 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Text-to-SQL Evaluation Methodology
Jun 23, 2018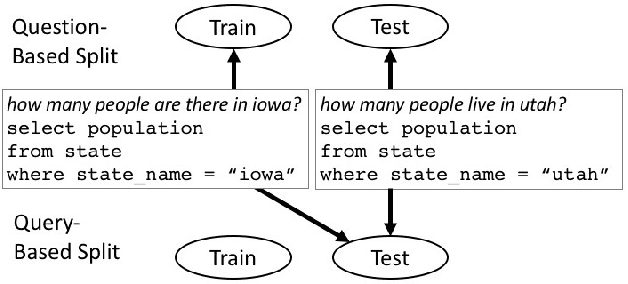

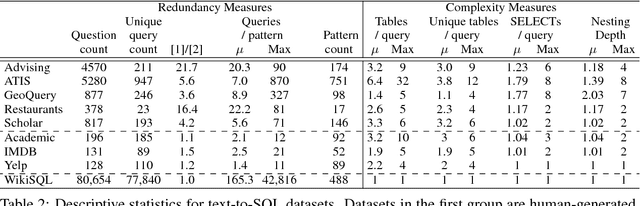

To be informative, an evaluation must measure how well systems generalize to realistic unseen data. We identify limitations of and propose improvements to current evaluations of text-to-SQL systems. First, we compare human-generated and automatically generated questions, characterizing properties of queries necessary for real-world applications. To facilitate evaluation on multiple datasets, we release standardized and improved versions of seven existing datasets and one new text-to-SQL dataset. Second, we show that the current division of data into training and test sets measures robustness to variations in the way questions are asked, but only partially tests how well systems generalize to new queries; therefore, we propose a complementary dataset split for evaluation of future work. Finally, we demonstrate how the common practice of anonymizing variables during evaluation removes an important challenge of the task. Our observations highlight key difficulties, and our methodology enables effective measurement of future development.
Neural Coreference Resolution with Deep Biaffine Attention by Joint Mention Detection and Mention Clustering
May 13, 2018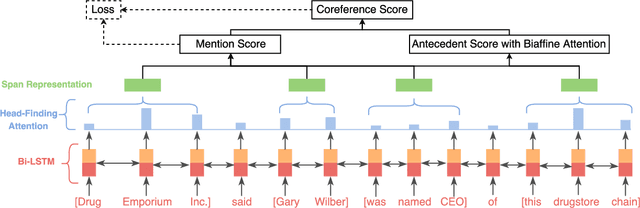
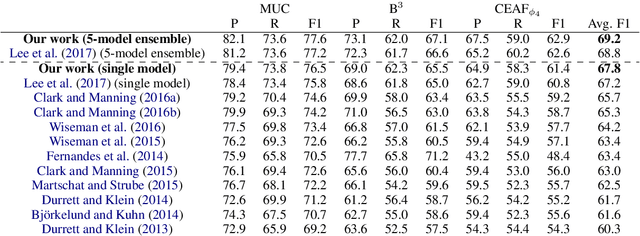
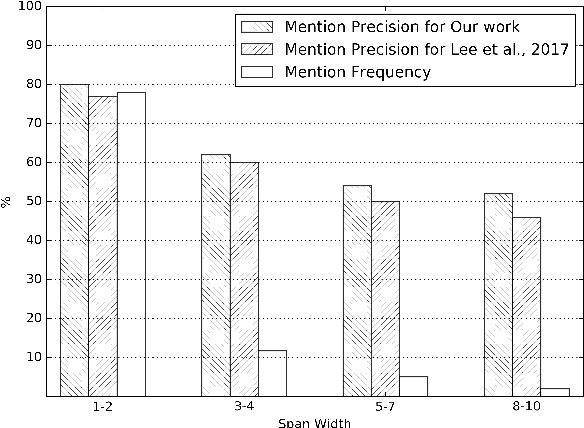

Coreference resolution aims to identify in a text all mentions that refer to the same real-world entity. The state-of-the-art end-to-end neural coreference model considers all text spans in a document as potential mentions and learns to link an antecedent for each possible mention. In this paper, we propose to improve the end-to-end coreference resolution system by (1) using a biaffine attention model to get antecedent scores for each possible mention, and (2) jointly optimizing the mention detection accuracy and the mention clustering log-likelihood given the mention cluster labels. Our model achieves the state-of-the-art performance on the CoNLL-2012 Shared Task English test set.
TypeSQL: Knowledge-based Type-Aware Neural Text-to-SQL Generation
Apr 25, 2018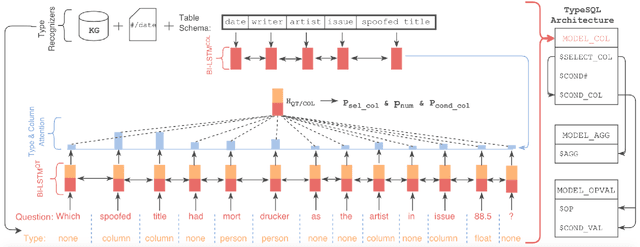
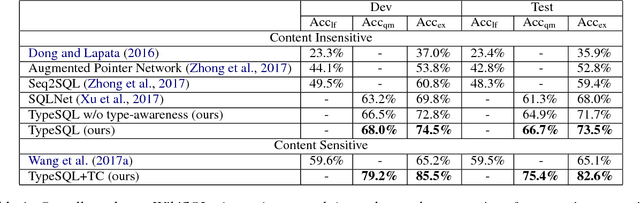
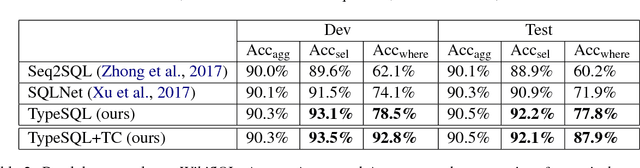
Interacting with relational databases through natural language helps users of any background easily query and analyze a vast amount of data. This requires a system that understands users' questions and converts them to SQL queries automatically. In this paper we present a novel approach, TypeSQL, which views this problem as a slot filling task. Additionally, TypeSQL utilizes type information to better understand rare entities and numbers in natural language questions. We test this idea on the WikiSQL dataset and outperform the prior state-of-the-art by 5.5% in much less time. We also show that accessing the content of databases can significantly improve the performance when users' queries are not well-formed. TypeSQL gets 82.6% accuracy, a 17.5% absolute improvement compared to the previous content-sensitive model.
* NAACL 2018
Robust Multilingual Part-of-Speech Tagging via Adversarial Training
Apr 20, 2018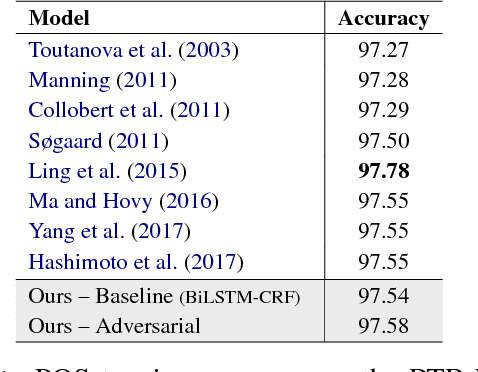
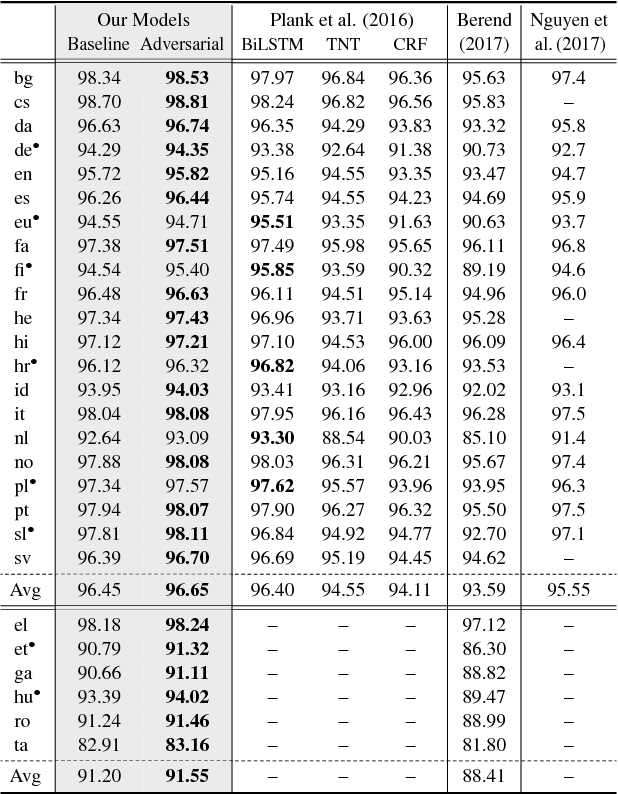
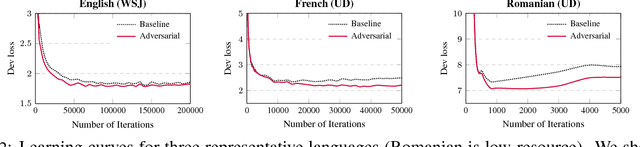
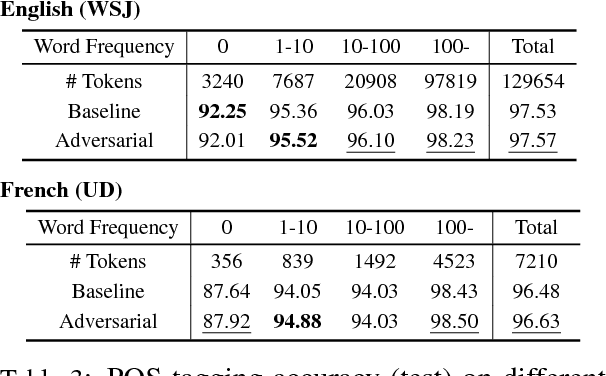
Adversarial training (AT) is a powerful regularization method for neural networks, aiming to achieve robustness to input perturbations. Yet, the specific effects of the robustness obtained from AT are still unclear in the context of natural language processing. In this paper, we propose and analyze a neural POS tagging model that exploits AT. In our experiments on the Penn Treebank WSJ corpus and the Universal Dependencies (UD) dataset (27 languages), we find that AT not only improves the overall tagging accuracy, but also 1) prevents over-fitting well in low resource languages and 2) boosts tagging accuracy for rare / unseen words. We also demonstrate that 3) the improved tagging performance by AT contributes to the downstream task of dependency parsing, and that 4) AT helps the model to learn cleaner word representations. 5) The proposed AT model is generally effective in different sequence labeling tasks. These positive results motivate further use of AT for natural language tasks.
Sentence Ordering and Coherence Modeling using Recurrent Neural Networks
Dec 22, 2017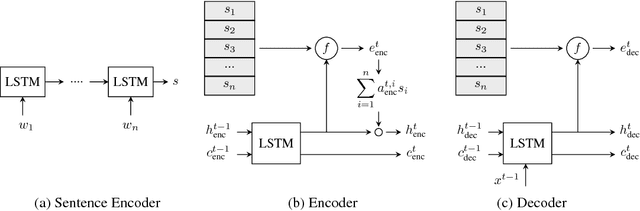
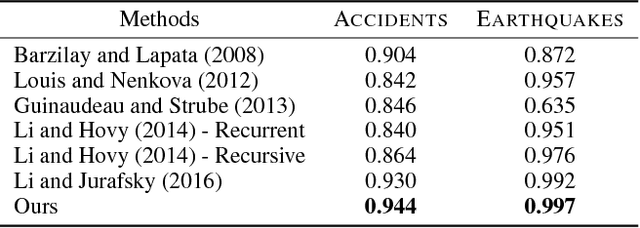
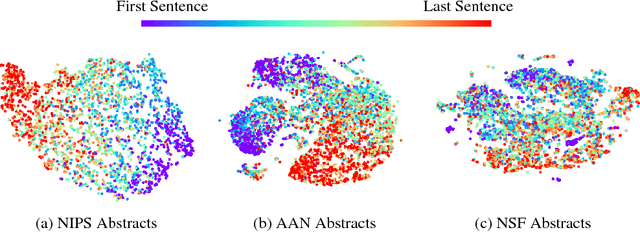
Modeling the structure of coherent texts is a key NLP problem. The task of coherently organizing a given set of sentences has been commonly used to build and evaluate models that understand such structure. We propose an end-to-end unsupervised deep learning approach based on the set-to-sequence framework to address this problem. Our model strongly outperforms prior methods in the order discrimination task and a novel task of ordering abstracts from scientific articles. Furthermore, our work shows that useful text representations can be obtained by learning to order sentences. Visualizing the learned sentence representations shows that the model captures high-level logical structure in paragraphs. Our representations perform comparably to state-of-the-art pre-training methods on sentence similarity and paraphrase detection tasks.
Addressee and Response Selection in Multi-Party Conversations with Speaker Interaction RNNs
Nov 28, 2017
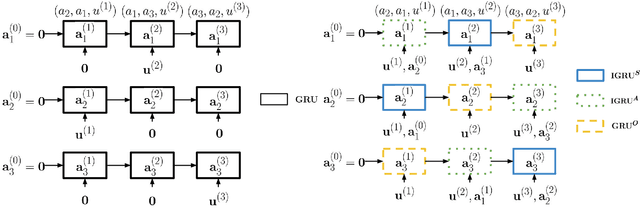
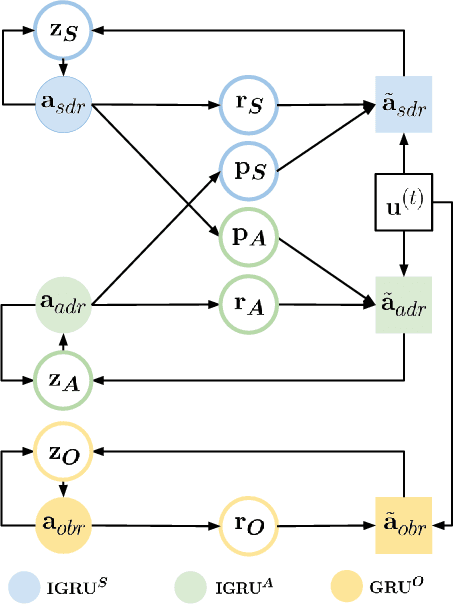
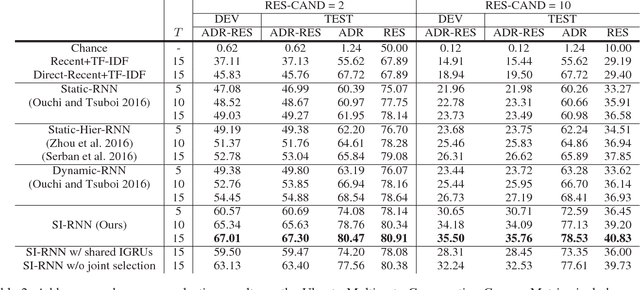
In this paper, we study the problem of addressee and response selection in multi-party conversations. Understanding multi-party conversations is challenging because of complex speaker interactions: multiple speakers exchange messages with each other, playing different roles (sender, addressee, observer), and these roles vary across turns. To tackle this challenge, we propose the Speaker Interaction Recurrent Neural Network (SI-RNN). Whereas the previous state-of-the-art system updated speaker embeddings only for the sender, SI-RNN uses a novel dialog encoder to update speaker embeddings in a role-sensitive way. Additionally, unlike the previous work that selected the addressee and response separately, SI-RNN selects them jointly by viewing the task as a sequence prediction problem. Experimental results show that SI-RNN significantly improves the accuracy of addressee and response selection, particularly in complex conversations with many speakers and responses to distant messages many turns in the past.
Graph-based Neural Multi-Document Summarization
Aug 23, 2017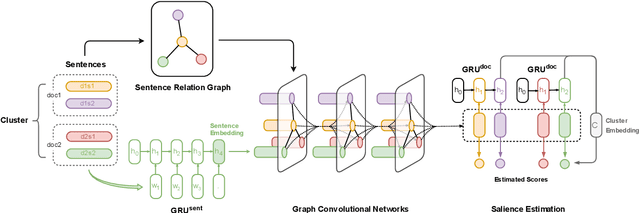
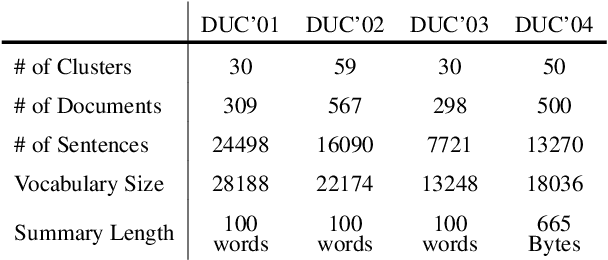
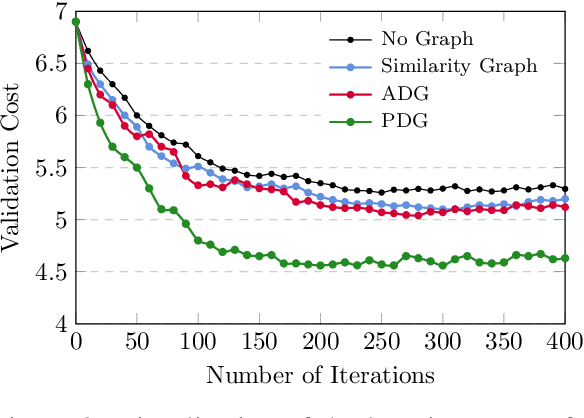
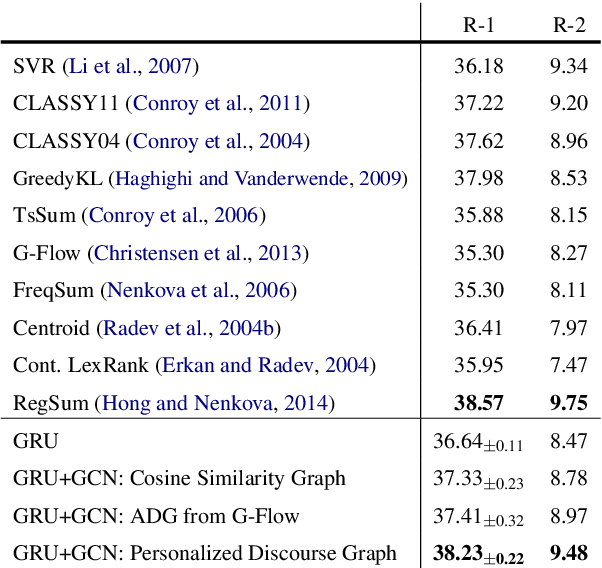
We propose a neural multi-document summarization (MDS) system that incorporates sentence relation graphs. We employ a Graph Convolutional Network (GCN) on the relation graphs, with sentence embeddings obtained from Recurrent Neural Networks as input node features. Through multiple layer-wise propagation, the GCN generates high-level hidden sentence features for salience estimation. We then use a greedy heuristic to extract salient sentences while avoiding redundancy. In our experiments on DUC 2004, we consider three types of sentence relation graphs and demonstrate the advantage of combining sentence relations in graphs with the representation power of deep neural networks. Our model improves upon traditional graph-based extractive approaches and the vanilla GRU sequence model with no graph, and it achieves competitive results against other state-of-the-art multi-document summarization systems.
Cruciform: Solving Crosswords with Natural Language Processing
Nov 23, 2016
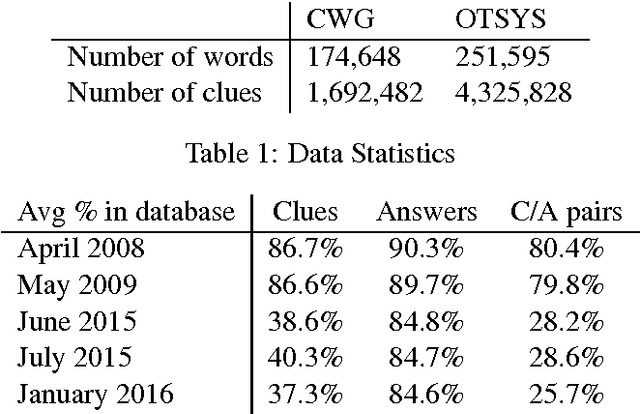
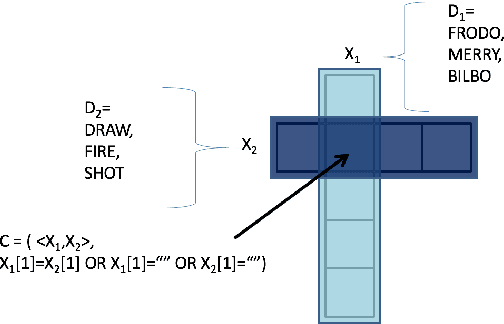
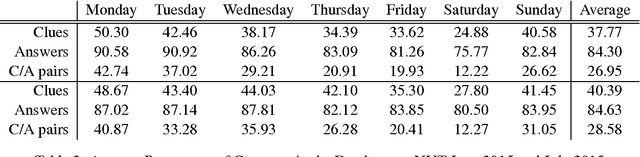
Crossword puzzles are popular word games that require not only a large vocabulary, but also a broad knowledge of topics. Answering each clue is a natural language task on its own as many clues contain nuances, puns, or counter-intuitive word definitions. Additionally, it can be extremely difficult to ascertain definitive answers without the constraints of the crossword grid itself. This task is challenging for both humans and computers. We describe here a new crossword solving system, Cruciform. We employ a group of natural language components, each of which returns a list of candidate words with scores when given a clue. These lists are used in conjunction with the fill intersections in the puzzle grid to formulate a constraint satisfaction problem, in a manner similar to the one used in the Dr. Fill system. We describe the results of several of our experiments with the system.
Dependency Sensitive Convolutional Neural Networks for Modeling Sentences and Documents
Nov 08, 2016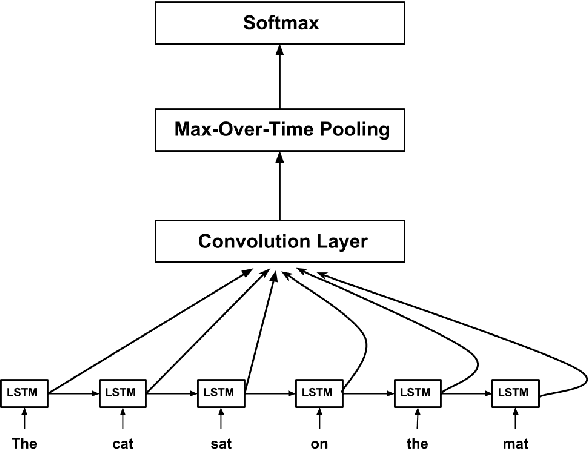
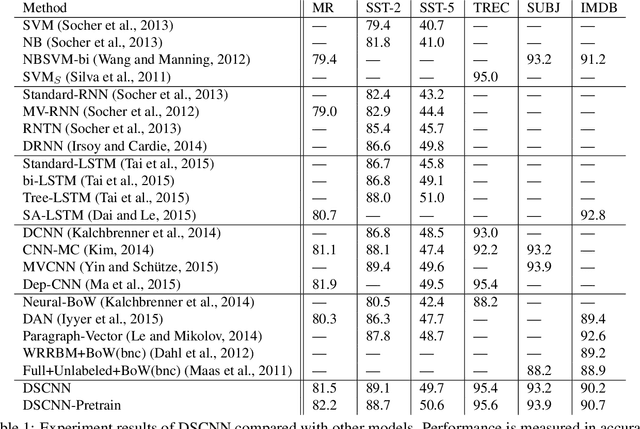
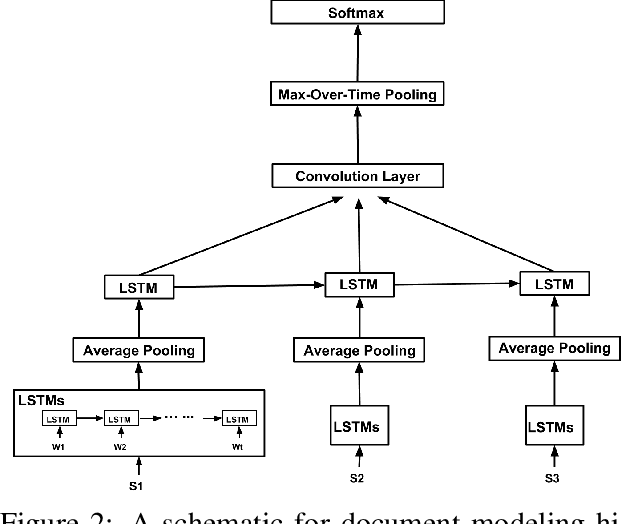
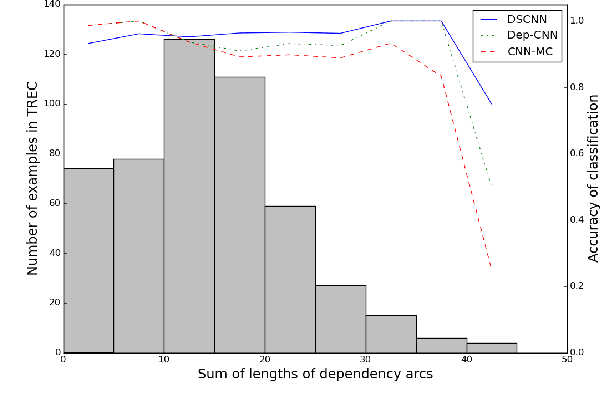
The goal of sentence and document modeling is to accurately represent the meaning of sentences and documents for various Natural Language Processing tasks. In this work, we present Dependency Sensitive Convolutional Neural Networks (DSCNN) as a general-purpose classification system for both sentences and documents. DSCNN hierarchically builds textual representations by processing pretrained word embeddings via Long Short-Term Memory networks and subsequently extracting features with convolution operators. Compared with existing recursive neural models with tree structures, DSCNN does not rely on parsers and expensive phrase labeling, and thus is not restricted to sentence-level tasks. Moreover, unlike other CNN-based models that analyze sentences locally by sliding windows, our system captures both the dependency information within each sentence and relationships across sentences in the same document. Experiment results demonstrate that our approach is achieving state-of-the-art performance on several tasks, including sentiment analysis, question type classification, and subjectivity classification.
Classifying Syntactic Regularities for Hundreds of Languages
Apr 27, 2016



This paper presents a comparison of classification methods for linguistic typology for the purpose of expanding an extensive, but sparse language resource: the World Atlas of Language Structures (WALS) (Dryer and Haspelmath, 2013). We experimented with a variety of regression and nearest-neighbor methods for use in classification over a set of 325 languages and six syntactic rules drawn from WALS. To classify each rule, we consider the typological features of the other five rules; linguistic features extracted from a word-aligned Bible in each language; and genealogical features (genus and family) of each language. In general, we find that propagating the majority label among all languages of the same genus achieves the best accuracy in label pre- diction. Following this, a logistic regression model that combines typological and linguistic features offers the next best performance. Interestingly, this model actually outperforms the majority labels among all languages of the same family.