 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Oct 06, 2021


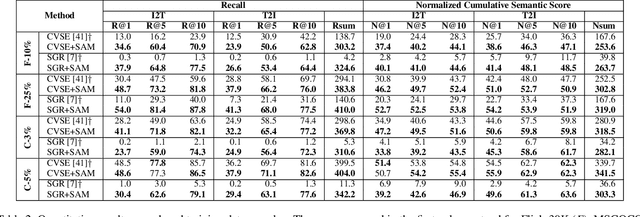
The task of image-text matching aims to map representations from different modalities into a common joint visual-textual embedding. However, the most widely used datasets for this task, MSCOCO and Flickr30K, are actually image captioning datasets that offer a very limited set of relationships between images and sentences in their ground-truth annotations. This limited ground truth information forces us to use evaluation metrics based on binary relevance: given a sentence query we consider only one image as relevant. However, many other relevant images or captions may be present in the dataset. In this work, we propose two metrics that evaluate the degree of semantic relevance of retrieved items, independently of their annotated binary relevance. Additionally, we incorporate a novel strategy that uses an image captioning metric, CIDEr, to define a Semantic Adaptive Margin (SAM) to be optimized in a standard triplet loss. By incorporating our formulation to existing models, a \emph{large} improvement is obtained in scenarios where available training data is limited. We also demonstrate that the performance on the annotated image-caption pairs is maintained while improving on other non-annotated relevant items when employing the full training set. Code with our metrics and adaptive margin formulation will be made public.
Let there be a clock on the beach: Reducing Object Hallucination in Image Captioning
Oct 04, 2021
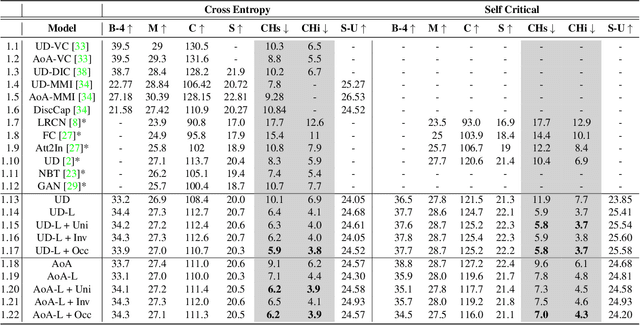
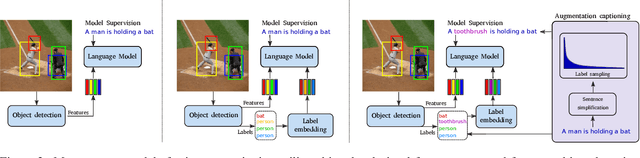

Explaining an image with missing or non-existent objects is known as object bias (hallucination) in image captioning. This behaviour is quite common in the state-of-the-art captioning models which is not desirable by humans. To decrease the object hallucination in captioning, we propose three simple yet efficient training augmentation method for sentences which requires no new training data or increase in the model size. By extensive analysis, we show that the proposed methods can significantly diminish our models' object bias on hallucination metrics. Moreover, we experimentally demonstrate that our methods decrease the dependency on the visual features. All of our code, configuration files and model weights will be made public.
Asking questions on handwritten document collections
Oct 02, 2021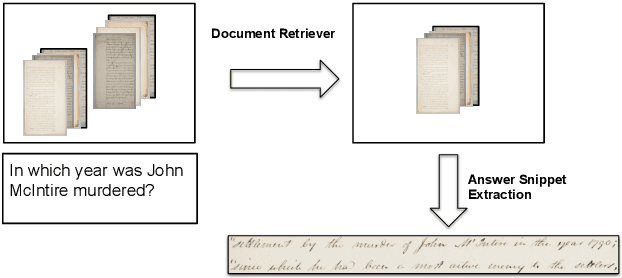

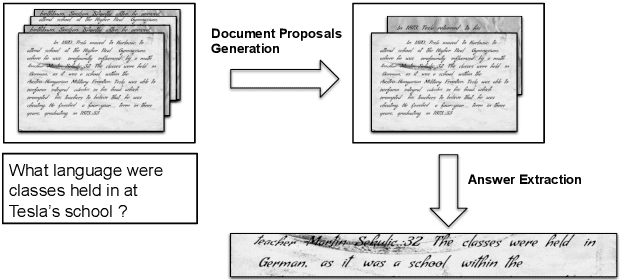

This work addresses the problem of Question Answering (QA) on handwritten document collections. Unlike typical QA and Visual Question Answering (VQA) formulations where the answer is a short text, we aim to locate a document snippet where the answer lies. The proposed approach works without recognizing the text in the documents. We argue that the recognition-free approach is suitable for handwritten documents and historical collections where robust text recognition is often difficult. At the same time, for human users, document image snippets containing answers act as a valid alternative to textual answers. The proposed approach uses an off-the-shelf deep embedding network which can project both textual words and word images into a common sub-space. This embedding bridges the textual and visual domains and helps us retrieve document snippets that potentially answer a question. We evaluate results of the proposed approach on two new datasets: (i) HW-SQuAD: a synthetic, handwritten document image counterpart of SQuAD1.0 dataset and (ii) BenthamQA: a smaller set of QA pairs defined on documents from the popular Bentham manuscripts collection. We also present a thorough analysis of the proposed recognition-free approach compared to a recognition-based approach which uses text recognized from the images using an OCR. Datasets presented in this work are available to download at docvqa.org
* pre-print version
One-shot Compositional Data Generation for Low Resource Handwritten Text Recognition
May 11, 2021
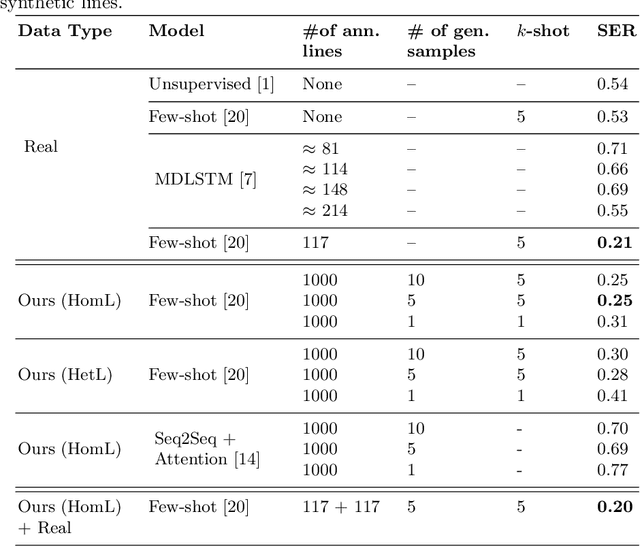
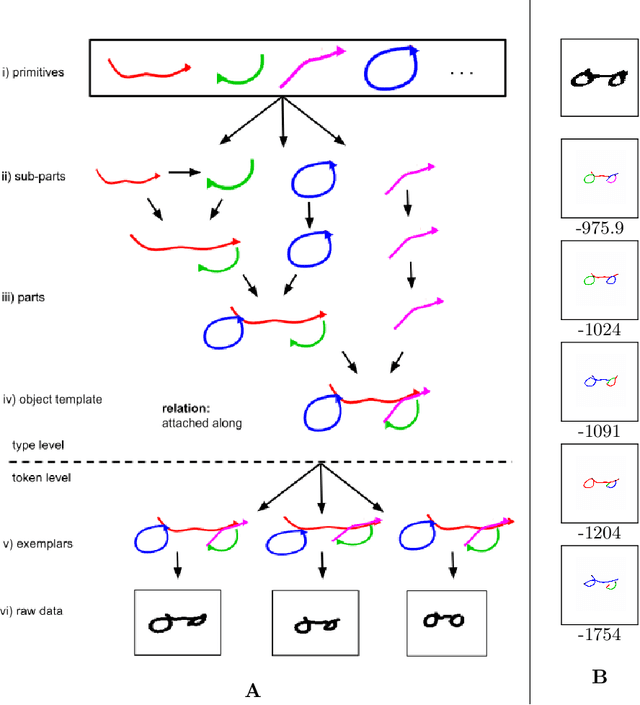

Low resource Handwritten Text Recognition (HTR) is a hard problem due to the scarce annotated data and the very limited linguistic information (dictionaries and language models). This appears, for example, in the case of historical ciphered manuscripts, which are usually written with invented alphabets to hide the content. Thus, in this paper we address this problem through a data generation technique based on Bayesian Program Learning (BPL). Contrary to traditional generation approaches, which require a huge amount of annotated images, our method is able to generate human-like handwriting using only one sample of each symbol from the desired alphabet. After generating symbols, we create synthetic lines to train state-of-the-art HTR architectures in a segmentation free fashion. Quantitative and qualitative analyses were carried out and confirm the effectiveness of the proposed method, achieving competitive results compared to the usage of real annotated data.
Document Collection Visual Question Answering
Apr 27, 2021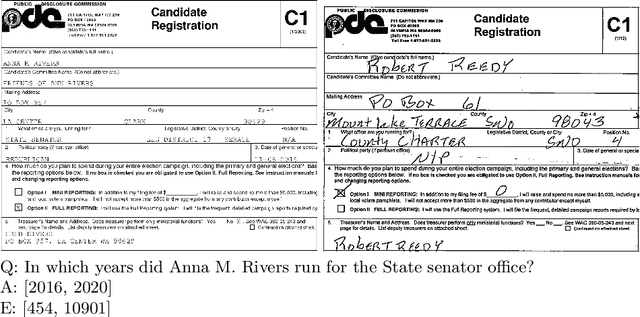
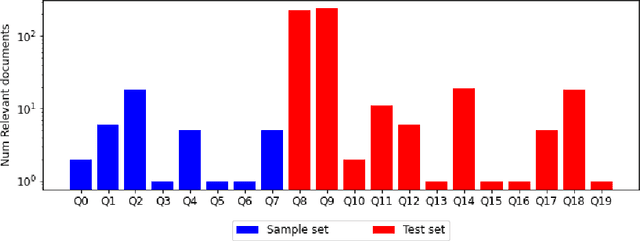


Current tasks and methods in Document Understanding aims to process documents as single elements. However, documents are usually organized in collections (historical records, purchase invoices), that provide context useful for their interpretation. To address this problem, we introduce Document Collection Visual Question Answering (DocCVQA) a new dataset and related task, where questions are posed over a whole collection of document images and the goal is not only to provide the answer to the given question, but also to retrieve the set of documents that contain the information needed to infer the answer. Along with the dataset we propose a new evaluation metric and baselines which provide further insights to the new dataset and task.
InfographicVQA
Apr 26, 2021
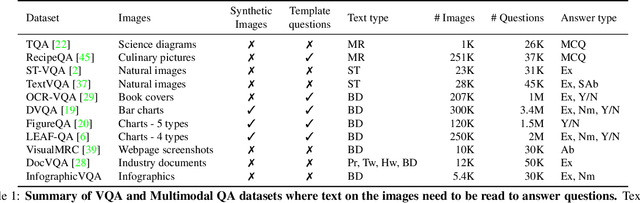
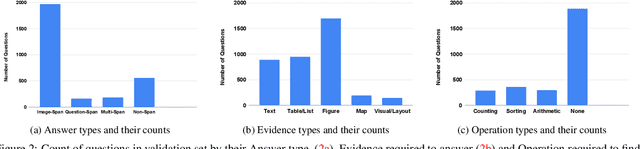
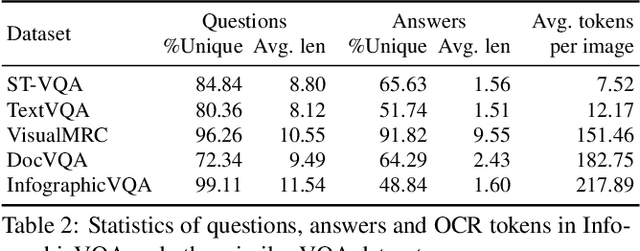
Infographics are documents designed to effectively communicate information using a combination of textual, graphical and visual elements. In this work, we explore the automatic understanding of infographic images by using Visual Question Answering technique.To this end, we present InfographicVQA, a new dataset that comprises a diverse collection of infographics along with natural language questions and answers annotations. The collected questions require methods to jointly reason over the document layout, textual content, graphical elements, and data visualizations. We curate the dataset with emphasis on questions that require elementary reasoning and basic arithmetic skills. Finally, we evaluate two strong baselines based on state of the art multi-modal VQA models, and establish baseline performance for the new task. The dataset, code and leaderboard will be made available at http://docvqa.org
ICDAR2019 Competition on Scanned Receipt OCR and Information Extraction
Mar 18, 2021
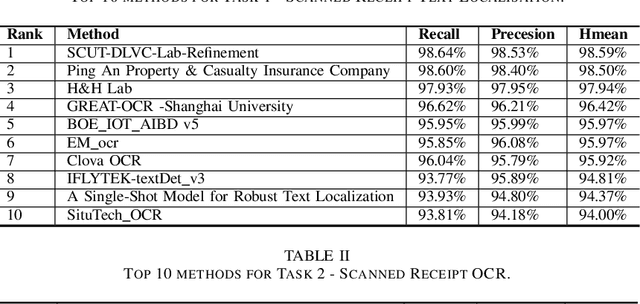
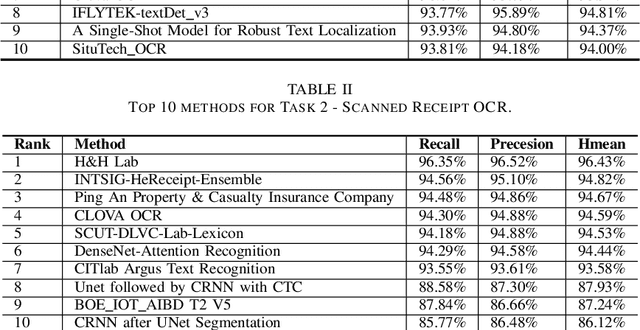
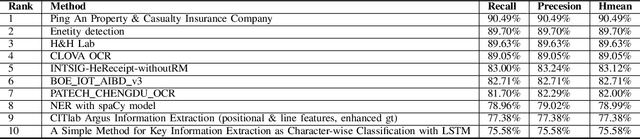
Scanned receipts OCR and key information extraction (SROIE) represent the processeses of recognizing text from scanned receipts and extracting key texts from them and save the extracted tests to structured documents. SROIE plays critical roles for many document analysis applications and holds great commercial potentials, but very little research works and advances have been published in this area. In recognition of the technical challenges, importance and huge commercial potentials of SROIE, we organized the ICDAR 2019 competition on SROIE. In this competition, we set up three tasks, namely, Scanned Receipt Text Localisation (Task 1), Scanned Receipt OCR (Task 2) and Key Information Extraction from Scanned Receipts (Task 3). A new dataset with 1000 whole scanned receipt images and annotations is created for the competition. In this report we will presents the motivation, competition datasets, task definition, evaluation protocol, submission statistics, performance of submitted methods and results analysis.
StacMR: Scene-Text Aware Cross-Modal Retrieval
Dec 08, 2020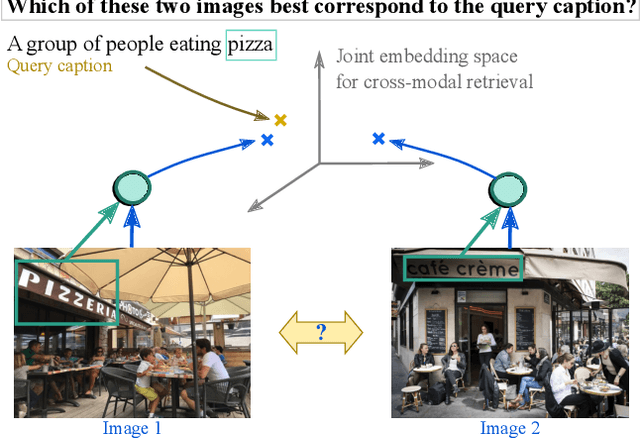

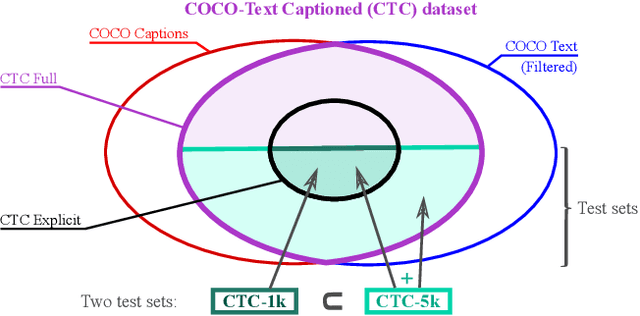
Recent models for cross-modal retrieval have benefited from an increasingly rich understanding of visual scenes, afforded by scene graphs and object interactions to mention a few. This has resulted in an improved matching between the visual representation of an image and the textual representation of its caption. Yet, current visual representations overlook a key aspect: the text appearing in images, which may contain crucial information for retrieval. In this paper, we first propose a new dataset that allows exploration of cross-modal retrieval where images contain scene-text instances. Then, armed with this dataset, we describe several approaches which leverage scene text, including a better scene-text aware cross-modal retrieval method which uses specialized representations for text from the captions and text from the visual scene, and reconcile them in a common embedding space. Extensive experiments confirm that cross-modal retrieval approaches benefit from scene text and highlight interesting research questions worth exploring further. Dataset and code are available at http://europe.naverlabs.com/stacmr
Multi-Modal Reasoning Graph for Scene-Text Based Fine-Grained Image Classification and Retrieval
Sep 21, 2020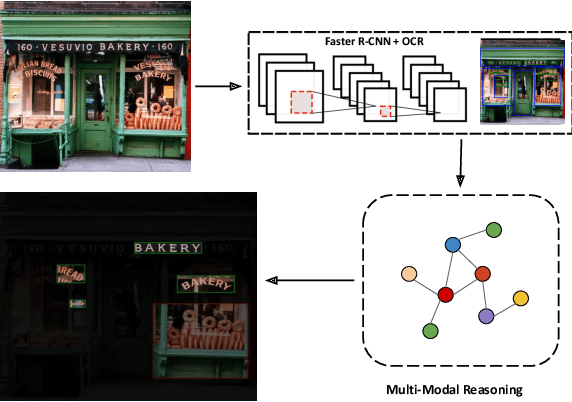
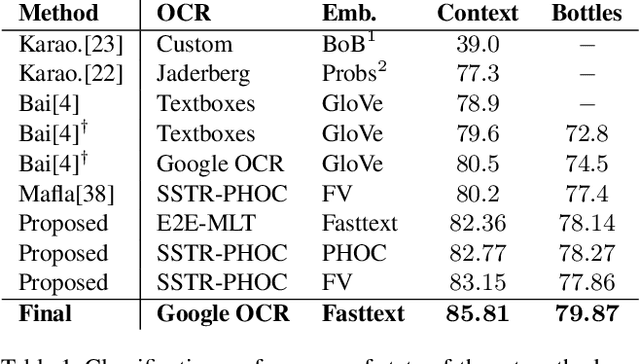
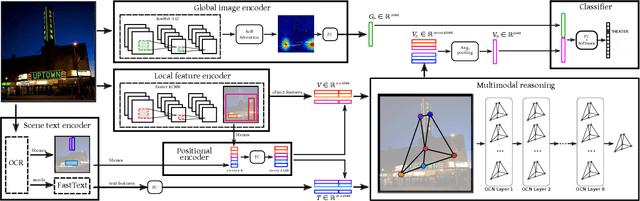
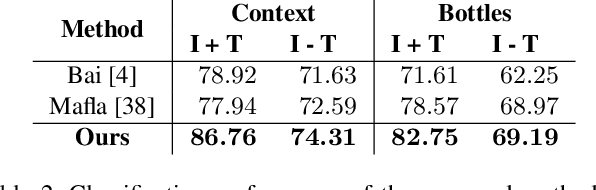
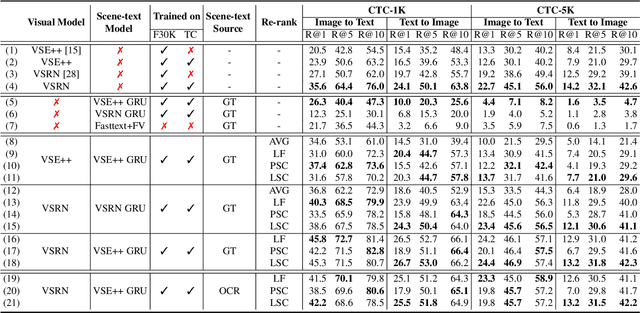
Scene text instances found in natural images carry explicit semantic information that can provide important cues to solve a wide array of computer vision problems. In this paper, we focus on leveraging multi-modal content in the form of visual and textual cues to tackle the task of fine-grained image classification and retrieval. First, we obtain the text instances from images by employing a text reading system. Then, we combine textual features with salient image regions to exploit the complementary information carried by the two sources. Specifically, we employ a Graph Convolutional Network to perform multi-modal reasoning and obtain relationship-enhanced features by learning a common semantic space between salient objects and text found in an image. By obtaining an enhanced set of visual and textual features, the proposed model greatly outperforms the previous state-of-the-art in two different tasks, fine-grained classification and image retrieval in the Con-Text and Drink Bottle datasets.
Document Visual Question Answering Challenge 2020
Aug 20, 2020
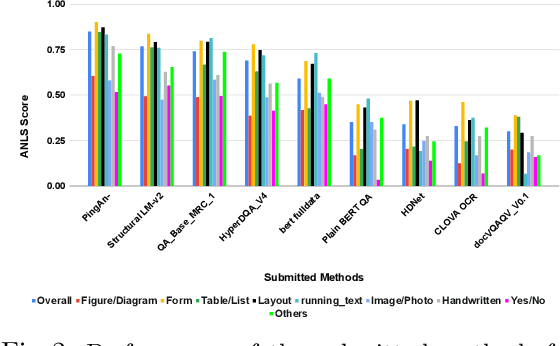
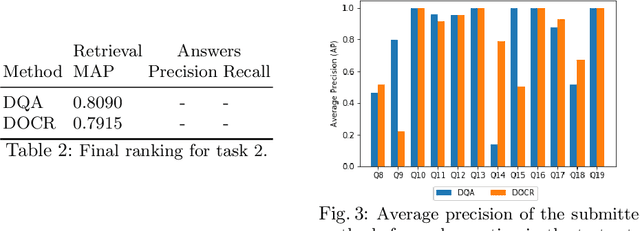
This paper presents results of Document Visual Question Answering Challenge organized as part of "Text and Documents in the Deep Learning Era" workshop, in CVPR 2020. The challenge introduces a new problem - Visual Question Answering on document images. The challenge comprised two tasks. The first task concerns with asking questions on a single document image. On the other hand, the second task is set as a retrieval task where the question is posed over a collection of images. For the task 1 a new dataset is introduced comprising 50,000 questions-answer(s) pairs defined over 12,767 document images. For task 2 another dataset has been created comprising 20 questions over 14,362 document images which share the same document template.