 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Similarity Volume Aggregation for Open-Vocabulary Action Recognition
May 22, 2026Recent Open-Vocabulary Action Recognition (OVAR) methods typically aggregate visual features into a global representation before computing text alignment, a process that obscures local patch information and fine-grained spatio-temporal cues. We propose Similarity Volume Aggregation (SimVA), a framework that constructs a dense 4D spatio-temporal similarity volume from patch-level visual-text similarities. SimVA constructs a spatio-temporal similarity volume over local video tokens and action classes, and employs class sampling to ensure similarity aggregation scalable to large vocabularies. The similarity volume is refined by spatial aggregation, which contextualizes local similarity patterns to improve intra-frame consistency. Motion-aware modulation further injects inter-frame variation cues, highlighting dynamically changing regions. Mamba-based temporal aggregation then models the evolution of class-conditioned similarity patterns across frames. By maintaining dense visual-text correspondence, SimVA effectively transfers CLIP to video action recognition, achieving competitive performance across zero-shot, few-shot, and base-to-novel benchmarks.
FluoCLIP: Stain-Aware Focus Quality Assessment in Fluorescence Microscopy
Feb 27, 2026Accurate focus quality assessment (FQA) in fluorescence microscopy remains challenging, as the stain-dependent optical properties of fluorescent dyes cause abrupt and heterogeneous focus shifts. However, existing datasets and models overlook this variability, treating focus quality as a stain-agnostic problem. In this work, we formulate the task of stain-aware FQA, emphasizing that focus behavior in fluorescence microscopy must be modeled as a function of staining characteristics. Through quantitative analysis of existing datasets (FocusPath, BBBC006) and our newly curated FluoMix, we demonstrate that focus-rank relationships vary substantially across stains, underscoring the need for stain-aware modeling in fluorescence microscopy. To support this new formulation, we propose FluoMix, the first dataset for stain-aware FQA that encompasses multiple tissues, fluorescent stains, and focus variations. Building on this dataset, we propose FluoCLIP, a two-stage vision-language framework that leverages CLIP's alignment capability to interpret focus quality in the context of biological staining. In the stain-grounding phase, FluoCLIP learns general stain representations by aligning textual stain tokens with visual features, while in the stain-guided ranking phase, it optimizes stain-specific rank prompts for ordinal focus prediction. Together, our formulation, dataset, and framework establish the first foundation for stain-aware FQA, and FluoCLIP achieves strong generalization across diverse fluorescence microscopy conditions.
Speech to Text Adaptation: Towards an Efficient Cross-Modal Distillation
May 17, 2020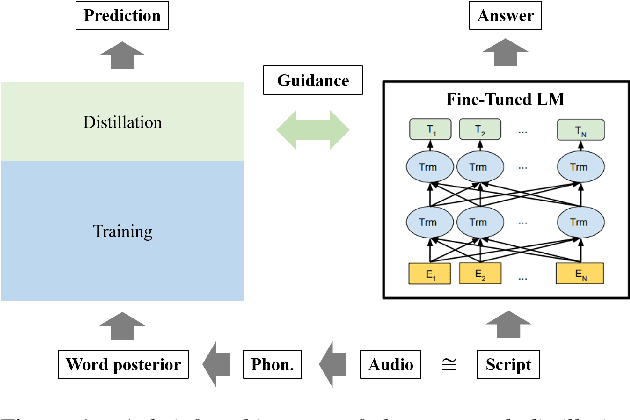
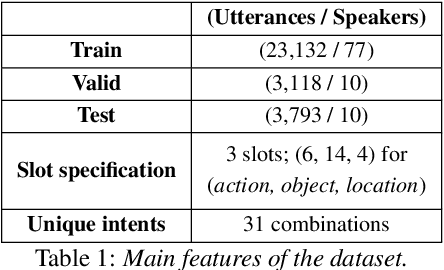
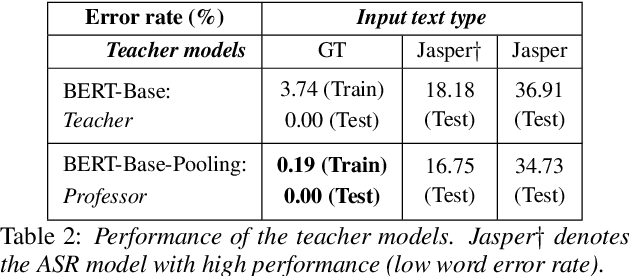
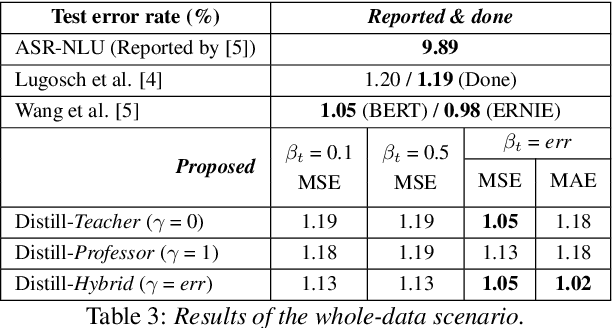
Speech is one of the most effective means of communication and is full of information that helps the transmission of utterer's thoughts. However, mainly due to the cumbersome processing of acoustic features, phoneme or word posterior probability has frequently been discarded in understanding the natural language. Thus, some recent spoken language understanding (SLU) modules have utilized an end-to-end structure that preserves the uncertainty information. This further reduces the propagation of speech recognition error and guarantees computational efficiency. We claim that in this process, the speech comprehension can benefit from the inference of massive pre-trained language models (LMs). We transfer the knowledge from a concrete Transformer-based text LM to an SLU module which can face a data shortage, based on recent cross-modal distillation methodologies. We demonstrate the validity of our proposal upon the performance on the Fluent Speech Command dataset. Thereby, we experimentally verify our hypothesis that the knowledge could be shared from the top layer of the LM to a fully speech-based module, in which the abstracted speech is expected to meet the semantic representation.