Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Generation with Exemplar-based Adaptive Decoding
Paper and Code

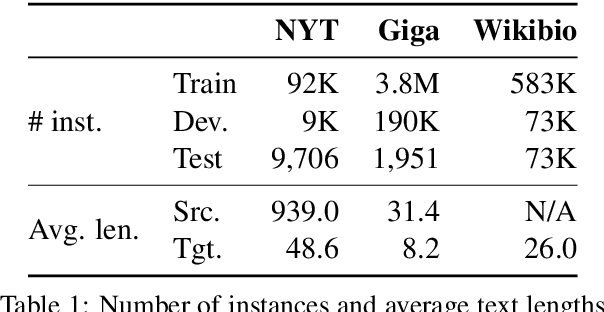
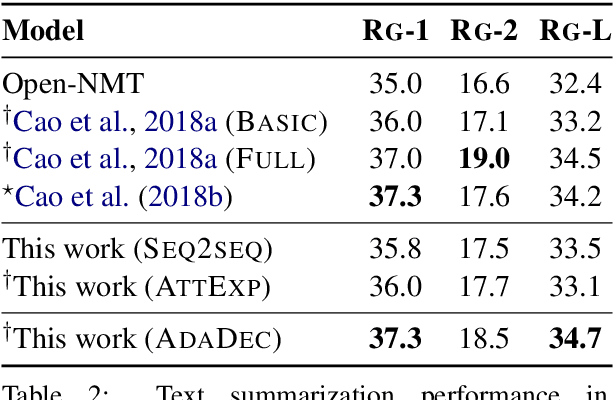
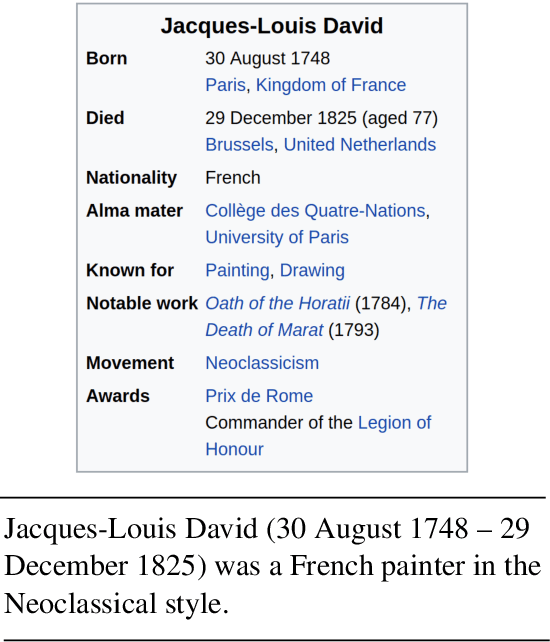
We propose a novel conditioned text generation model. It draws inspiration from traditional template-based text generation techniques, where the source provides the content (i.e., what to say), and the template influences how to say it. Building on the successful encoder-decoder paradigm, it first encodes the content representation from the given input text; to produce the output, it retrieves exemplar text from the training data as "soft templates," which are then used to construct an exemplar-specific decoder. We evaluate the proposed model on abstractive text summarization and data-to-text generation. Empirical results show that this model achieves strong performance and outperforms comparable baselines.
* NAACL 2019
View paper on