 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Bidirectional Chains of Thought and Reward Mechanisms A Method for Enhancing Question-Answering Capabilities of Large Language Models for Chinese Intangible Cultural Heritage
May 14, 2025



The rapid development of large language models (LLMs) has provided significant support and opportunities for the advancement of domain-specific LLMs. However, fine-tuning these large models using Intangible Cultural Heritage (ICH) data inevitably faces challenges such as bias, incorrect knowledge inheritance, and catastrophic forgetting. To address these issues, we propose a novel training method that integrates a bidirectional chains of thought and a reward mechanism. This method is built upon ICH-Qwen, a large language model specifically designed for the field of intangible cultural heritage. The proposed method enables the model to not only perform forward reasoning but also enhances the accuracy of the generated answers by utilizing reverse questioning and reverse reasoning to activate the model's latent knowledge. Additionally, a reward mechanism is introduced during training to optimize the decision-making process. This mechanism improves the quality of the model's outputs through structural and content evaluations with different weighting schemes. We conduct comparative experiments on ICH-Qwen, with results demonstrating that our method outperforms 0-shot, step-by-step reasoning, knowledge distillation, and question augmentation methods in terms of accuracy, Bleu-4, and Rouge-L scores on the question-answering task. Furthermore, the paper highlights the effectiveness of combining the bidirectional chains of thought and reward mechanism through ablation experiments. In addition, a series of generalizability experiments are conducted, with results showing that the proposed method yields improvements on various domain-specific datasets and advanced models in areas such as Finance, Wikidata, and StrategyQA. This demonstrates that the method is adaptable to multiple domains and provides a valuable approach for model training in future applications across diverse fields.
From Data Quality to Model Quality: an Exploratory Study on Deep Learning
Jun 10, 2019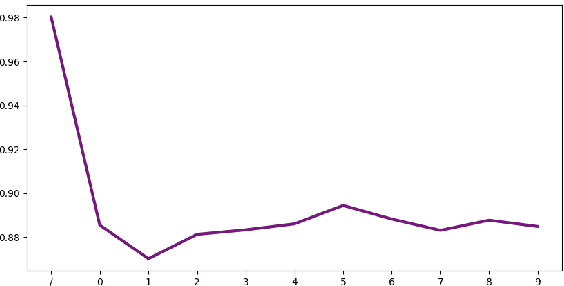
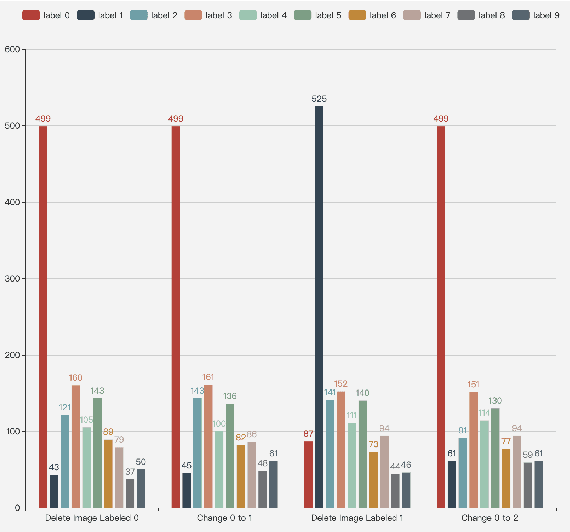
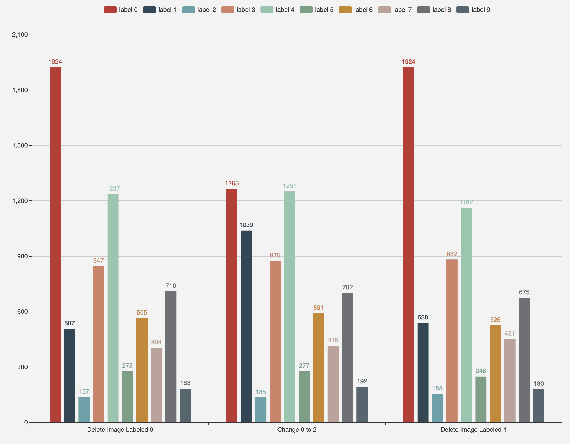
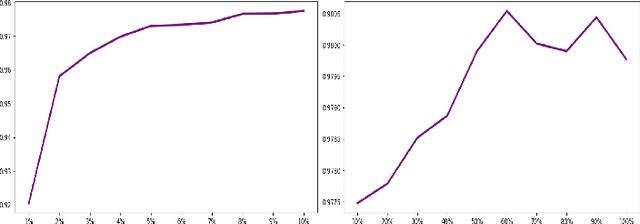
Nowadays, people strive to improve the accuracy of deep learning models. However, very little work has focused on the quality of data sets. In fact, data quality determines model quality. Therefore, it is important for us to make research on how data quality affects on model quality. In this paper, we mainly consider four aspects of data quality, including Dataset Equilibrium, Dataset Size, Quality of Label, Dataset Contamination. We deign experiment on MNIST and Cifar-10 and try to find out the influence the four aspects make on model quality. Experimental results show that four aspects all have decisive impact on the quality of models. It means that decrease in data quality in these aspects will reduce the accuracy of model.