 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Knowledge from Reader to Retriever for Question Answering
Dec 08, 2020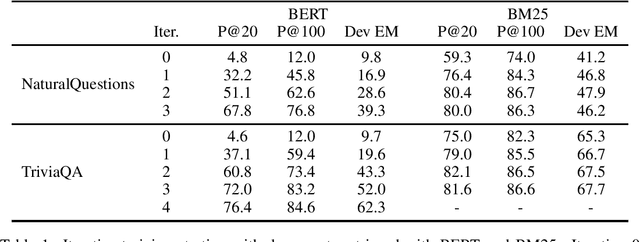
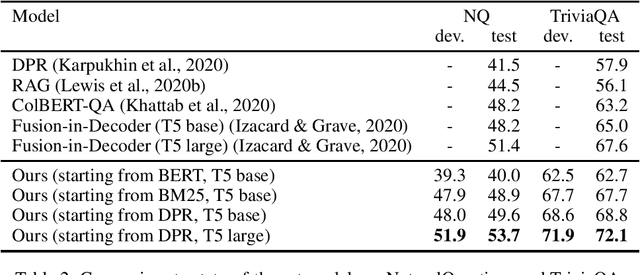
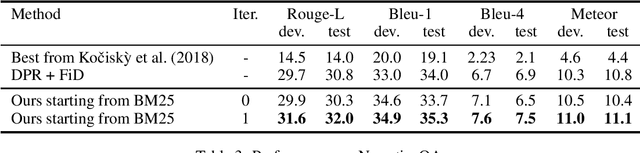
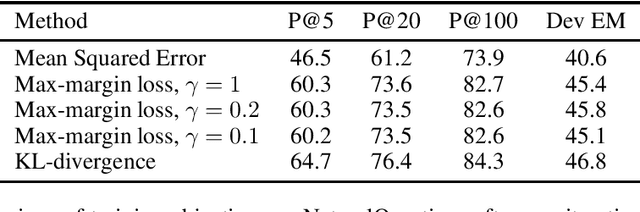
The task of information retrieval is an important component of many natural language processing systems, such as open domain question answering. While traditional methods were based on hand-crafted features, continuous representations based on neural networks recently obtained competitive results. A challenge of using such methods is to obtain supervised data to train the retriever model, corresponding to pairs of query and support documents. In this paper, we propose a technique to learn retriever models for downstream tasks, inspired by knowledge distillation, and which does not require annotated pairs of query and documents. Our approach leverages attention scores of a reader model, used to solve the task based on retrieved documents, to obtain synthetic labels for the retriever. We evaluate our method on question answering, obtaining state-of-the-art results.
Beyond English-Centric Multilingual Machine Translation
Oct 21, 2020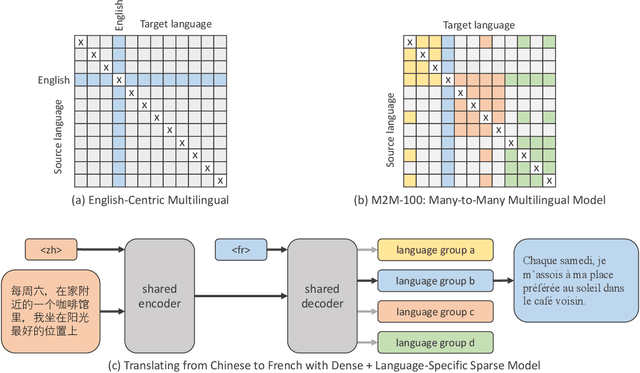

Existing work in translation demonstrated the potential of massively multilingual machine translation by training a single model able to translate between any pair of languages. However, much of this work is English-Centric by training only on data which was translated from or to English. While this is supported by large sources of training data, it does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation model that can translate directly between any pair of 100 languages. We build and open source a training dataset that covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly translating between non-English directions while performing competitively to the best single systems of WMT. We open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.
Self-training Improves Pre-training for Natural Language Understanding
Oct 05, 2020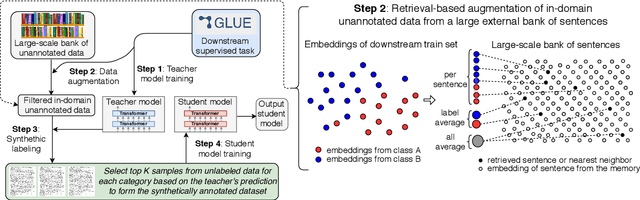
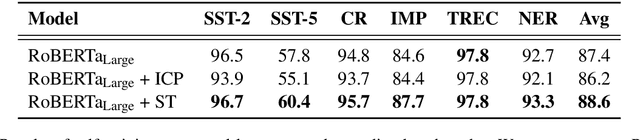

Unsupervised pre-training has led to much recent progress in natural language understanding. In this paper, we study self-training as another way to leverage unlabeled data through semi-supervised learning. To obtain additional data for a specific task, we introduce SentAugment, a data augmentation method which computes task-specific query embeddings from labeled data to retrieve sentences from a bank of billions of unlabeled sentences crawled from the web. Unlike previous semi-supervised methods, our approach does not require in-domain unlabeled data and is therefore more generally applicable. Experiments show that self-training is complementary to strong RoBERTa baselines on a variety of tasks. Our augmentation approach leads to scalable and effective self-training with improvements of up to 2.6% on standard text classification benchmarks. Finally, we also show strong gains on knowledge-distillation and few-shot learning.
Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering
Jul 02, 2020


Generative models for open domain question answering have proven to be competitive, without resorting to external knowledge. While promising, this approach requires to use models with billions of parameters, which are expensive to train and query. In this paper, we investigate how much these models can benefit from retrieving text passages, potentially containing evidence. We obtain state-of-the-art results on the Natural Questions and TriviaQA open benchmarks. Interestingly, we observe that the performance of this method significantly improves when increasing the number of retrieved passages. This is evidence that generative models are good at aggregating and combining evidence from multiple passages.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
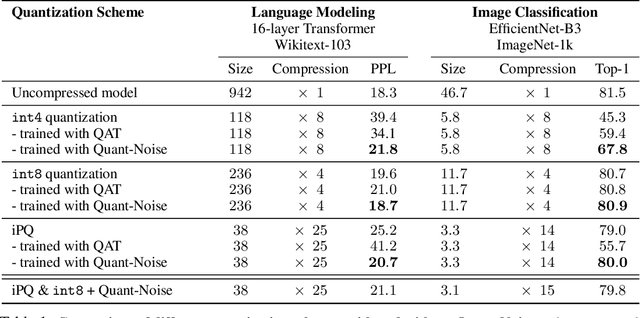
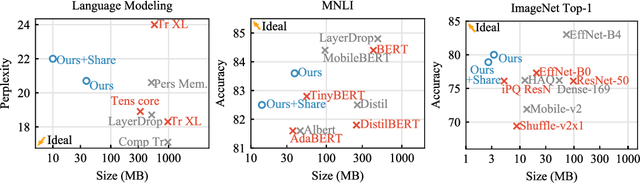
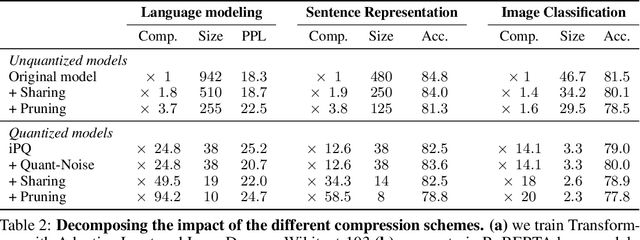
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
Accessing Higher-level Representations in Sequential Transformers with Feedback Memory
Mar 09, 2020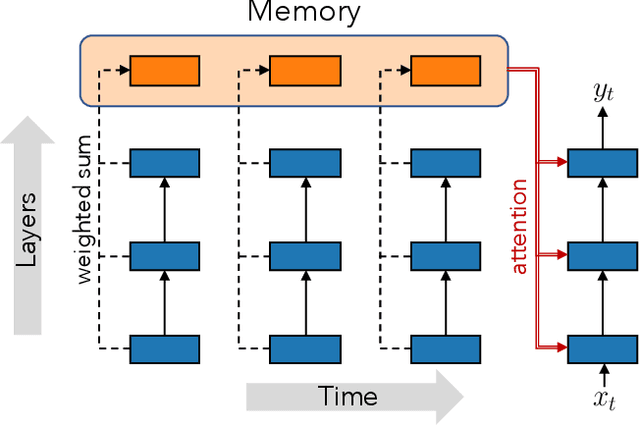
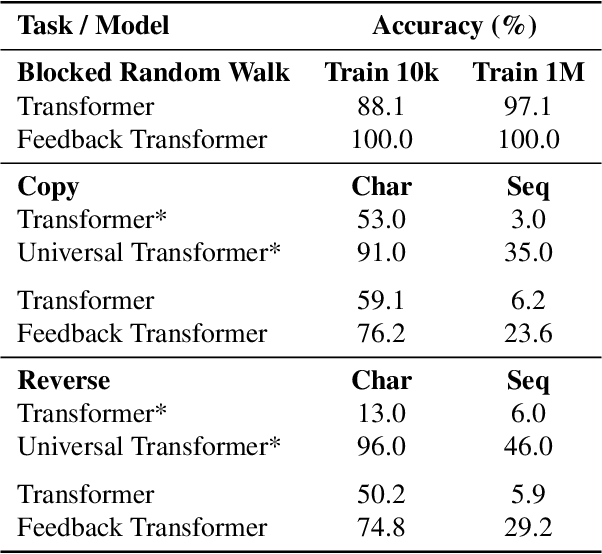
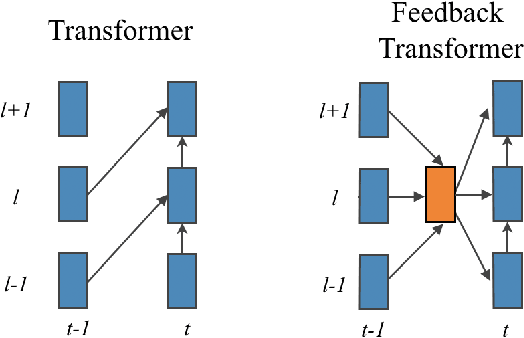
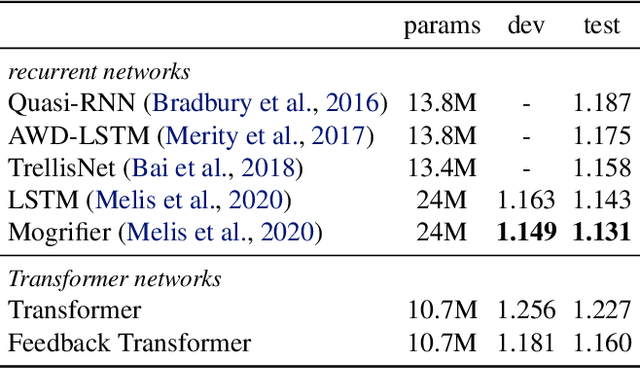
Transformers are feedforward networks that can process input tokens in parallel. While this parallelization makes them computationally efficient, it restricts the model from fully exploiting the sequential nature of the input - the representation at a given layer can only access representations from lower layers, rather than the higher level representations already built in previous time steps. In this work, we propose the Feedback Transformer architecture that exposes all previous representations to all future representations, meaning the lowest representation of the current timestep is formed from the highest-level abstract representation of the past. We demonstrate on a variety of benchmarks in language modeling, neural machine translation, summarization, and reinforcement learning that the increased representation capacity can improve over Transformer baselines.
End-to-end ASR: from Supervised to Semi-Supervised Learning with Modern Architectures
Nov 19, 2019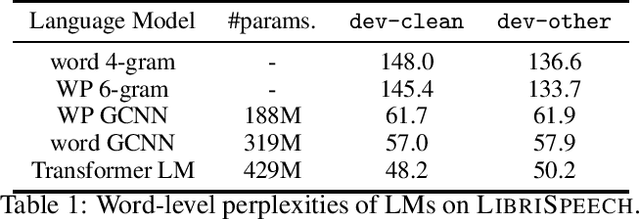
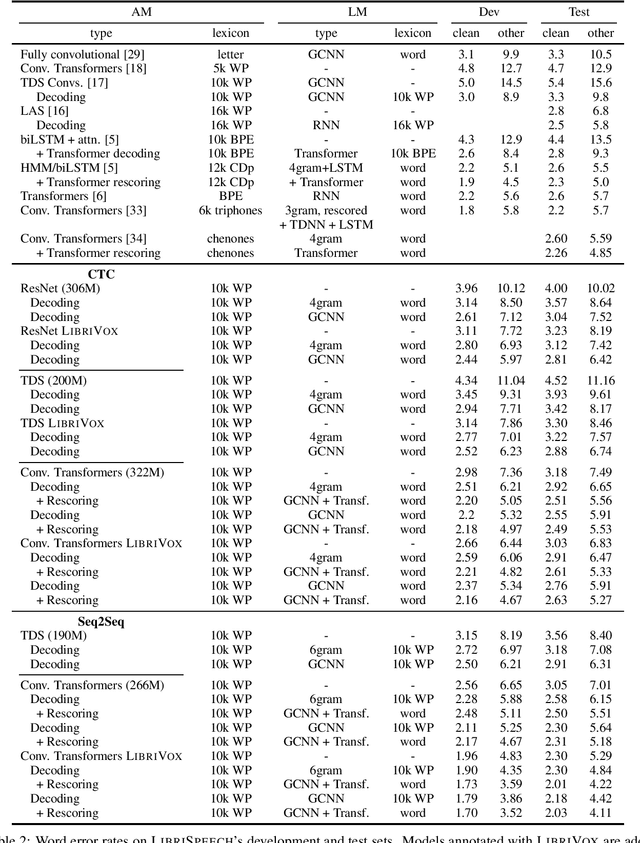
We study ResNet-, Time-Depth Separable ConvNets-, and Transformer-based acoustic models, trained with CTC or Seq2Seq criterions. We perform experiments on the LibriSpeech dataset, with and without LM decoding, optionally with beam rescoring. We reach 5.18% WER with external language models for decoding and rescoring. Additionally, we leverage the unlabeled data from LibriVox by doing semi-supervised training and show that it is possible to reach 5.29% WER on test-other without decoding, and 4.11% WER with decoding and rescoring, with only the standard 960 hours from LibriSpeech as labeled data.
CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data
Nov 15, 2019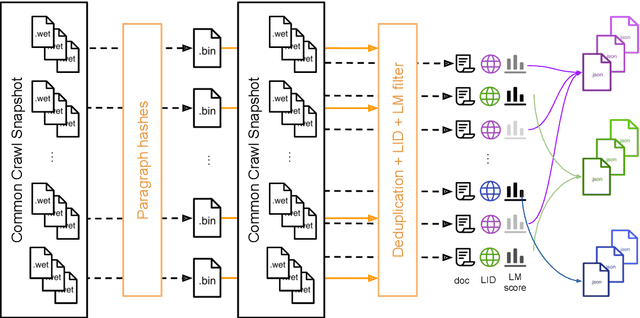
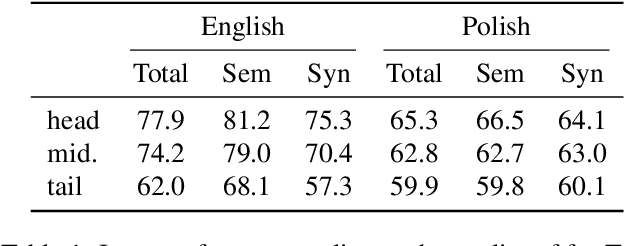
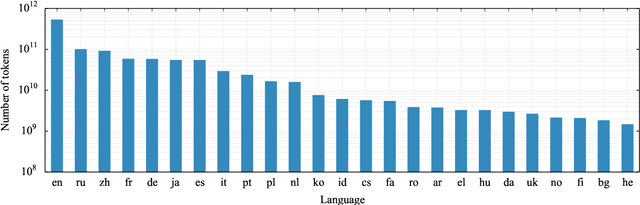
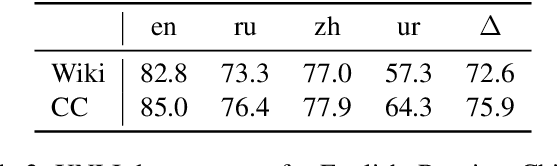
Pre-training text representations have led to significant improvements in many areas of natural language processing. The quality of these models benefits greatly from the size of the pretraining corpora as long as its quality is preserved. In this paper, we describe an automatic pipeline to extract massive high-quality monolingual datasets from Common Crawl for a variety of languages. Our pipeline follows the data processing introduced in fastText (Mikolov et al., 2017; Grave et al., 2018), that deduplicates documents and identifies their language. We augment this pipeline with a filtering step to select documents that are close to high quality corpora like Wikipedia.
CCMatrix: Mining Billions of High-Quality Parallel Sentences on the WEB
Nov 10, 2019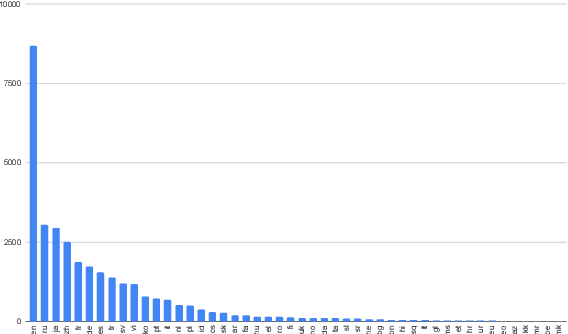
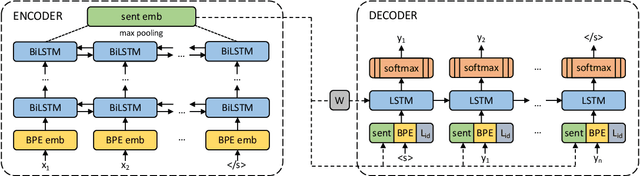
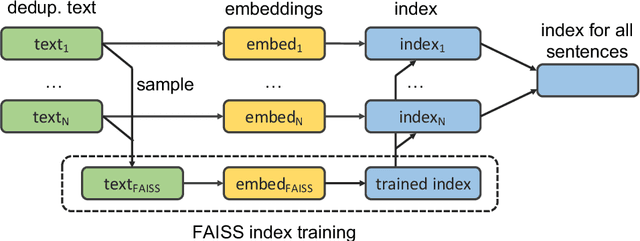
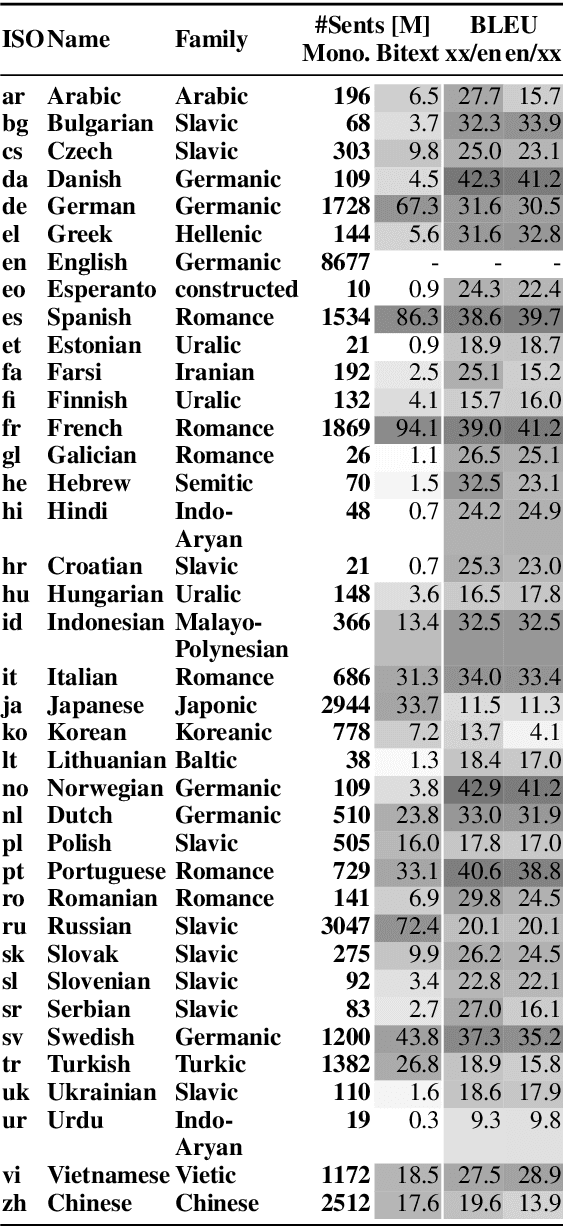
We show that margin-based bitext mining in a multilingual sentence space can be applied to monolingual corpora of billions of sentences. We are using ten snapshots of a curated common crawl corpus (Wenzek et al., 2019) totaling 32.7 billion unique sentences. Using one unified approach for 38 languages, we were able to mine 3.5 billions parallel sentences, out of which 661 million are aligned with English. 17 language pairs have more then 30 million parallel sentences, 82 more then 10 million, and most more than one million, including direct alignments between many European or Asian languages. To evaluate the quality of the mined bitexts, we train NMT systems for most of the language pairs and evaluate them on TED, WMT and WAT test sets. Using our mined bitexts only and no human translated parallel data, we achieve a new state-of-the-art for a single system on the WMT'19 test set for translation between English and German, Russian and Chinese, as well as German/French. In particular, our English/German system outperforms the best single one by close to 4 BLEU points and is almost on pair with best WMT'19 evaluation system which uses system combination and back-translation. We also achieve excellent results for distant languages pairs like Russian/Japanese, outperforming the best submission at the 2019 workshop on Asian Translation (WAT).
Unsupervised Cross-lingual Representation Learning at Scale
Nov 05, 2019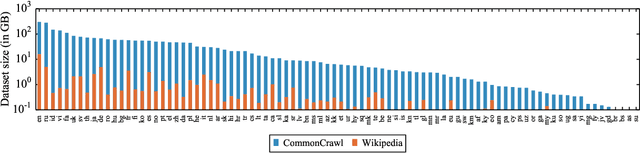
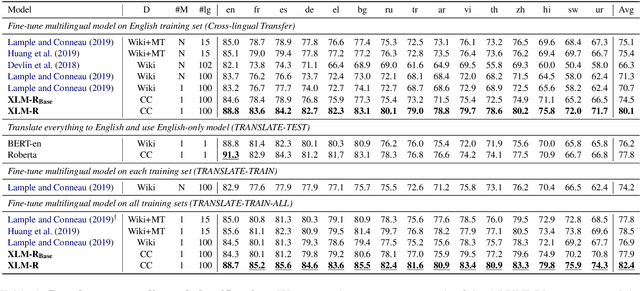
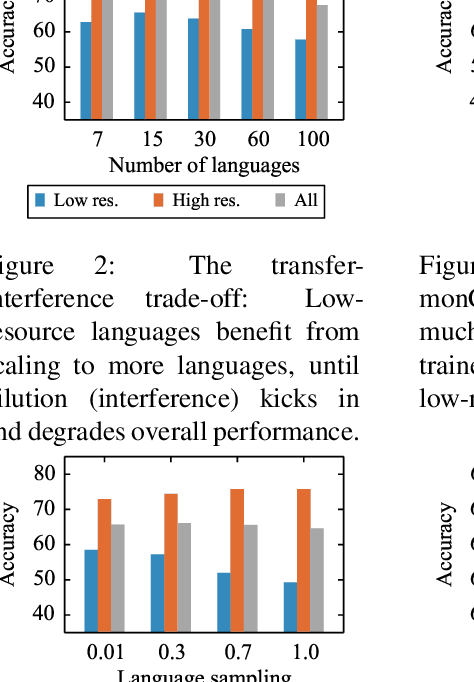
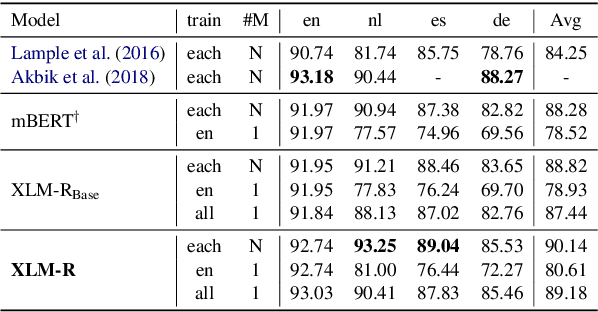
This paper shows that pretraining multilingual language models at scale leads to significant performance gains for a wide range of cross-lingual transfer tasks. We train a Transformer-based masked language model on one hundred languages, using more than two terabytes of filtered CommonCrawl data. Our model, dubbed XLM-R, significantly outperforms multilingual BERT (mBERT) on a variety of cross-lingual benchmarks, including +13.8% average accuracy on XNLI, +12.3% average F1 score on MLQA, and +2.1% average F1 score on NER. XLM-R performs particularly well on low-resource languages, improving 11.8% in XNLI accuracy for Swahili and 9.2% for Urdu over the previous XLM model. We also present a detailed empirical evaluation of the key factors that are required to achieve these gains, including the trade-offs between (1) positive transfer and capacity dilution and (2) the performance of high and low resource languages at scale. Finally, we show, for the first time, the possibility of multilingual modeling without sacrificing per-language performance; XLM-Ris very competitive with strong monolingual models on the GLUE and XNLI benchmarks. We will make XLM-R code, data, and models publicly available.