 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNSNQuant: A Double Normalization Approach for Calibration-Free Low-Bit Vector Quantization of KV Cache
May 23, 2025



Large Language Model (LLM) inference is typically memory-intensive, especially when processing large batch sizes and long sequences, due to the large size of key-value (KV) cache. Vector Quantization (VQ) is recently adopted to alleviate this issue, but we find that the existing approach is susceptible to distribution shift due to its reliance on calibration datasets. To address this limitation, we introduce NSNQuant, a calibration-free Vector Quantization (VQ) technique designed for low-bit compression of the KV cache. By applying a three-step transformation-1) a token-wise normalization (Normalize), 2) a channel-wise centering (Shift), and 3) a second token-wise normalization (Normalize)-with Hadamard transform, NSNQuant effectively aligns the token distribution with the standard normal distribution. This alignment enables robust, calibration-free vector quantization using a single reusable codebook. Extensive experiments show that NSNQuant consistently outperforms prior methods in both 1-bit and 2-bit settings, offering strong generalization and up to 3$\times$ throughput gain over full-precision baselines.
Grouped Sequency-arranged Rotation: Optimizing Rotation Transformation for Quantization for Free
May 02, 2025



Large Language Models (LLMs) face deployment challenges due to high computational costs, and while Post-Training Quantization (PTQ) offers a solution, existing rotation-based methods struggle at very low bit-widths like 2-bit. We introduce a novel, training-free approach to construct an improved rotation matrix, addressing the limitations of current methods. The key contributions include leveraging the Walsh-Hadamard transform with sequency ordering, which clusters similar frequency components to reduce quantization error compared to standard Hadamard matrices, significantly improving performance. Furthermore, we propose a Grouped Sequency-arranged Rotation (GSR) using block-diagonal matrices with smaller Walsh blocks, effectively isolating outlier impacts and achieving performance comparable to optimization-based methods without requiring any training. Our method demonstrates robust performance on reasoning tasks and Perplexity (PPL) score on WikiText-2. Our method also enhances results even when applied over existing learned rotation techniques.
Baking Relightable NeRF for Real-time Direct/Indirect Illumination Rendering
Sep 16, 2024
Relighting, which synthesizes a novel view under a given lighting condition (unseen in training time), is a must feature for immersive photo-realistic experience. However, real-time relighting is challenging due to high computation cost of the rendering equation which requires shape and material decomposition and visibility test to model shadow. Additionally, for indirect illumination, additional computation of rendering equation on each secondary surface point (where reflection occurs) is required rendering real-time relighting challenging. We propose a novel method that executes a CNN renderer to compute primary surface points and rendering parameters, required for direct illumination. We also present a lightweight hash grid-based renderer, for indirect illumination, which is recursively executed to perform the secondary ray tracing process. Both renderers are trained in a distillation from a pre-trained teacher model and provide real-time physically-based rendering under unseen lighting condition at a negligible loss of rendering quality.
Phys3DGS: Physically-based 3D Gaussian Splatting for Inverse Rendering
Sep 16, 2024

We propose two novel ideas (adoption of deferred rendering and mesh-based representation) to improve the quality of 3D Gaussian splatting (3DGS) based inverse rendering. We first report a problem incurred by hidden Gaussians, where Gaussians beneath the surface adversely affect the pixel color in the volume rendering adopted by the existing methods. In order to resolve the problem, we propose applying deferred rendering and report new problems incurred in a naive application of deferred rendering to the existing 3DGS-based inverse rendering. In an effort to improve the quality of 3DGS-based inverse rendering under deferred rendering, we propose a novel two-step training approach which (1) exploits mesh extraction and utilizes a hybrid mesh-3DGS representation and (2) applies novel regularization methods to better exploit the mesh. Our experiments show that, under relighting, the proposed method offers significantly better rendering quality than the existing 3DGS-based inverse rendering methods. Compared with the SOTA voxel grid-based inverse rendering method, it gives better rendering quality while offering real-time rendering.
Autoencoder-Based Incremental Class Learning without Retraining on Old Data
Jul 18, 2019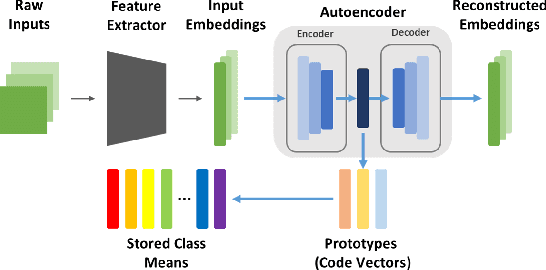
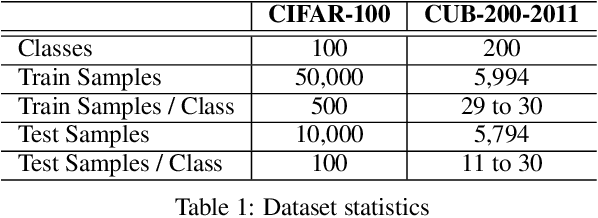

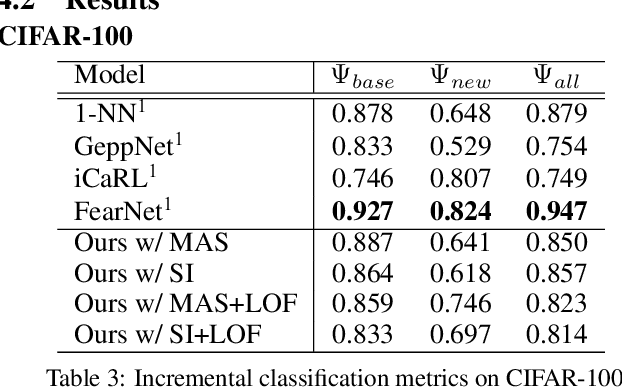
Incremental class learning, a scenario in continual learning context where classes and their training data are sequentially and disjointedly observed, challenges a problem widely known as catastrophic forgetting. In this work, we propose a novel incremental class learning method that can significantly reduce memory overhead compared to previous approaches. Apart from conventional classification scheme using softmax, our model bases on an autoencoder to extract prototypes for given inputs so that no change in its output unit is required. It stores only the mean of prototypes per class to perform metric-based classification, unlike rehearsal approaches which rely on large memory or generative model. To mitigate catastrophic forgetting, regularization methods are applied on our model when a new task is encountered. We evaluate our method by experimenting on CIFAR-100 and CUB-200-2011 and show that its performance is comparable to the state-of-the-art method with much lower additional memory cost.