 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting temporal parallelism for LSTM Autoencoder acceleration on FPGA
Mar 14, 2026Recurrent Neural Networks (RNNs) are vital for sequential data processing. Long Short-Term Memory Autoencoders (LSTM-AEs) are particularly effective for unsupervised anomaly detection in time-series data. However, inherent sequential dependencies limit parallel computation. While previous work has explored FPGA-based acceleration for LSTM networks, efforts have typically focused on optimizing a single LSTM layer at a time. We introduce a novel FPGA-based accelerator using a dataflow architecture that exploits temporal parallelism for concurrent multi-layer processing of different timesteps within sequences. Experimental evaluations on four representative LSTM-AE models with varying widths and depths, implemented on a Zynq UltraScale+ MPSoC FPGA, demonstrate significant advantages over CPU (Intel Xeon Gold 5218R) and GPU (NVIDIA V100) implementations. Our accelerator achieves latency speedups up to 79.6x vs. CPU and 18.2x vs. GPU, alongside energy-per-timestep reductions of up to 1722x vs. CPU and 59.3x vs. GPU. These results, including superior network depth scalability, highlight our approach's potential for high-performance, real-time, power-efficient LSTM-AE-based anomaly detection on FPGAs.
SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving
Aug 05, 2024



As Large Language Models (LLMs) gain traction, their reliance on power-hungry GPUs places ever-increasing energy demands, raising environmental and monetary concerns. Inference dominates LLM workloads, presenting a critical challenge for providers: minimizing energy costs under Service-Level Objectives (SLOs) that ensure optimal user experience. In this paper, we present \textit{throttLL'eM}, a framework that reduces energy consumption while meeting SLOs through the use of instance and GPU frequency scaling. \textit{throttLL'eM} features mechanisms that project future KV cache usage and batch size. Leveraging a Machine-Learning (ML) model that receives these projections as inputs, \textit{throttLL'eM} manages performance at the iteration level to satisfy SLOs with reduced frequencies and instance sizes. We show that the proposed ML model achieves $R^2$ scores greater than 0.97 and miss-predicts performance by less than 1 iteration per second on average. Experimental results on LLM inference traces show that \textit{throttLL'eM} achieves up to 43.8\% lower energy consumption and an energy efficiency improvement of at least $1.71\times$ under SLOs, when compared to NVIDIA's Triton server.
Towards making the most of NLP-based device mapping optimization for OpenCL kernels
Aug 30, 2022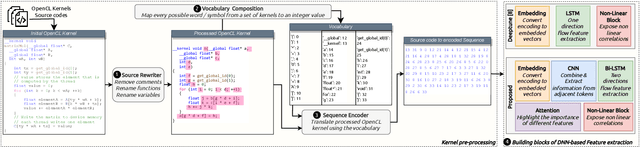
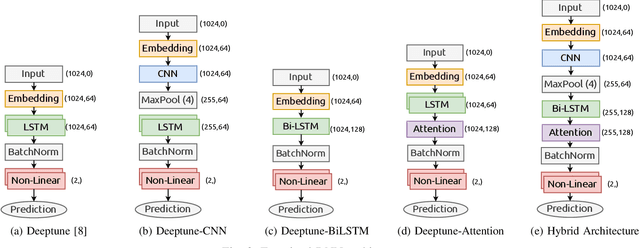
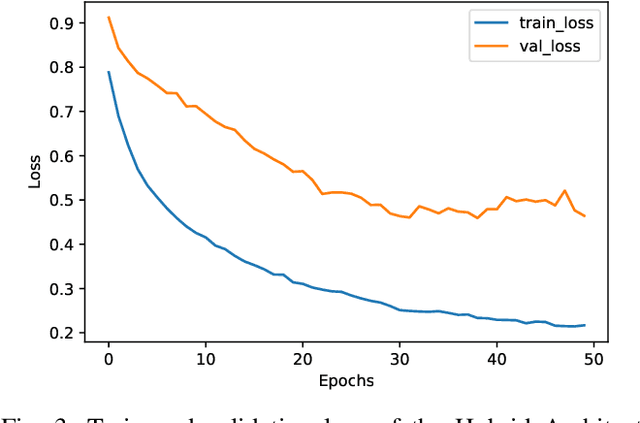
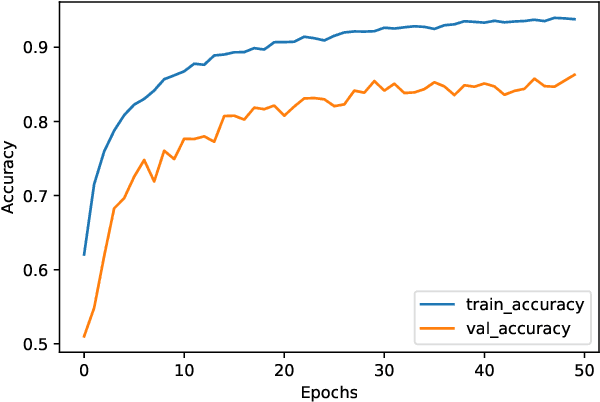
Nowadays, we are living in an era of extreme device heterogeneity. Despite the high variety of conventional CPU architectures, accelerator devices, such as GPUs and FPGAs, also appear in the foreground exploding the pool of available solutions to execute applications. However, choosing the appropriate device per application needs is an extremely challenging task due to the abstract relationship between hardware and software. Automatic optimization algorithms that are accurate are required to cope with the complexity and variety of current hardware and software. Optimal execution has always relied on time-consuming trial and error approaches. Machine learning (ML) and Natural Language Processing (NLP) has flourished over the last decade with research focusing on deep architectures. In this context, the use of natural language processing techniques to source code in order to conduct autotuning tasks is an emerging field of study. In this paper, we extend the work of Cummins et al., namely Deeptune, that tackles the problem of optimal device selection (CPU or GPU) for accelerated OpenCL kernels. We identify three major limitations of Deeptune and, based on these, we propose four different DNN models that provide enhanced contextual information of source codes. Experimental results show that our proposed methodology surpasses that of Cummins et al. work, providing up to 4\% improvement in prediction accuracy.
* Accepted at IEEE COINS 2022