 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocas: Your Models are Principled Initializers of Locally-Supported Parametric Memories
Feb 04, 2026In this paper, we aim to bridge test-time-training with a new type of parametric memory that can be flexibly offloaded from or merged into model parameters. We present Locas, a Locally-Supported parametric memory that shares the design of FFN blocks in modern transformers, allowing it to be flexibly permanentized into the model parameters while supporting efficient continual learning. We discuss two major variants of Locas: one with a conventional two-layer MLP design that has a clearer theoretical guarantee; the other one shares the same GLU-FFN structure with SOTA LLMs, and can be easily attached to existing models for both parameter-efficient and computation-efficient continual learning. Crucially, we show that proper initialization of such low-rank sideway-FFN-style memories -- performed in a principled way by reusing model parameters, activations and/or gradients -- is essential for fast convergence, improved generalization, and catastrophic forgetting prevention. We validate the proposed memory mechanism on the PG-19 whole-book language modeling and LoCoMo long-context dialogue question answering tasks. With only 0.02\% additional parameters in the lowest case, Locas-GLU is capable of storing the information from past context while maintaining a much smaller context window. In addition, we also test the model's general capability loss after memorizing the whole book with Locas, through comparative MMLU evaluation. Results show the promising ability of Locas to permanentize past context into parametric knowledge with minimized catastrophic forgetting of the model's existing internal knowledge.
The End of Manual Decoding: Towards Truly End-to-End Language Models
Oct 30, 2025



The "end-to-end" label for LLMs is a misnomer. In practice, they depend on a non-differentiable decoding process that requires laborious, hand-tuning of hyperparameters like temperature and top-p. This paper introduces AutoDeco, a novel architecture that enables truly "end-to-end" generation by learning to control its own decoding strategy. We augment the standard transformer with lightweight heads that, at each step, dynamically predict context-specific temperature and top-p values alongside the next-token logits. This approach transforms decoding into a parametric, token-level process, allowing the model to self-regulate its sampling strategy within a single forward pass. Through extensive experiments on eight benchmarks, we demonstrate that AutoDeco not only significantly outperforms default decoding strategies but also achieves performance comparable to an oracle-tuned baseline derived from "hacking the test set"-a practical upper bound for any static method. Crucially, we uncover an emergent capability for instruction-based decoding control: the model learns to interpret natural language commands (e.g., "generate with low randomness") and adjusts its predicted temperature and top-p on a token-by-token basis, opening a new paradigm for steerable and interactive LLM decoding.
Effidit: Your AI Writing Assistant
Aug 04, 2022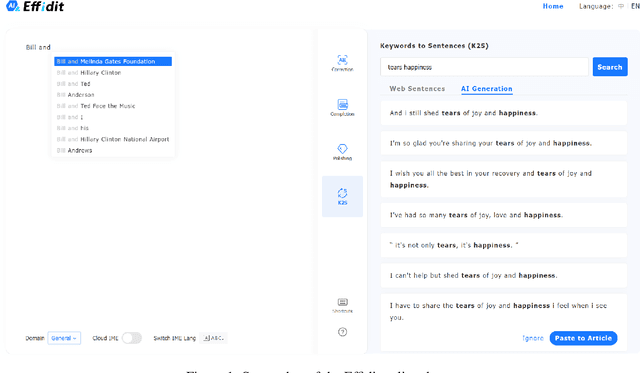
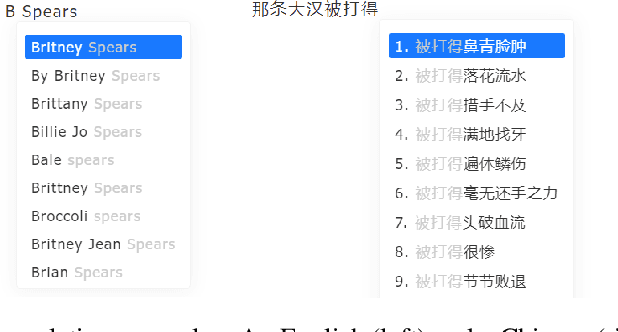

In this technical report, we introduce Effidit (Efficient and Intelligent Editing), a digital writing assistant that facilitates users to write higher-quality text more efficiently by using artificial intelligence (AI) technologies. Previous writing assistants typically provide the function of error checking (to detect and correct spelling and grammatical errors) and limited text-rewriting functionality. With the emergence of large-scale neural language models, some systems support automatically completing a sentence or a paragraph. In Effidit, we significantly expand the capacities of a writing assistant by providing functions in five categories: text completion, error checking, text polishing, keywords to sentences (K2S), and cloud input methods (cloud IME). In the text completion category, Effidit supports generation-based sentence completion, retrieval-based sentence completion, and phrase completion. In contrast, many other writing assistants so far only provide one or two of the three functions. For text polishing, we have three functions: (context-aware) phrase polishing, sentence paraphrasing, and sentence expansion, whereas many other writing assistants often support one or two functions in this category. The main contents of this report include major modules of Effidit, methods for implementing these modules, and evaluation results of some key methods.