 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSTC8-AVSD: Multimodal Semantic Transformer Network with Retrieval Style Word Generator
Apr 01, 2020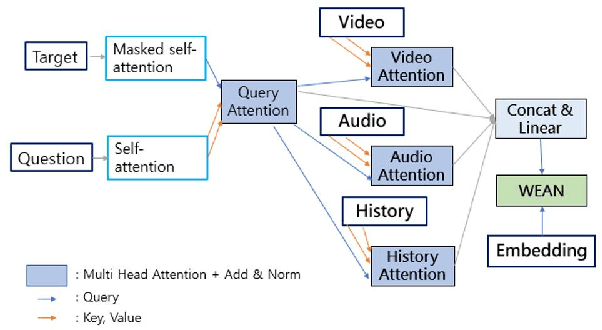
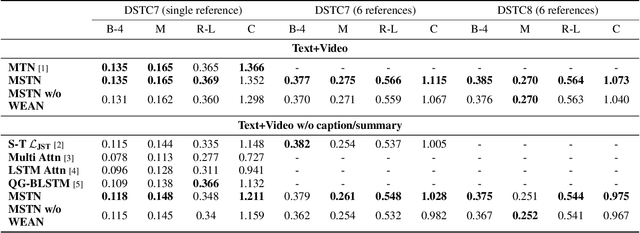
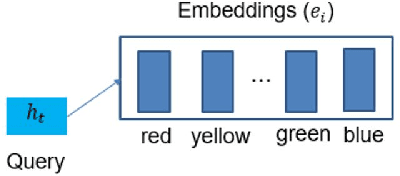
Audio Visual Scene-aware Dialog (AVSD) is the task of generating a response for a question with a given scene, video, audio, and the history of previous turns in the dialog. Existing systems for this task employ the transformers or recurrent neural network-based architecture with the encoder-decoder framework. Even though these techniques show superior performance for this task, they have significant limitations: the model easily overfits only to memorize the grammatical patterns; the model follows the prior distribution of the vocabularies in a dataset. To alleviate the problems, we propose a Multimodal Semantic Transformer Network. It employs a transformer-based architecture with an attention-based word embedding layer that generates words by querying word embeddings. With this design, our model keeps considering the meaning of the words at the generation stage. The empirical results demonstrate the superiority of our proposed model that outperforms most of the previous works for the AVSD task.
A Multimodal Dialogue System for Conversational Image Editing
Feb 16, 2020
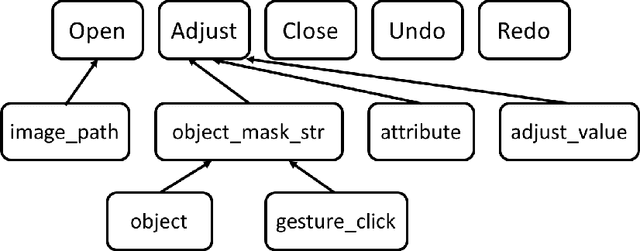
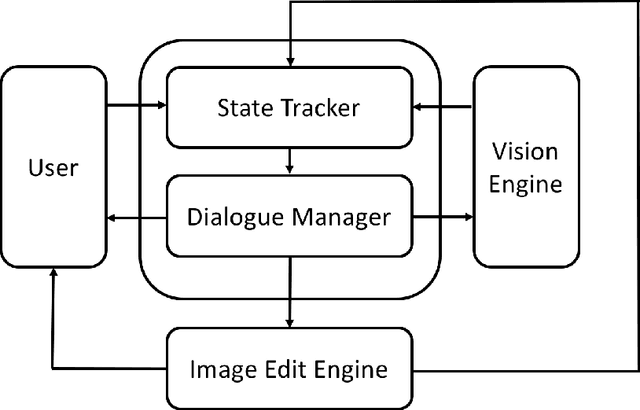
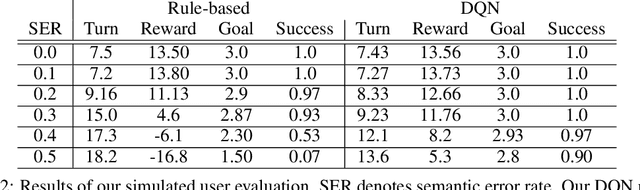
In this paper, we present a multimodal dialogue system for Conversational Image Editing. We formulate our multimodal dialogue system as a Partially Observed Markov Decision Process (POMDP) and trained it with Deep Q-Network (DQN) and a user simulator. Our evaluation shows that the DQN policy outperforms a rule-based baseline policy, achieving 90\% success rate under high error rates. We also conducted a real user study and analyzed real user behavior.
Adjusting Image Attributes of Localized Regions with Low-level Dialogue
Feb 11, 2020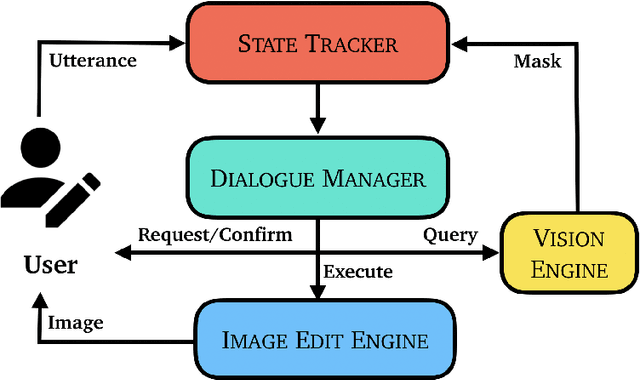

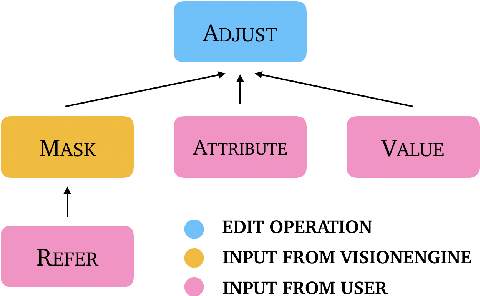

Natural Language Image Editing (NLIE) aims to use natural language instructions to edit images. Since novices are inexperienced with image editing techniques, their instructions are often ambiguous and contain high-level abstractions that tend to correspond to complex editing steps to accomplish. Motivated by this inexperience aspect, we aim to smooth the learning curve by teaching the novices to edit images using low-level commanding terminologies. Towards this end, we develop a task-oriented dialogue system to investigate low-level instructions for NLIE. Our system grounds language on the level of edit operations, and suggests options for a user to choose from. Though compelled to express in low-level terms, a user evaluation shows that 25% of users found our system easy-to-use, resonating with our motivation. An analysis shows that users generally adapt to utilizing the proposed low-level language interface. In this study, we identify that object segmentation as the key factor to the user satisfaction. Our work demonstrates the advantages of the low-level, direct language-action mapping approach that can be applied to other problem domains beyond image editing such as audio editing or industrial design.
TutorialVQA: Question Answering Dataset for Tutorial Videos
Dec 02, 2019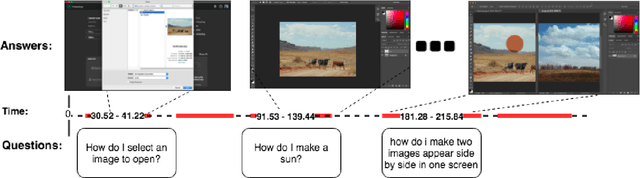

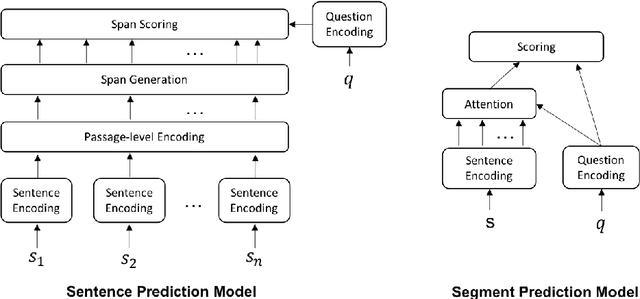
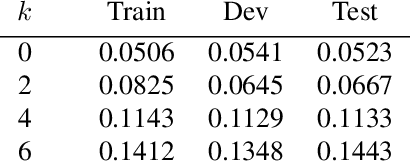
Despite the number of currently available datasets on video question answering, there still remains a need for a dataset involving multi-step and non-factoid answers. Moreover, relying on video transcripts remains an under-explored topic. To adequately address this, We propose a new question answering task on instructional videos, because of their verbose and narrative nature. While previous studies on video question answering have focused on generating a short text as an answer, given a question and video clip, our task aims to identify a span of a video segment as an answer which contains instructional details with various granularities. This work focuses on screencast tutorial videos pertaining to an image editing program. We introduce a dataset, TutorialVQA, consisting of about 6,000manually collected triples of (video, question, answer span). We also provide experimental results with several baselines algorithms using the video transcripts. The results indicate that the task is challenging and call for the investigation of new algorithms.
Analyzing Sentence Fusion in Abstractive Summarization
Oct 01, 2019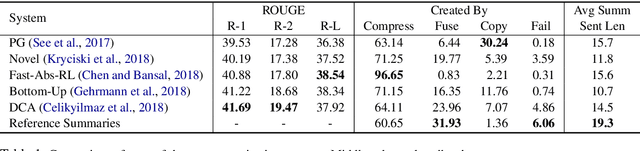
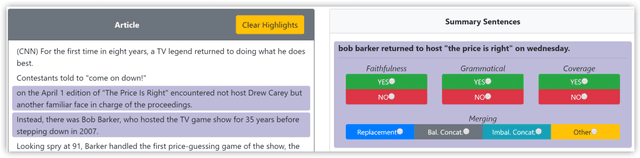
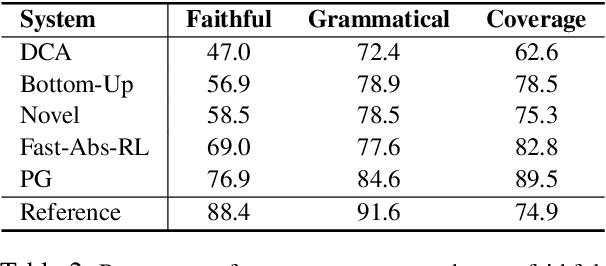
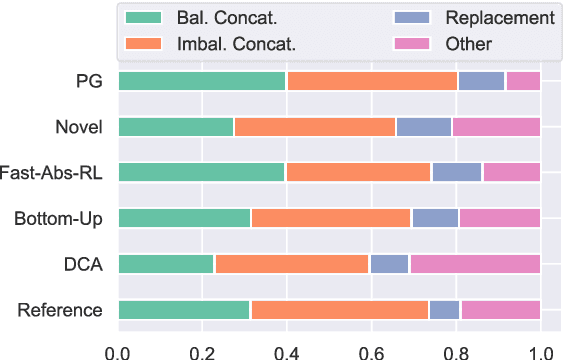
While recent work in abstractive summarization has resulted in higher scores in automatic metrics, there is little understanding on how these systems combine information taken from multiple document sentences. In this paper, we analyze the outputs of five state-of-the-art abstractive summarizers, focusing on summary sentences that are formed by sentence fusion. We ask assessors to judge the grammaticality, faithfulness, and method of fusion for summary sentences. Our analysis reveals that system sentences are mostly grammatical, but often fail to remain faithful to the original article.
Propagate-Selector: Detecting Supporting Sentences for Question Answering via Graph Neural Networks
Aug 24, 2019
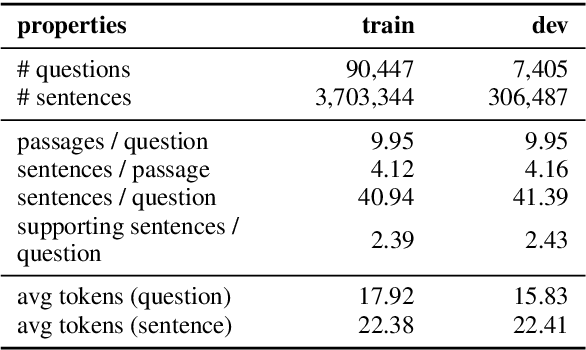
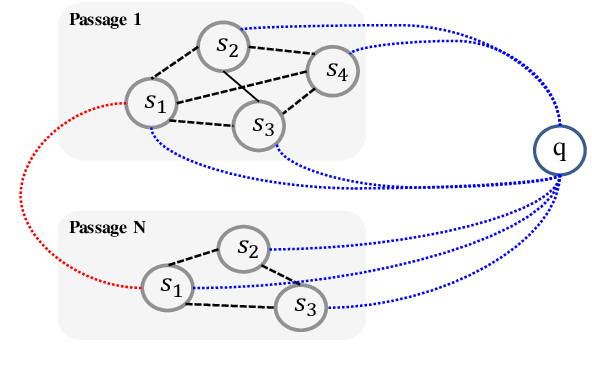
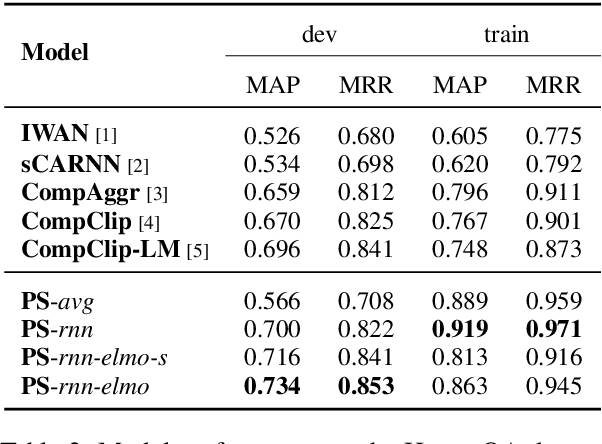
In this study, we propose a novel graph neural network, called propagate-selector (PS), which propagates information over sentences to understand information that cannot be inferred when considering sentences in isolation. First, we design a graph structure in which each node represents the individual sentences, and some pairs of nodes are selectively connected based on the text structure. Then, we develop an iterative attentive aggregation, and a skip-combine method in which a node interacts with its neighborhood nodes to accumulate the necessary information. To evaluate the performance of the proposed approaches, we conducted experiments with the HotpotQA dataset. The empirical results demonstrate the superiority of our proposed approach, which obtains the best performances compared to the widely used answer-selection models that do not consider the inter-sentential relationship.
Scoring Sentence Singletons and Pairs for Abstractive Summarization
May 31, 2019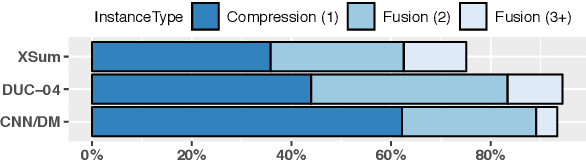

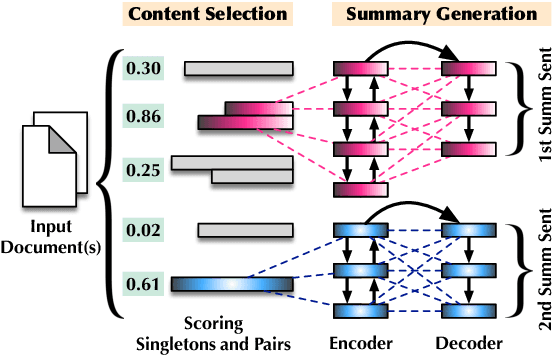
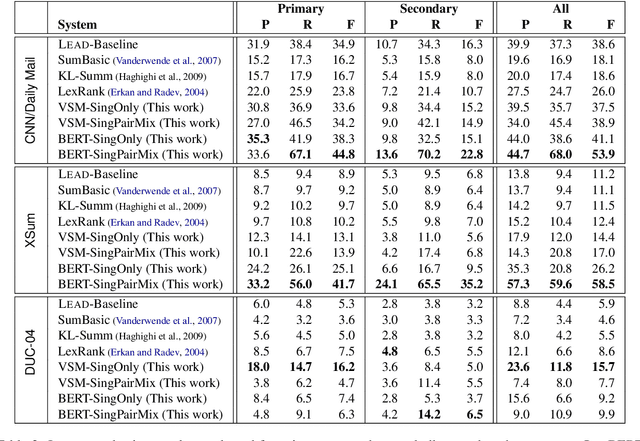
When writing a summary, humans tend to choose content from one or two sentences and merge them into a single summary sentence. However, the mechanisms behind the selection of one or multiple source sentences remain poorly understood. Sentence fusion assumes multi-sentence input; yet sentence selection methods only work with single sentences and not combinations of them. There is thus a crucial gap between sentence selection and fusion to support summarizing by both compressing single sentences and fusing pairs. This paper attempts to bridge the gap by ranking sentence singletons and pairs together in a unified space. Our proposed framework attempts to model human methodology by selecting either a single sentence or a pair of sentences, then compressing or fusing the sentence(s) to produce a summary sentence. We conduct extensive experiments on both single- and multi-document summarization datasets and report findings on sentence selection and abstraction.
A Compare-Aggregate Model with Latent Clustering for Answer Selection
May 30, 2019
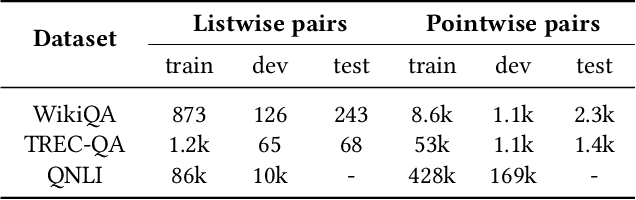
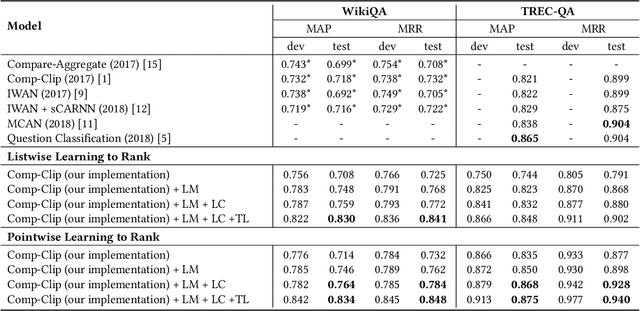
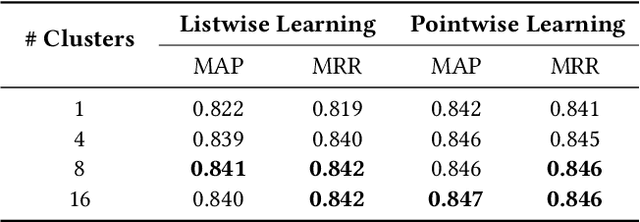
In this paper, we propose a novel method for a sentence-level answer-selection task that is one of the fundamental problems in natural language processing. First, we explore the effect of additional information by adopting a pretrained language model to compute the vector representation of the input text and by applying transfer learning from a large-scale corpus. Second, we enhance the compare-aggregate model by proposing a novel latent clustering method to compute additional information within the target corpus and by changing the objective function from listwise to pointwise. To evaluate the performance of the proposed approaches, experiments are performed with the WikiQA and TREC-QA datasets. The empirical results demonstrate the superiority of our proposed approach, which achieve state-of-the-art performance on both datasets.
A Discourse-Aware Attention Model for Abstractive Summarization of Long Documents
May 22, 2018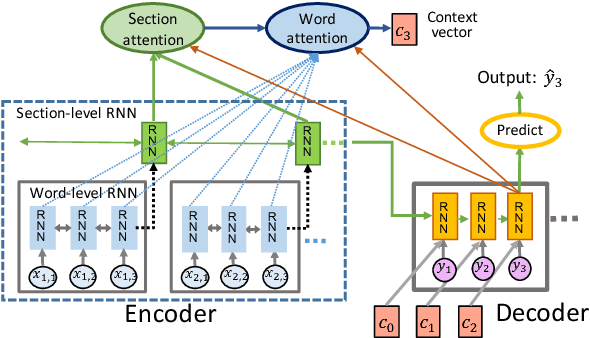
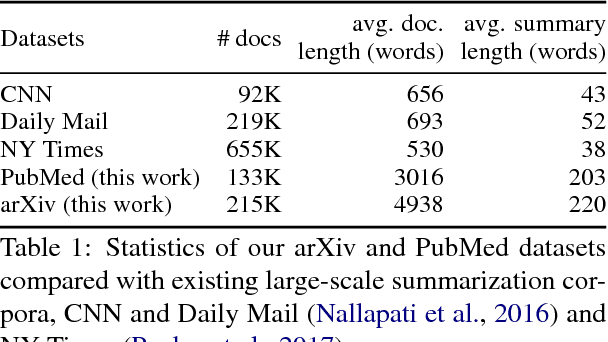
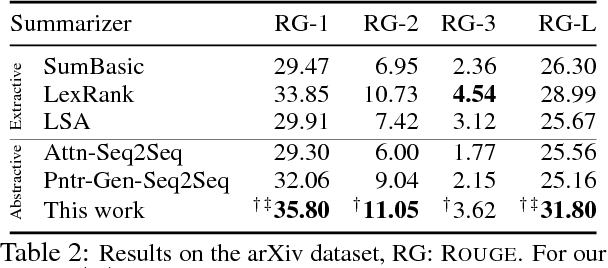
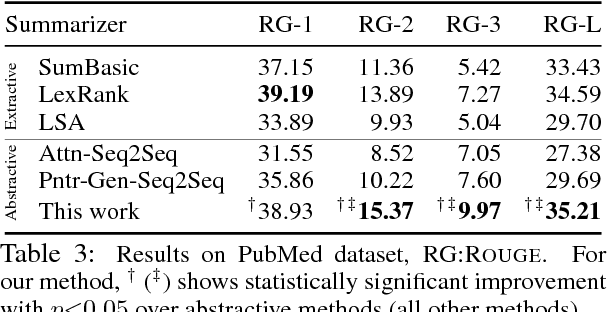
Neural abstractive summarization models have led to promising results in summarizing relatively short documents. We propose the first model for abstractive summarization of single, longer-form documents (e.g., research papers). Our approach consists of a new hierarchical encoder that models the discourse structure of a document, and an attentive discourse-aware decoder to generate the summary. Empirical results on two large-scale datasets of scientific papers show that our model significantly outperforms state-of-the-art models.
Detecting Table Region in PDF Documents Using Distant Supervision
Sep 22, 2015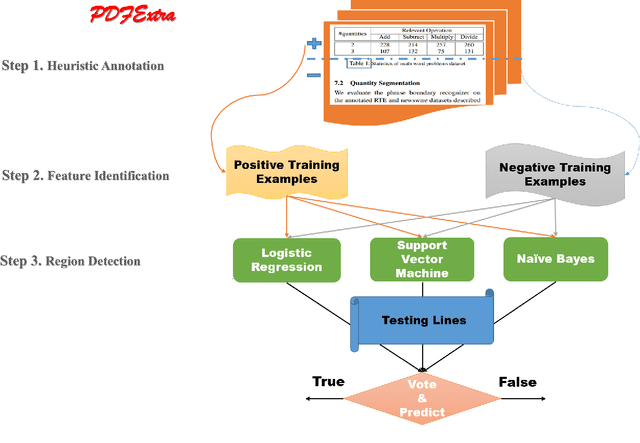

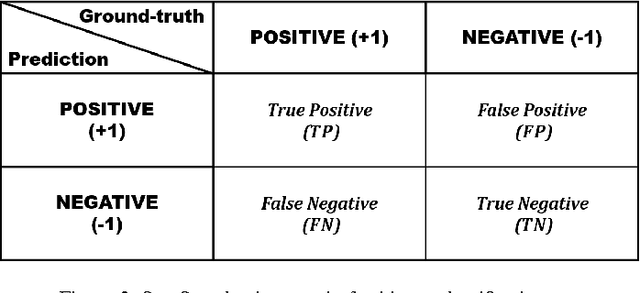

Superior to state-of-the-art approaches which compete in table recognition with 67 annotated government reports in PDF format released by {\it ICDAR 2013 Table Competition}, this paper contributes a novel paradigm leveraging large-scale unlabeled PDF documents to open-domain table detection. We integrate the paradigm into our latest developed system ({\it PdfExtra}) to detect the region of tables by means of 9,466 academic articles from the entire repository of {\it ACL Anthology}, where almost all papers are archived by PDF format without annotation for tables. The paradigm first designs heuristics to automatically construct weakly labeled data. It then feeds diverse evidences, such as layouts of documents and linguistic features, which are extracted by {\it Apache PDFBox} and processed by {\it Stanford NLP} toolkit, into different canonical classifiers. We finally use these classifiers, i.e. {\it Naive Bayes}, {\it Logistic Regression} and {\it Support Vector Machine}, to collaboratively vote on the region of tables. Experimental results show that {\it PdfExtra} achieves a great leap forward, compared with the state-of-the-art approach. Moreover, we discuss the factors of different features, learning models and even domains of documents that may impact the performance. Extensive evaluations demonstrate that our paradigm is compatible enough to leverage various features and learning models for open-domain table region detection within PDF files.