 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
Learning to Evaluate Translation Beyond English: BLEURT Submissions to the WMT Metrics 2020 Shared Task
Oct 19, 2020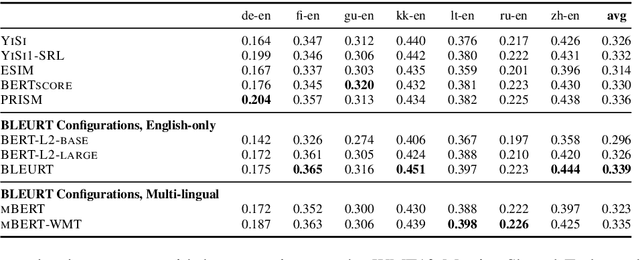
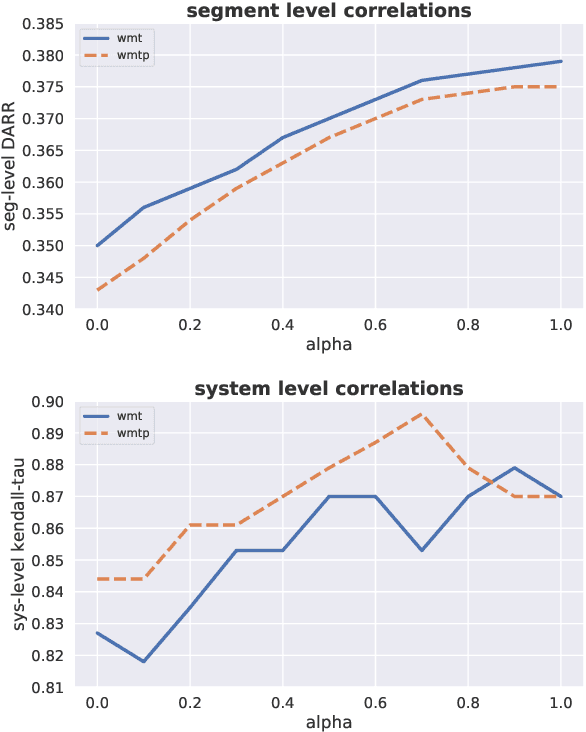
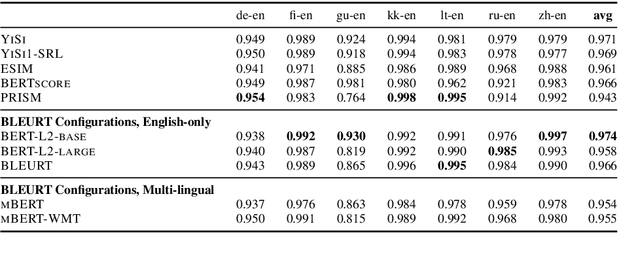
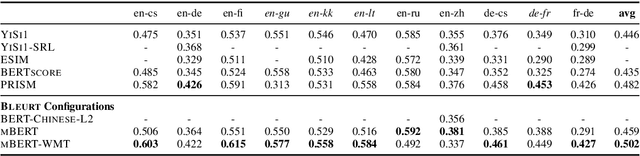
The quality of machine translation systems has dramatically improved over the last decade, and as a result, evaluation has become an increasingly challenging problem. This paper describes our contribution to the WMT 2020 Metrics Shared Task, the main benchmark for automatic evaluation of translation. We make several submissions based on BLEURT, a previously published metric based on transfer learning. We extend the metric beyond English and evaluate it on 14 language pairs for which fine-tuning data is available, as well as 4 "zero-shot" language pairs, for which we have no labelled examples. Additionally, we focus on English to German and demonstrate how to combine BLEURT's predictions with those of YiSi and use alternative reference translations to enhance the performance. Empirical results show that the models achieve competitive results on the WMT Metrics 2019 Shared Task, indicating their promise for the 2020 edition.
BLEURT: Learning Robust Metrics for Text Generation
May 14, 2020
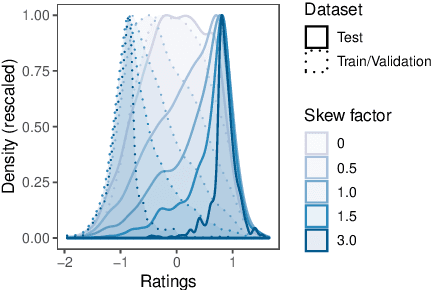
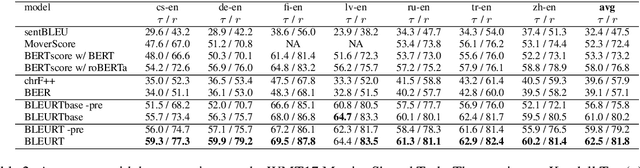
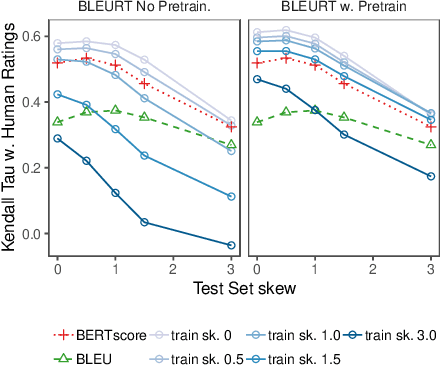
Text generation has made significant advances in the last few years. Yet, evaluation metrics have lagged behind, as the most popular choices (e.g., BLEU and ROUGE) may correlate poorly with human judgments. We propose BLEURT, a learned evaluation metric based on BERT that can model human judgments with a few thousand possibly biased training examples. A key aspect of our approach is a novel pre-training scheme that uses millions of synthetic examples to help the model generalize. BLEURT provides state-of-the-art results on the last three years of the WMT Metrics shared task and the WebNLG Competition dataset. In contrast to a vanilla BERT-based approach, it yields superior results even when the training data is scarce and out-of-distribution.
Variational Clustering: Leveraging Variational Autoencoders for Image Clustering
May 10, 2020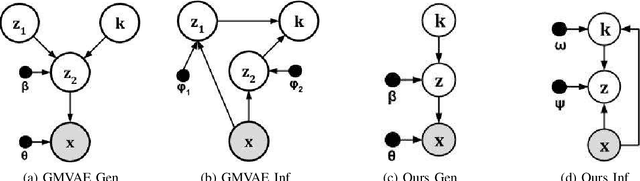
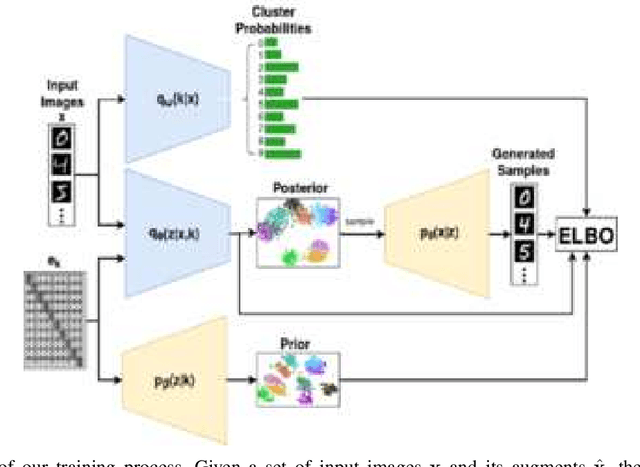
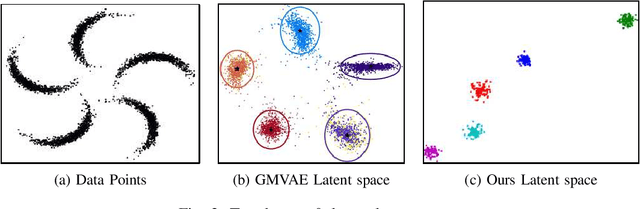
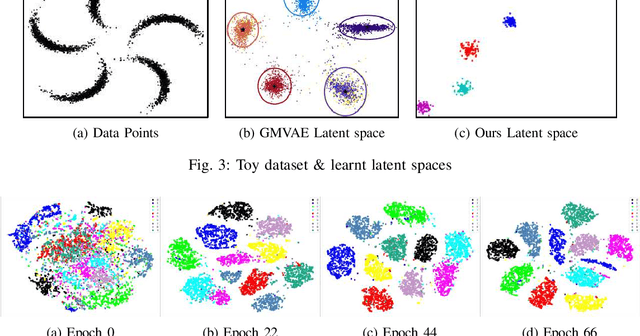
Recent advances in deep learning have shown their ability to learn strong feature representations for images. The task of image clustering naturally requires good feature representations to capture the distribution of the data and subsequently differentiate data points from one another. Often these two aspects are dealt with independently and thus traditional feature learning alone does not suffice in partitioning the data meaningfully. Variational Autoencoders (VAEs) naturally lend themselves to learning data distributions in a latent space. Since we wish to efficiently discriminate between different clusters in the data, we propose a method based on VAEs where we use a Gaussian Mixture prior to help cluster the images accurately. We jointly learn the parameters of both the prior and the posterior distributions. Our method represents a true Gaussian Mixture VAE. This way, our method simultaneously learns a prior that captures the latent distribution of the images and a posterior to help discriminate well between data points. We also propose a novel reparametrization of the latent space consisting of a mixture of discrete and continuous variables. One key takeaway is that our method generalizes better across different datasets without using any pre-training or learnt models, unlike existing methods, allowing it to be trained from scratch in an end-to-end manner. We verify our efficacy and generalizability experimentally by achieving state-of-the-art results among unsupervised methods on a variety of datasets. To the best of our knowledge, we are the first to pursue image clustering using VAEs in a purely unsupervised manner on real image datasets.
ToTTo: A Controlled Table-To-Text Generation Dataset
Apr 30, 2020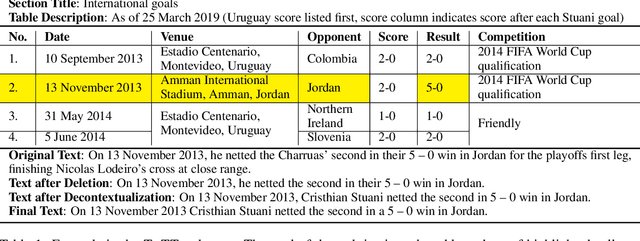
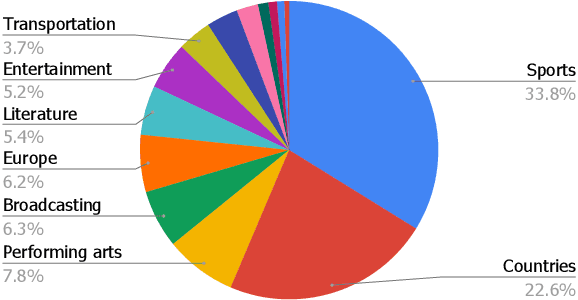

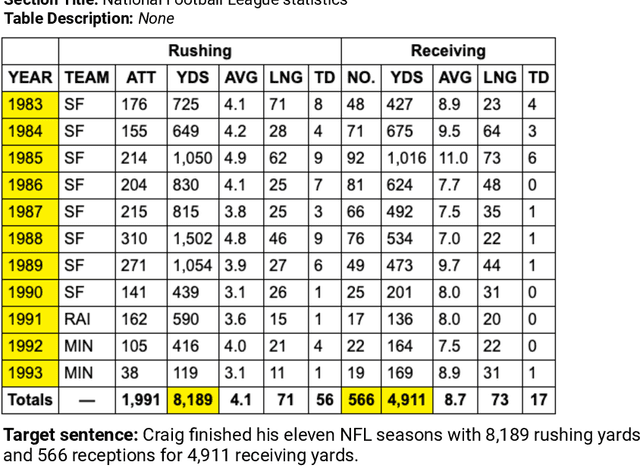
We present ToTTo, an open-domain English table-to-text dataset with over 120,000 training examples that proposes a controlled generation task: given a Wikipedia table and a set of highlighted table cells, produce a one-sentence description. To obtain generated targets that are natural but also faithful to the source table, we introduce a dataset construction process where annotators directly revise existing candidate sentences from Wikipedia. We present systematic analyses of our dataset and annotation process as well as results achieved by several state-of-the-art baselines. While usually fluent, existing methods often hallucinate phrases that are not supported by the table, suggesting that this dataset can serve as a useful research benchmark for high-precision conditional text generation.
Syntactic Data Augmentation Increases Robustness to Inference Heuristics
Apr 24, 2020
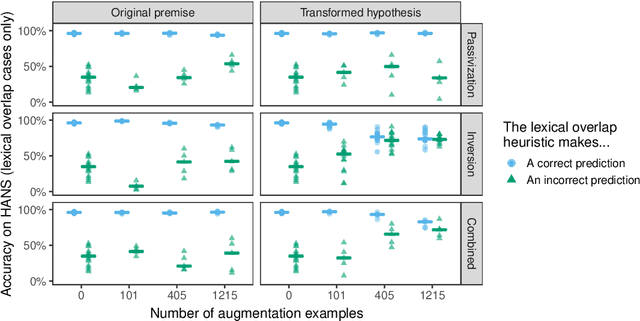
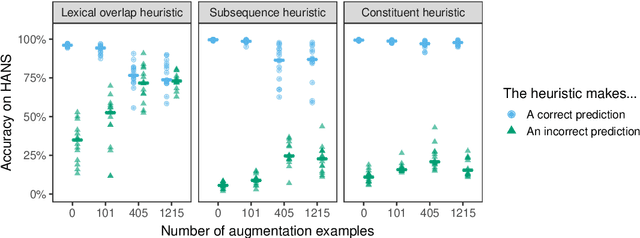

Pretrained neural models such as BERT, when fine-tuned to perform natural language inference (NLI), often show high accuracy on standard datasets, but display a surprising lack of sensitivity to word order on controlled challenge sets. We hypothesize that this issue is not primarily caused by the pretrained model's limitations, but rather by the paucity of crowdsourced NLI examples that might convey the importance of syntactic structure at the fine-tuning stage. We explore several methods to augment standard training sets with syntactically informative examples, generated by applying syntactic transformations to sentences from the MNLI corpus. The best-performing augmentation method, subject/object inversion, improved BERT's accuracy on controlled examples that diagnose sensitivity to word order from 0.28 to 0.73, without affecting performance on the MNLI test set. This improvement generalized beyond the particular construction used for data augmentation, suggesting that augmentation causes BERT to recruit abstract syntactic representations.
Handling Divergent Reference Texts when Evaluating Table-to-Text Generation
Jun 03, 2019


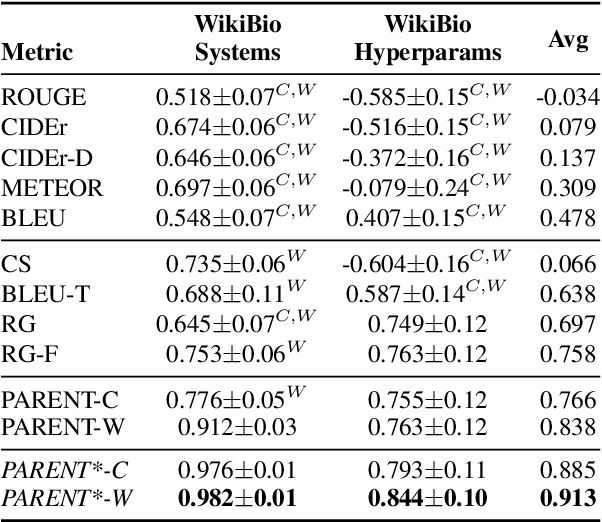
Automatically constructed datasets for generating text from semi-structured data (tables), such as WikiBio, often contain reference texts that diverge from the information in the corresponding semi-structured data. We show that metrics which rely solely on the reference texts, such as BLEU and ROUGE, show poor correlation with human judgments when those references diverge. We propose a new metric, PARENT, which aligns n-grams from the reference and generated texts to the semi-structured data before computing their precision and recall. Through a large scale human evaluation study of table-to-text models for WikiBio, we show that PARENT correlates with human judgments better than existing text generation metrics. We also adapt and evaluate the information extraction based evaluation proposed by Wiseman et al (2017), and show that PARENT has comparable correlation to it, while being easier to use. We show that PARENT is also applicable when the reference texts are elicited from humans using the data from the WebNLG challenge.
What do you learn from context? Probing for sentence structure in contextualized word representations
May 15, 2019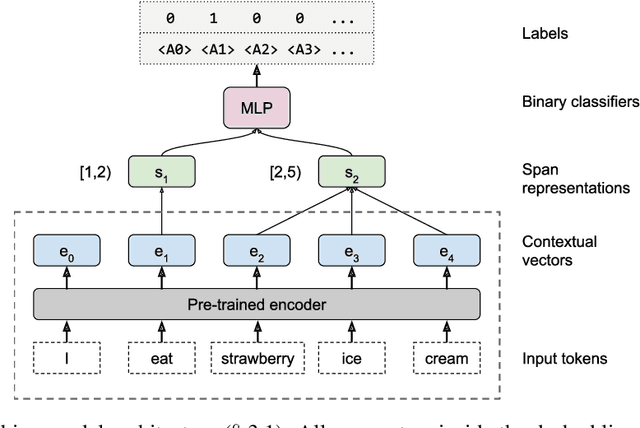

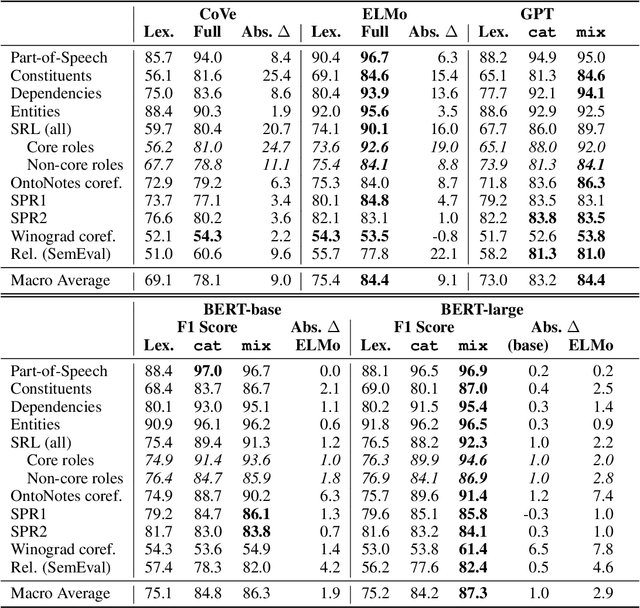
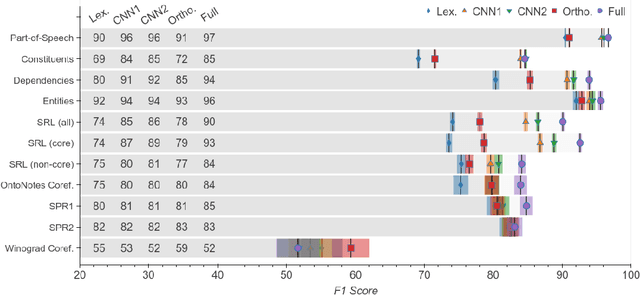
Contextualized representation models such as ELMo (Peters et al., 2018a) and BERT (Devlin et al., 2018) have recently achieved state-of-the-art results on a diverse array of downstream NLP tasks. Building on recent token-level probing work, we introduce a novel edge probing task design and construct a broad suite of sub-sentence tasks derived from the traditional structured NLP pipeline. We probe word-level contextual representations from four recent models and investigate how they encode sentence structure across a range of syntactic, semantic, local, and long-range phenomena. We find that existing models trained on language modeling and translation produce strong representations for syntactic phenomena, but only offer comparably small improvements on semantic tasks over a non-contextual baseline.
BERT Rediscovers the Classical NLP Pipeline
May 15, 2019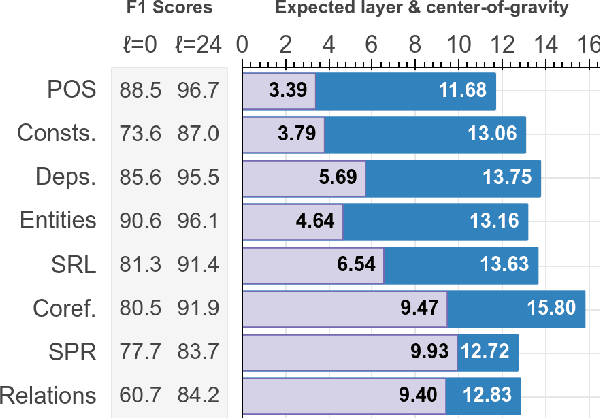
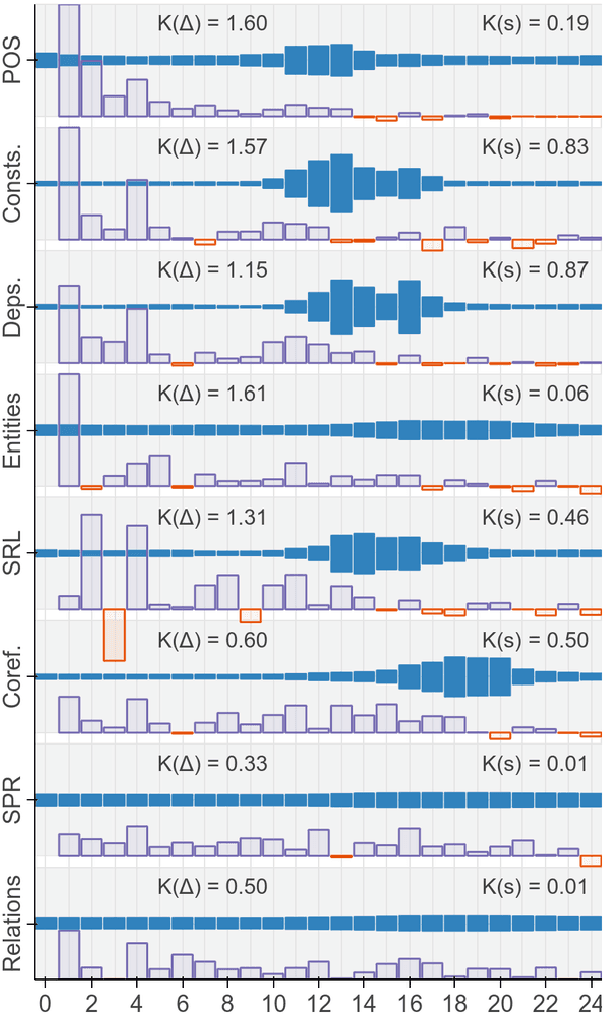
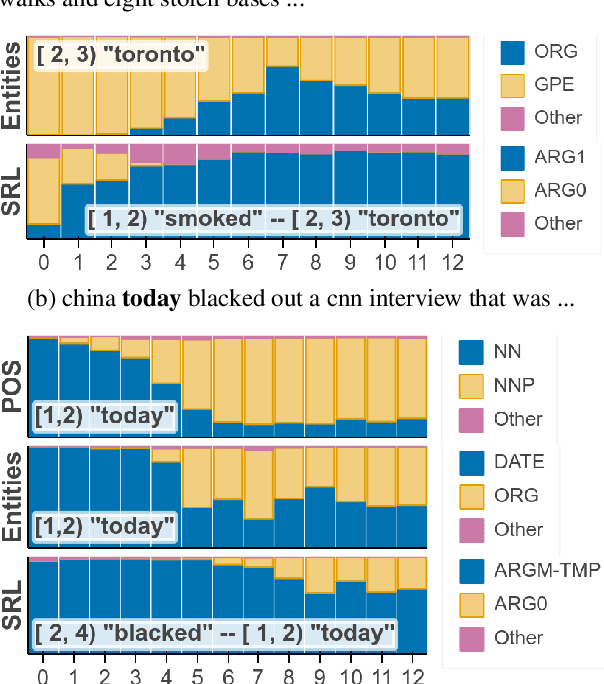
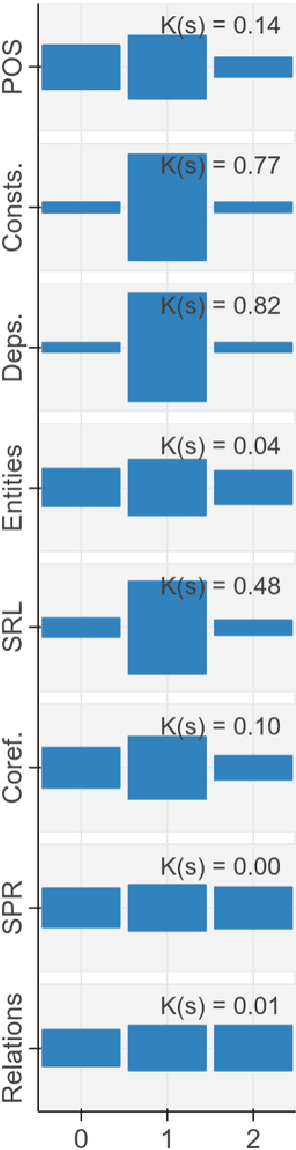
Pre-trained text encoders have rapidly advanced the state of the art on many NLP tasks. We focus on one such model, BERT, and aim to quantify where linguistic information is captured within the network. We find that the model represents the steps of the traditional NLP pipeline in an interpretable and localizable way, and that the regions responsible for each step appear in the expected sequence: POS tagging, parsing, NER, semantic roles, then coreference. Qualitative analysis reveals that the model can and often does adjust this pipeline dynamically, revising lower-level decisions on the basis of disambiguating information from higher-level representations.
Text Generation with Exemplar-based Adaptive Decoding
Apr 10, 2019
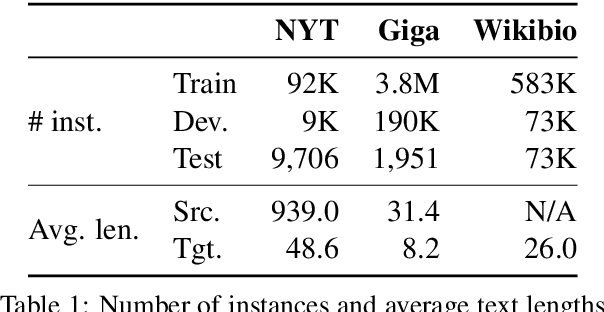
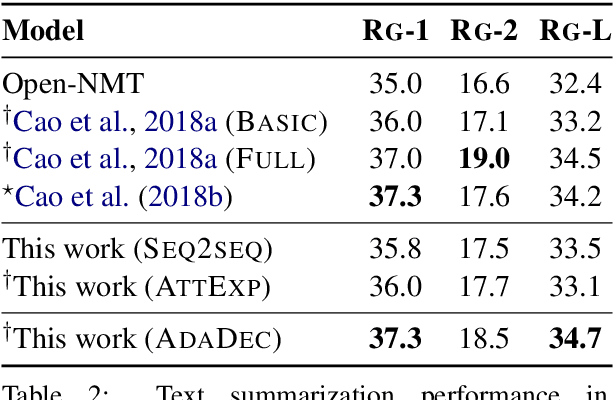
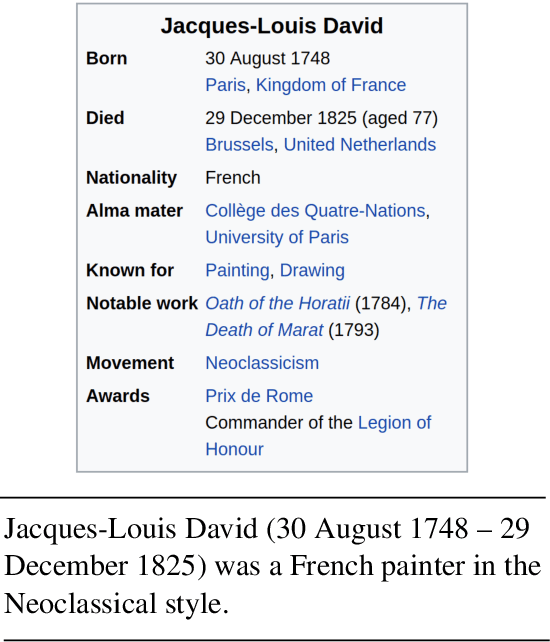
We propose a novel conditioned text generation model. It draws inspiration from traditional template-based text generation techniques, where the source provides the content (i.e., what to say), and the template influences how to say it. Building on the successful encoder-decoder paradigm, it first encodes the content representation from the given input text; to produce the output, it retrieves exemplar text from the training data as "soft templates," which are then used to construct an exemplar-specific decoder. We evaluate the proposed model on abstractive text summarization and data-to-text generation. Empirical results show that this model achieves strong performance and outperforms comparable baselines.