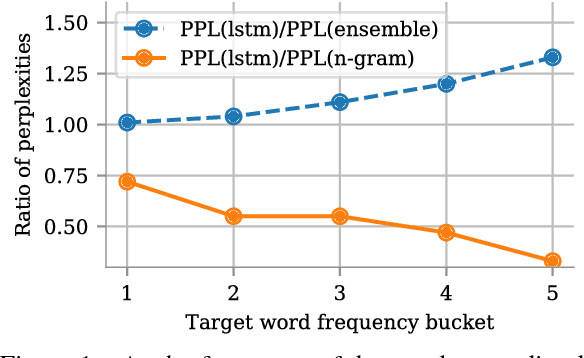

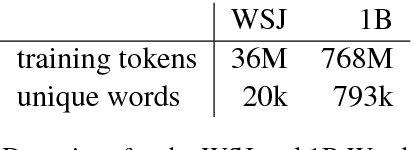
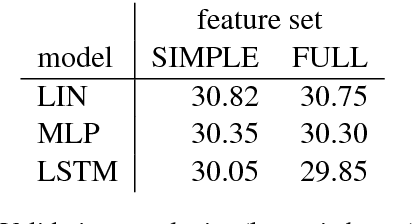
It is often the case that the best performing language model is an ensemble of a neural language model with n-grams. In this work, we propose a method to improve how these two models are combined. By using a small network which predicts the mixture weight between the two models, we adapt their relative importance at each time step. Because the gating network is small, it trains quickly on small amounts of held out data, and does not add overhead at scoring time. Our experiments carried out on the One Billion Word benchmark show a significant improvement over the state of the art ensemble without retraining of the basic modules.