 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid unary-binary design for multiplier-less printed Machine Learning classifiers
Sep 18, 2025Printed Electronics (PE) provide a flexible, cost-efficient alternative to silicon for implementing machine learning (ML) circuits, but their large feature sizes limit classifier complexity. Leveraging PE's low fabrication and NRE costs, designers can tailor hardware to specific ML models, simplifying circuit design. This work explores alternative arithmetic and proposes a hybrid unary-binary architecture that removes costly encoders and enables efficient, multiplier-less execution of MLP classifiers. We also introduce architecture-aware training to further improve area and power efficiency. Evaluation on six datasets shows average reductions of 46% in area and 39% in power, with minimal accuracy loss, surpassing other state-of-the-art MLP designs.
MaRVIn: A Cross-Layer Mixed-Precision RISC-V Framework for DNN Inference, from ISA Extension to Hardware Acceleration
Sep 18, 2025The evolution of quantization and mixed-precision techniques has unlocked new possibilities for enhancing the speed and energy efficiency of NNs. Several recent studies indicate that adapting precision levels across different parameters can maintain accuracy comparable to full-precision models while significantly reducing computational demands. However, existing embedded microprocessors lack sufficient architectural support for efficiently executing mixed-precision NNs, both in terms of ISA extensions and hardware design, resulting in inefficiencies such as excessive data packing/unpacking and underutilized arithmetic units. In this work, we propose novel ISA extensions and a micro-architecture implementation specifically designed to optimize mixed-precision execution, enabling energy-efficient deep learning inference on RISC-V architectures. We introduce MaRVIn, a cross-layer hardware-software co-design framework that enhances power efficiency and performance through a combination of hardware improvements, mixed-precision quantization, ISA-level optimizations, and cycle-accurate emulation. At the hardware level, we enhance the ALU with configurable mixed-precision arithmetic (2, 4, 8 bits) for weights/activations and employ multi-pumping to reduce execution latency while implementing soft SIMD for efficient 2-bit ops. At the software level, we integrate a pruning-aware fine-tuning method to optimize model compression and a greedy-based DSE approach to efficiently search for Pareto-optimal mixed-quantized models. Additionally, we incorporate voltage scaling to boost the power efficiency of our system. Our experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 17.6x speedup for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores, delivering up to 1.8 TOPs/W.
Accelerating TinyML Inference on Microcontrollers through Approximate Kernels
Sep 25, 2024



The rapid growth of microcontroller-based IoT devices has opened up numerous applications, from smart manufacturing to personalized healthcare. Despite the widespread adoption of energy-efficient microcontroller units (MCUs) in the Tiny Machine Learning (TinyML) domain, they still face significant limitations in terms of performance and memory (RAM, Flash). In this work, we combine approximate computing and software kernel design to accelerate the inference of approximate CNN models on MCUs. Our kernel-based approximation framework firstly unpacks the operands of each convolution layer and then conducts an offline calculation to determine the significance of each operand. Subsequently, through a design space exploration, it employs a computation skipping approximation strategy based on the calculated significance. Our evaluation on an STM32-Nucleo board and 2 popular CNNs trained on the CIFAR-10 dataset shows that, compared to state-of-the-art exact inference, our Pareto optimal solutions can feature on average 21% latency reduction with no degradation in Top-1 classification accuracy, while for lower accuracy requirements, the corresponding reduction becomes even more pronounced.
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Jul 19, 2024



Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
On-sensor Printed Machine Learning Classification via Bespoke ADC and Decision Tree Co-Design
Dec 02, 2023



Printed electronics (PE) technology provides cost-effective hardware with unmet customization, due to their low non-recurring engineering and fabrication costs. PE exhibit features such as flexibility, stretchability, porosity, and conformality, which make them a prominent candidate for enabling ubiquitous computing. Still, the large feature sizes in PE limit the realization of complex printed circuits, such as machine learning classifiers, especially when processing sensor inputs is necessary, mainly due to the costly analog-to-digital converters (ADCs). To this end, we propose the design of fully customized ADCs and present, for the first time, a co-design framework for generating bespoke Decision Tree classifiers. Our comprehensive evaluation shows that our co-design enables self-powered operation of on-sensor printed classifiers in all benchmark cases.
Approximate Computing Survey, Part II: Application-Specific & Architectural Approximation Techniques and Applications
Jul 20, 2023



The challenging deployment of compute-intensive applications from domains such Artificial Intelligence (AI) and Digital Signal Processing (DSP), forces the community of computing systems to explore new design approaches. Approximate Computing appears as an emerging solution, allowing to tune the quality of results in the design of a system in order to improve the energy efficiency and/or performance. This radical paradigm shift has attracted interest from both academia and industry, resulting in significant research on approximation techniques and methodologies at different design layers (from system down to integrated circuits). Motivated by the wide appeal of Approximate Computing over the last 10 years, we conduct a two-part survey to cover key aspects (e.g., terminology and applications) and review the state-of-the art approximation techniques from all layers of the traditional computing stack. In Part II of our survey, we classify and present the technical details of application-specific and architectural approximation techniques, which both target the design of resource-efficient processors/accelerators & systems. Moreover, we present a detailed analysis of the application spectrum of Approximate Computing and discuss open challenges and future directions.
Model-to-Circuit Cross-Approximation For Printed Machine Learning Classifiers
Mar 14, 2023



Printed electronics (PE) promises on-demand fabrication, low non-recurring engineering costs, and sub-cent fabrication costs. It also allows for high customization that would be infeasible in silicon, and bespoke architectures prevail to improve the efficiency of emerging PE machine learning (ML) applications. Nevertheless, large feature sizes in PE prohibit the realization of complex ML models in PE, even with bespoke architectures. In this work, we present an automated, cross-layer approximation framework tailored to bespoke architectures that enable complex ML models, such as Multi-Layer Perceptrons (MLPs) and Support Vector Machines (SVMs), in PE. Our framework adopts cooperatively a hardware-driven coefficient approximation of the ML model at algorithmic level, a netlist pruning at logic level, and a voltage over-scaling at the circuit level. Extensive experimental evaluation on 12 MLPs and 12 SVMs and more than 6000 approximate and exact designs demonstrates that our model-to-circuit cross-approximation delivers power and area optimal designs that, compared to the state-of-the-art exact designs, feature on average 51% and 66% area and power reduction, respectively, for less than 5% accuracy loss. Finally, we demonstrate that our framework enables 80% of the examined classifiers to be battery-powered with almost identical accuracy with the exact designs, paving thus the way towards smart complex printed applications.
Co-Design of Approximate Multilayer Perceptron for Ultra-Resource Constrained Printed Circuits
Feb 28, 2023



Printed Electronics (PE) exhibits on-demand, extremely low-cost hardware due to its additive manufacturing process, enabling machine learning (ML) applications for domains that feature ultra-low cost, conformity, and non-toxicity requirements that silicon-based systems cannot deliver. Nevertheless, large feature sizes in PE prohibit the realization of complex printed ML circuits. In this work, we present, for the first time, an automated printed-aware software/hardware co-design framework that exploits approximate computing principles to enable ultra-resource constrained printed multilayer perceptrons (MLPs). Our evaluation demonstrates that, compared to the state-of-the-art baseline, our circuits feature on average 6x (5.7x) lower area (power) and less than 1% accuracy loss.
Hardware Approximate Techniques for Deep Neural Network Accelerators: A Survey
Mar 16, 2022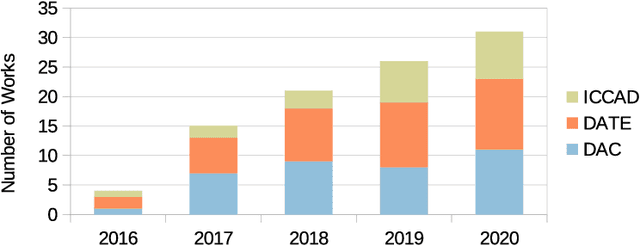
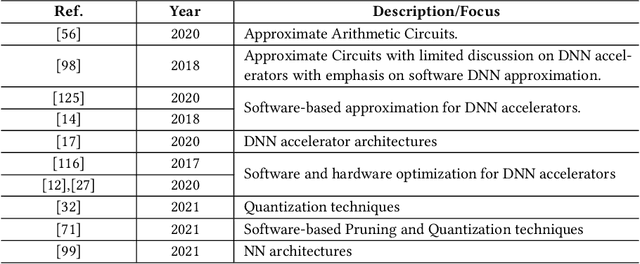
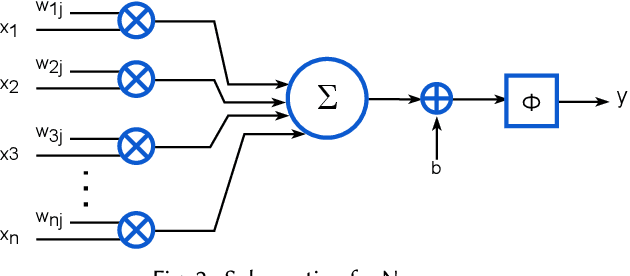
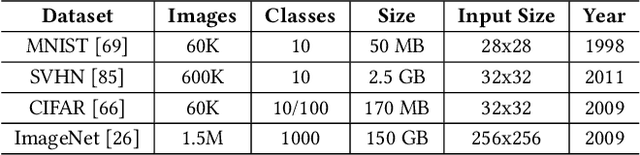
Deep Neural Networks (DNNs) are very popular because of their high performance in various cognitive tasks in Machine Learning (ML). Recent advancements in DNNs have brought beyond human accuracy in many tasks, but at the cost of high computational complexity. To enable efficient execution of DNN inference, more and more research works, therefore, exploit the inherent error resilience of DNNs and employ Approximate Computing (AC) principles to address the elevated energy demands of DNN accelerators. This article provides a comprehensive survey and analysis of hardware approximation techniques for DNN accelerators. First, we analyze the state of the art and by identifying approximation families, we cluster the respective works with respect to the approximation type. Next, we analyze the complexity of the performed evaluations (with respect to the dataset and DNN size) to assess the efficiency, the potential, and limitations of approximate DNN accelerators. Moreover, a broad discussion is provided, regarding error metrics that are more suitable for designing approximate units for DNN accelerators as well as accuracy recovery approaches that are tailored to DNN inference. Finally, we present how Approximate Computing for DNN accelerators can go beyond energy efficiency and address reliability and security issues, as well.
* This paper has been accepted by ACM Computing Surveys (CSUR), 2022
Cross-Layer Approximation For Printed Machine Learning Circuits
Mar 11, 2022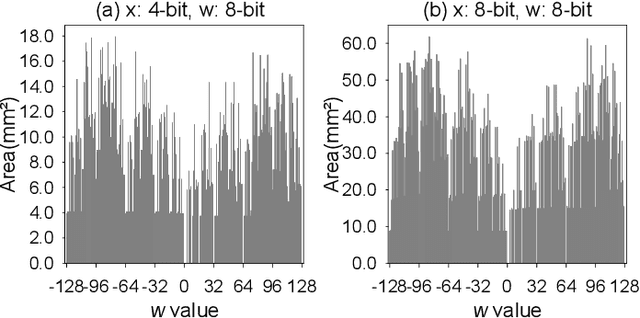
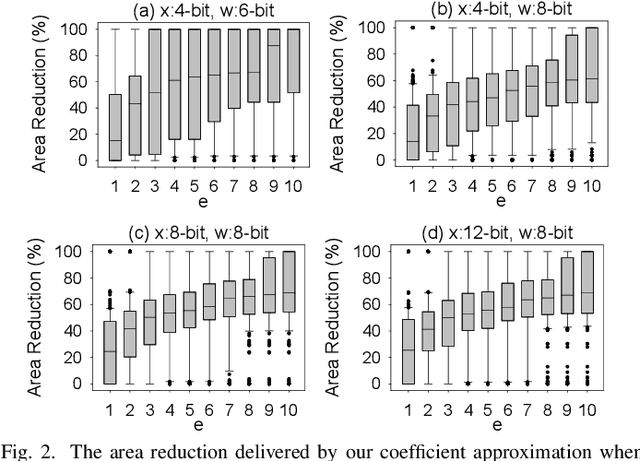
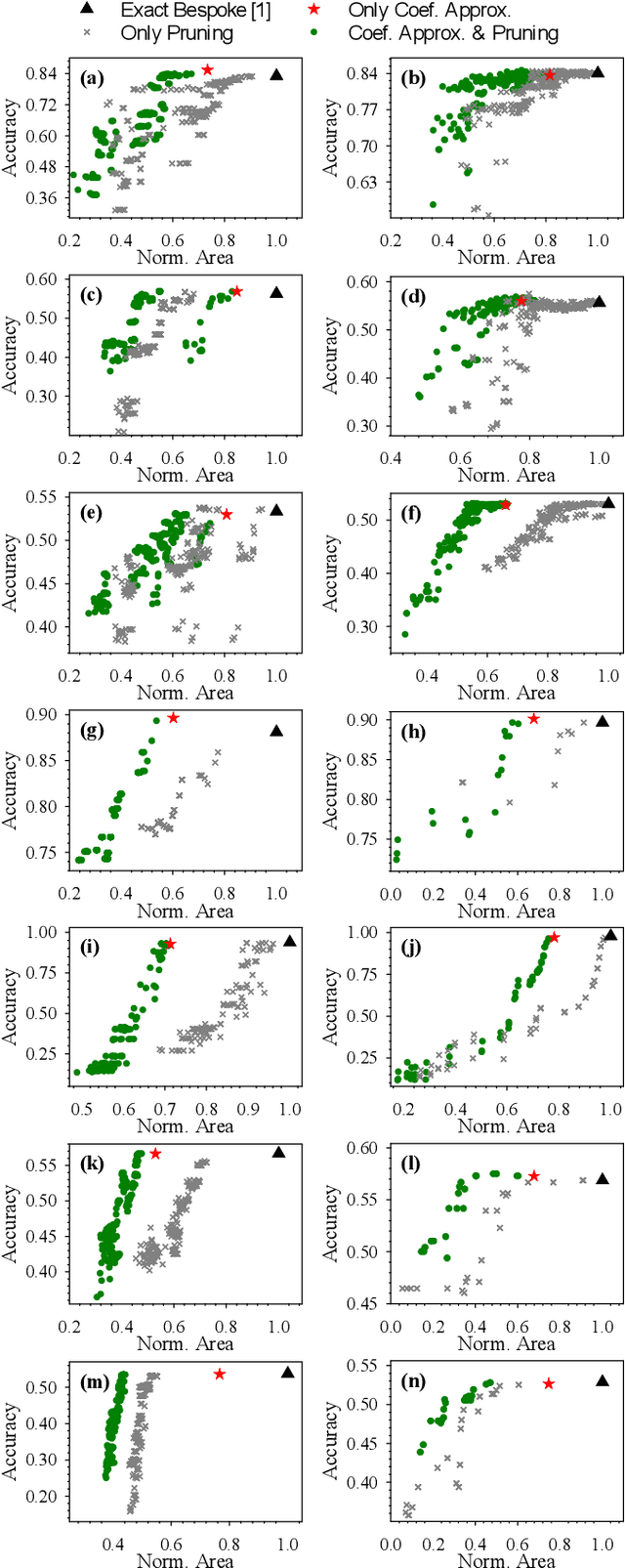
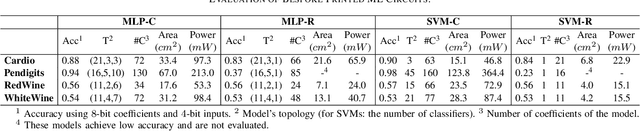
Printed electronics (PE) feature low non-recurring engineering costs and low per unit-area fabrication costs, enabling thus extremely low-cost and on-demand hardware. Such low-cost fabrication allows for high customization that would be infeasible in silicon, and bespoke architectures prevail to improve the efficiency of emerging PE machine learning (ML) applications. However, even with bespoke architectures, the large feature sizes in PE constraint the complexity of the ML models that can be implemented. In this work, we bring together, for the first time, approximate computing and PE design targeting to enable complex ML models, such as Multi-Layer Perceptrons (MLPs) and Support Vector Machines (SVMs), in PE. To this end, we propose and implement a cross-layer approximation, tailored for bespoke ML architectures. At the algorithmic level we apply a hardware-driven coefficient approximation of the ML model and at the circuit level we apply a netlist pruning through a full search exploration. In our extensive experimental evaluation we consider 14 MLPs and SVMs and evaluate more than 4300 approximate and exact designs. Our results demonstrate that our cross approximation delivers Pareto optimal designs that, compared to the state-of-the-art exact designs, feature 47% and 44% average area and power reduction, respectively, and less than 1% accuracy loss.