 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropyCache: Decoded Token Entropy Guided KV Caching for Diffusion Language Models
Mar 19, 2026Diffusion-based large language models (dLLMs) rely on bidirectional attention, which prevents lossless KV caching and requires a full forward pass at every denoising step. Existing approximate KV caching methods reduce this cost by selectively updating cached states, but their decision overhead scales with context length or model depth. We propose EntropyCache, a training-free KV caching method that uses the maximum entropy of newly decoded token distributions as a constant-cost signal for deciding when to recompute. Our design is grounded in two empirical observations: (1) decoded token entropy correlates with KV cache drift, providing a cheap proxy for cache staleness, and (2) feature volatility of decoded tokens persists for multiple steps after unmasking, motivating recomputation of the $k$ most recently decoded tokens. The skip-or-recompute decision requires only $O(V)$ computation per step, independent of context length and model scale. Experiments on LLaDA-8B-Instruct and Dream-7B-Instruct show that EntropyCache achieves $15.2\times$-$26.4\times$ speedup on standard benchmarks and $22.4\times$-$24.1\times$ on chain-of-thought benchmarks, with competitive accuracy and decision overhead accounting for only $0.5\%$ of inference time. Code is available at https://github.com/mscheong01/EntropyCache.
CXR-LT 2024: A MICCAI challenge on long-tailed, multi-label, and zero-shot disease classification from chest X-ray
Jun 09, 2025The CXR-LT series is a community-driven initiative designed to enhance lung disease classification using chest X-rays (CXR). It tackles challenges in open long-tailed lung disease classification and enhances the measurability of state-of-the-art techniques. The first event, CXR-LT 2023, aimed to achieve these goals by providing high-quality benchmark CXR data for model development and conducting comprehensive evaluations to identify ongoing issues impacting lung disease classification performance. Building on the success of CXR-LT 2023, the CXR-LT 2024 expands the dataset to 377,110 chest X-rays (CXRs) and 45 disease labels, including 19 new rare disease findings. It also introduces a new focus on zero-shot learning to address limitations identified in the previous event. Specifically, CXR-LT 2024 features three tasks: (i) long-tailed classification on a large, noisy test set, (ii) long-tailed classification on a manually annotated "gold standard" subset, and (iii) zero-shot generalization to five previously unseen disease findings. This paper provides an overview of CXR-LT 2024, detailing the data curation process and consolidating state-of-the-art solutions, including the use of multimodal models for rare disease detection, advanced generative approaches to handle noisy labels, and zero-shot learning strategies for unseen diseases. Additionally, the expanded dataset enhances disease coverage to better represent real-world clinical settings, offering a valuable resource for future research. By synthesizing the insights and innovations of participating teams, we aim to advance the development of clinically realistic and generalizable diagnostic models for chest radiography.
NSNQuant: A Double Normalization Approach for Calibration-Free Low-Bit Vector Quantization of KV Cache
May 23, 2025



Large Language Model (LLM) inference is typically memory-intensive, especially when processing large batch sizes and long sequences, due to the large size of key-value (KV) cache. Vector Quantization (VQ) is recently adopted to alleviate this issue, but we find that the existing approach is susceptible to distribution shift due to its reliance on calibration datasets. To address this limitation, we introduce NSNQuant, a calibration-free Vector Quantization (VQ) technique designed for low-bit compression of the KV cache. By applying a three-step transformation-1) a token-wise normalization (Normalize), 2) a channel-wise centering (Shift), and 3) a second token-wise normalization (Normalize)-with Hadamard transform, NSNQuant effectively aligns the token distribution with the standard normal distribution. This alignment enables robust, calibration-free vector quantization using a single reusable codebook. Extensive experiments show that NSNQuant consistently outperforms prior methods in both 1-bit and 2-bit settings, offering strong generalization and up to 3$\times$ throughput gain over full-precision baselines.
In-Context Learning with Noisy Labels
Nov 29, 2024In-context learning refers to the emerging ability of large language models (LLMs) to perform a target task without additional training, utilizing demonstrations of the task. Recent studies aim to enhance in-context learning performance by selecting more useful demonstrations. However, they overlook the presence of inevitable noisy labels in task demonstrations that arise during the labeling process in the real-world. In this paper, we propose a new task, in-context learning with noisy labels, which aims to solve real-world problems for in-context learning where labels in task demonstrations would be corrupted. Moreover, we propose a new method and baseline methods for the new task, inspired by studies in learning with noisy labels. Through experiments, we demonstrate that our proposed method can serve as a safeguard against performance degradation in in-context learning caused by noisy labels.
Testing the Channels of Convolutional Neural Networks
Mar 06, 2023



Neural networks have complex structures, and thus it is hard to understand their inner workings and ensure correctness. To understand and debug convolutional neural networks (CNNs) we propose techniques for testing the channels of CNNs. We design FtGAN, an extension to GAN, that can generate test data with varying the intensity (i.e., sum of the neurons) of a channel of a target CNN. We also proposed a channel selection algorithm to find representative channels for testing. To efficiently inspect the target CNN's inference computations, we define unexpectedness score, which estimates how similar the inference computation of the test data is to that of the training data. We evaluated FtGAN with five public datasets and showed that our techniques successfully identify defective channels in five different CNN models.
Gradient Estimation for Unseen Domain Risk Minimization with Pre-Trained Models
Feb 08, 2023



Domain generalization aims to build generalized models that perform well on unseen domains when only source domains are available for model optimization. Recent studies have demonstrated that large-scale pre-trained models could play an important role in domain generalization by providing their generalization power. However, large-scale pre-trained models are not fully equipped with target task-specific knowledge due to a discrepancy between the pre-training objective and the target task. Although the task-specific knowledge could be learned from source domains by fine-tuning, this hurts the generalization power of the pre-trained models because of gradient bias toward the source domains. To address this issue, we propose a new domain generalization method that estimates unobservable gradients that reduce potential risks in unseen domains, using a large-scale pre-trained model. Our proposed method allows the pre-trained model to learn task-specific knowledge further while preserving its generalization ability with the estimated gradients. Experimental results show that our proposed method outperforms baseline methods on DomainBed, a standard benchmark in domain generalization. We also provide extensive analyses to demonstrate that the estimated unobserved gradients relieve the gradient bias, and the pre-trained model learns the task-specific knowledge without sacrificing its generalization power.
Reliable Decision from Multiple Subtasks through Threshold Optimization: Content Moderation in the Wild
Aug 17, 2022
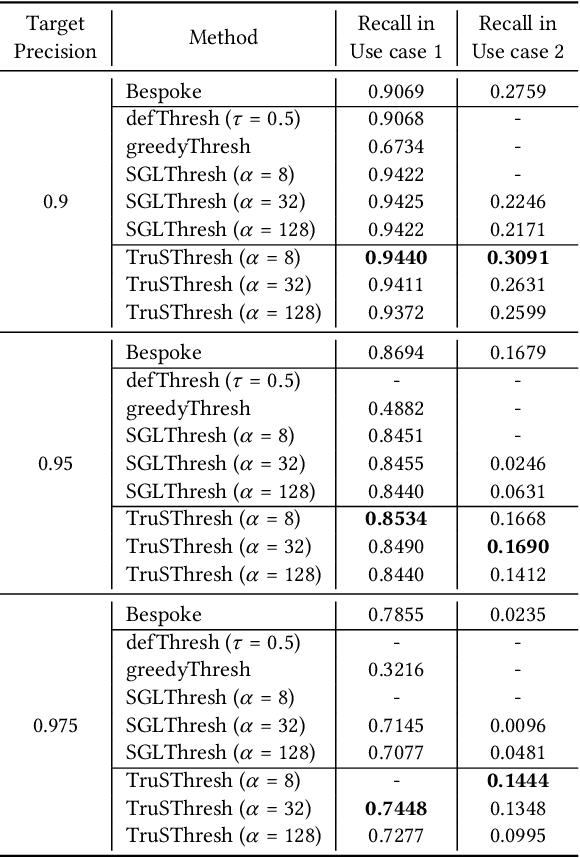
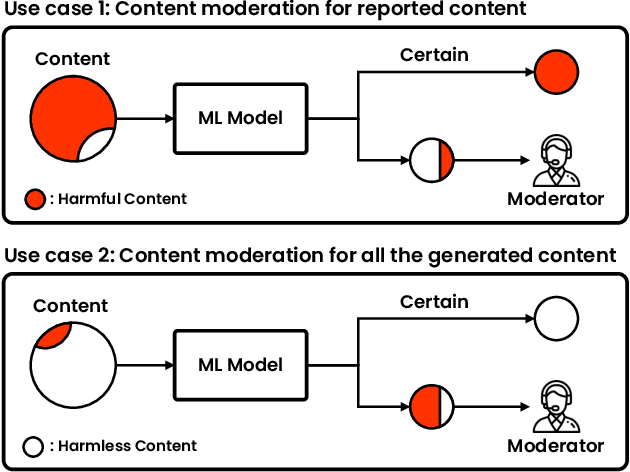
Social media platforms struggle to protect users from harmful content through content moderation. These platforms have recently leveraged machine learning models to cope with the vast amount of user-generated content daily. Since moderation policies vary depending on countries and types of products, it is common to train and deploy the models per policy. However, this approach is highly inefficient, especially when the policies change, requiring dataset re-labeling and model re-training on the shifted data distribution. To alleviate this cost inefficiency, social media platforms often employ third-party content moderation services that provide prediction scores of multiple subtasks, such as predicting the existence of underage personnel, rude gestures, or weapons, instead of directly providing final moderation decisions. However, making a reliable automated moderation decision from the prediction scores of the multiple subtasks for a specific target policy has not been widely explored yet. In this study, we formulate real-world scenarios of content moderation and introduce a simple yet effective threshold optimization method that searches the optimal thresholds of the multiple subtasks to make a reliable moderation decision in a cost-effective way. Extensive experiments demonstrate that our approach shows better performance in content moderation compared to existing threshold optimization methods and heuristics.