 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounds for Approximate Regret-Matching Algorithms
Oct 03, 2019A dominant approach to solving large imperfect-information games is Counterfactural Regret Minimization (CFR). In CFR, many regret minimization problems are combined to solve the game. For very large games, abstraction is typically needed to render CFR tractable. Abstractions are often manually tuned, possibly removing important strategic differences in the full game and harming performance. Function approximation provides a natural solution to finding good abstractions to approximate the full game. A common approach to incorporating function approximation is to learn the inputs needed for a regret minimizing algorithm, allowing for generalization across many regret minimization problems. This paper gives regret bounds when a regret minimizing algorithm uses estimates instead of true values. This form of analysis is the first to generalize to a larger class of $(\Phi, f)$-regret matching algorithms, and includes different forms of regret such as swap, internal, and external regret. We demonstrate how these results give a slightly tighter bound for Regression Regret-Matching (RRM), and present a novel bound for combining regression with Hedge.
* 4 pages + acknowledgements, references, and appendices (9 pages total)
Neural Replicator Dynamics
Jun 01, 2019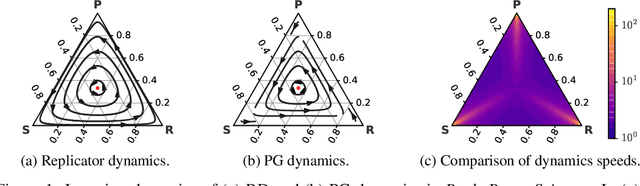

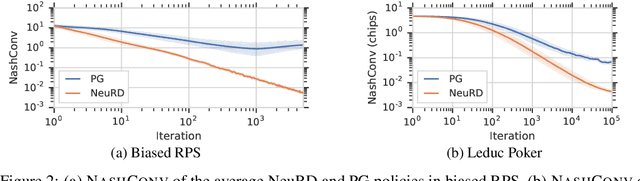
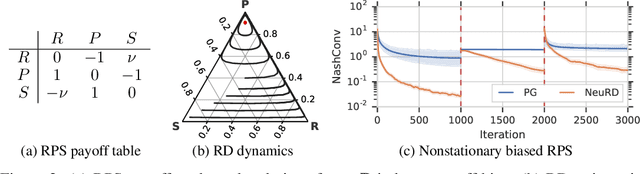
In multiagent learning, agents interact in inherently nonstationary environments due to their concurrent policy updates. It is, therefore, paramount to develop and analyze algorithms that learn effectively despite these nonstationarities. A number of works have successfully conducted this analysis under the lens of evolutionary game theory (EGT), wherein a population of individuals interact and evolve based on biologically-inspired operators. These studies have mainly focused on establishing connections to value-iteration based approaches in stateless or tabular games. We extend this line of inquiry to formally establish links between EGT and policy gradient (PG) methods, which have been extensively applied in single and multiagent learning. We pinpoint weaknesses of the commonly-used softmax PG algorithm in adversarial and nonstationary settings and contrast PG's behavior to that predicted by replicator dynamics (RD), a central model in EGT. We consequently provide theoretical results that establish links between EGT and PG methods, then derive Neural Replicator Dynamics (NeuRD), a parameterized version of RD that constitutes a novel method with several advantages. First, as NeuRD reduces to the well-studied no-regret Hedge algorithm in the tabular setting, it inherits no-regret guarantees that enable convergence to equilibria in games. Second, NeuRD is shown to be more adaptive to nonstationarity, in comparison to PG, when learning in canonical games and imperfect information benchmarks including Poker. Thirdly, modifying any PG-based algorithm to use the NeuRD update rule is straightforward and incurs no added computational costs. Finally, while single-agent learning is not the main focus of the paper, we verify empirically that NeuRD is competitive in these settings with a recent baseline algorithm.
Computing Approximate Equilibria in Sequential Adversarial Games by Exploitability Descent
Mar 21, 2019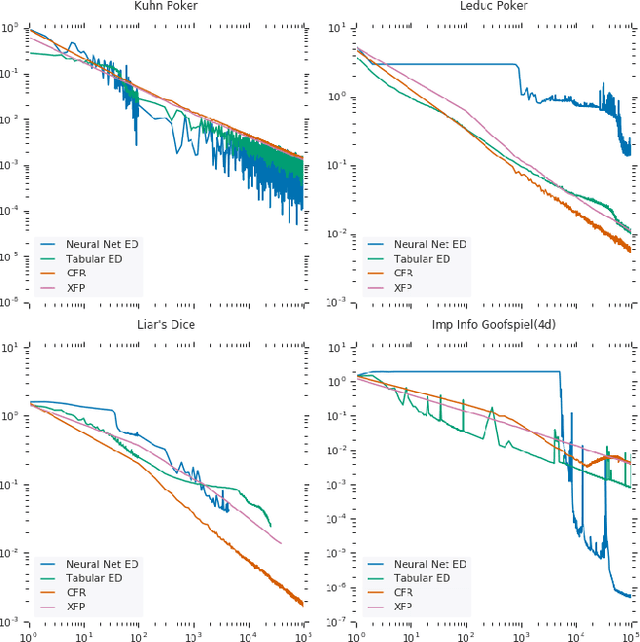
In this paper, we present exploitability descent, a new algorithm to compute approximate equilibria in two-player zero-sum extensive-form games with imperfect information, by direct policy optimization against worst-case opponents. We prove that when following this optimization, the exploitability of a player's strategy converges asymptotically to zero, and hence when both players employ this optimization, the joint policies converge to a Nash equilibrium. Unlike fictitious play (XFP) and counterfactual regret minimization (CFR), our convergence result pertains to the policies being optimized rather than the average policies. Our experiments demonstrate convergence rates comparable to XFP and CFR in four benchmark games in the tabular case. Using function approximation, we find that our algorithm outperforms the tabular version in two of the games, which, to the best of our knowledge, is the first such result in imperfect information games among this class of algorithms.
DeepStack: Expert-Level Artificial Intelligence in No-Limit Poker
Mar 03, 2017Artificial intelligence has seen several breakthroughs in recent years, with games often serving as milestones. A common feature of these games is that players have perfect information. Poker is the quintessential game of imperfect information, and a longstanding challenge problem in artificial intelligence. We introduce DeepStack, an algorithm for imperfect information settings. It combines recursive reasoning to handle information asymmetry, decomposition to focus computation on the relevant decision, and a form of intuition that is automatically learned from self-play using deep learning. In a study involving 44,000 hands of poker, DeepStack defeated with statistical significance professional poker players in heads-up no-limit Texas hold'em. The approach is theoretically sound and is shown to produce more difficult to exploit strategies than prior approaches.
Solving Games with Functional Regret Estimation
Dec 31, 2014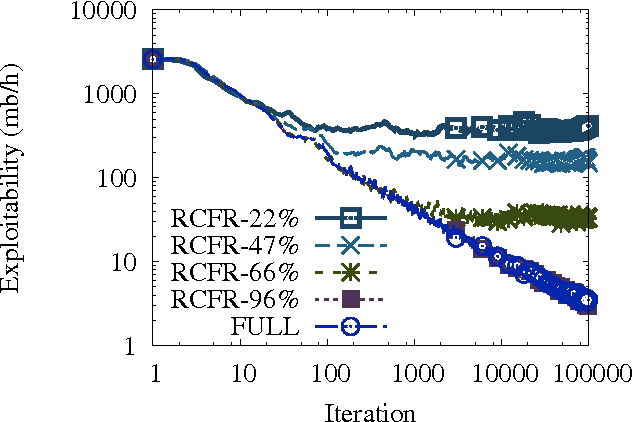
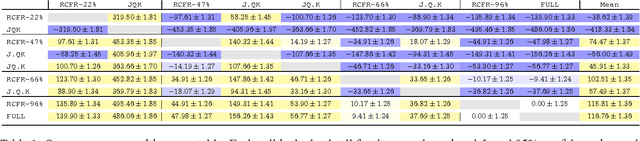
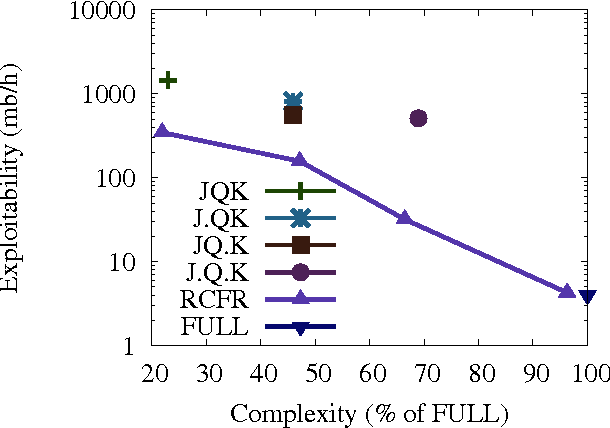
We propose a novel online learning method for minimizing regret in large extensive-form games. The approach learns a function approximator online to estimate the regret for choosing a particular action. A no-regret algorithm uses these estimates in place of the true regrets to define a sequence of policies. We prove the approach sound by providing a bound relating the quality of the function approximation and regret of the algorithm. A corollary being that the method is guaranteed to converge to a Nash equilibrium in self-play so long as the regrets are ultimately realizable by the function approximator. Our technique can be understood as a principled generalization of existing work on abstraction in large games; in our work, both the abstraction as well as the equilibrium are learned during self-play. We demonstrate empirically the method achieves higher quality strategies than state-of-the-art abstraction techniques given the same resources.