 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBi-level Heterogeneous Learning for Time Series Foundation Models: A Federated Learning Approach
Apr 08, 2026Heterogeneity in time series data is more pronounced than in vision or language, as temporal dynamics vary substantially across domains and tasks. Existing efforts on training time series foundation models (TSFMs) from scratch are often trained with mixed-batch strategies that merge large-scale datasets, which can cause gradient conflicts and degrade representation quality. To address this, we propose a fine-grained learning method that distills invariant knowledge from heterogeneous series while reducing cross-domain interference. We characterize heterogeneity at two levels: inter-domain and intra-domain. To tackle this bi-level heterogeneity, we design a federated learning method that mitigates intra-domain conflicts by enforcing domain-invariant and semantically consistent representations through local regularization, and addresses inter-domain discrepancies by enhancing cross-domain collaboration via domain-aware aggregation. Experiments across diverse benchmarks show that TSFMs trained with our method consistently outperform both centralized and federated TSFM baselines in point and probabilistic forecasting, while also achieving competitive zero-shot performance at scale, offering a flexible pathway for training TSFMs from scratch in heterogeneous environments.
Unified Locomotion Transformer with Simultaneous Sim-to-Real Transfer for Quadrupeds
Mar 12, 2025



Quadrupeds have gained rapid advancement in their capability of traversing across complex terrains. The adoption of deep Reinforcement Learning (RL), transformers and various knowledge transfer techniques can greatly reduce the sim-to-real gap. However, the classical teacher-student framework commonly used in existing locomotion policies requires a pre-trained teacher and leverages the privilege information to guide the student policy. With the implementation of large-scale models in robotics controllers, especially transformers-based ones, this knowledge distillation technique starts to show its weakness in efficiency, due to the requirement of multiple supervised stages. In this paper, we propose Unified Locomotion Transformer (ULT), a new transformer-based framework to unify the processes of knowledge transfer and policy optimization in a single network while still taking advantage of privilege information. The policies are optimized with reinforcement learning, next state-action prediction, and action imitation, all in just one training stage, to achieve zero-shot deployment. Evaluation results demonstrate that with ULT, optimal teacher and student policies can be obtained at the same time, greatly easing the difficulty in knowledge transfer, even with complex transformer-based models.
Improving Trust Estimation in Human-Robot Collaboration Using Beta Reputation at Fine-grained Timescales
Nov 04, 2024



When interacting with each other, humans adjust their behavior based on perceived trust. However, to achieve similar adaptability, robots must accurately estimate human trust at sufficiently granular timescales during the human-robot collaboration task. A beta reputation is a popular way to formalize a mathematical estimation of human trust. However, it relies on binary performance, which updates trust estimations only after each task concludes. Additionally, manually crafting a reward function is the usual method of building a performance indicator, which is labor-intensive and time-consuming. These limitations prevent efficiently capturing continuous changes in trust at more granular timescales throughout the collaboration task. Therefore, this paper presents a new framework for the estimation of human trust using a beta reputation at fine-grained timescales. To achieve granularity in beta reputation, we utilize continuous reward values to update trust estimations at each timestep of a task. We construct a continuous reward function using maximum entropy optimization to eliminate the need for the laborious specification of a performance indicator. The proposed framework improves trust estimations by increasing accuracy, eliminating the need for manually crafting a reward function, and advancing toward developing more intelligent robots. The source code is publicly available. https://github.com/resuldagdanov/robot-learning-human-trust
Masked Sensory-Temporal Attention for Sensor Generalization in Quadruped Locomotion
Sep 05, 2024



With the rising focus on quadrupeds, a generalized policy capable of handling different robot models and sensory inputs will be highly beneficial. Although several methods have been proposed to address different morphologies, it remains a challenge for learning-based policies to manage various combinations of proprioceptive information. This paper presents Masked Sensory-Temporal Attention (MSTA), a novel transformer-based model with masking for quadruped locomotion. It employs direct sensor-level attention to enhance sensory-temporal understanding and handle different combinations of sensor data, serving as a foundation for incorporating unseen information. This model can effectively understand its states even with a large portion of missing information, and is flexible enough to be deployed on a physical system despite the long input sequence.
Foundation Models for Weather and Climate Data Understanding: A Comprehensive Survey
Dec 05, 2023As artificial intelligence (AI) continues to rapidly evolve, the realm of Earth and atmospheric sciences is increasingly adopting data-driven models, powered by progressive developments in deep learning (DL). Specifically, DL techniques are extensively utilized to decode the chaotic and nonlinear aspects of Earth systems, and to address climate challenges via understanding weather and climate data. Cutting-edge performance on specific tasks within narrower spatio-temporal scales has been achieved recently through DL. The rise of large models, specifically large language models (LLMs), has enabled fine-tuning processes that yield remarkable outcomes across various downstream tasks, thereby propelling the advancement of general AI. However, we are still navigating the initial stages of crafting general AI for weather and climate. In this survey, we offer an exhaustive, timely overview of state-of-the-art AI methodologies specifically engineered for weather and climate data, with a special focus on time series and text data. Our primary coverage encompasses four critical aspects: types of weather and climate data, principal model architectures, model scopes and applications, and datasets for weather and climate. Furthermore, in relation to the creation and application of foundation models for weather and climate data understanding, we delve into the field's prevailing challenges, offer crucial insights, and propose detailed avenues for future research. This comprehensive approach equips practitioners with the requisite knowledge to make substantial progress in this domain. Our survey encapsulates the most recent breakthroughs in research on large, data-driven models for weather and climate data understanding, emphasizing robust foundations, current advancements, practical applications, crucial resources, and prospective research opportunities.
Neuroadaptation in Physical Human-Robot Collaboration
Sep 30, 2023



Robots for physical Human-Robot Collaboration (pHRC) systems need to change their behavior and how they operate in consideration of several factors, such as the performance and intention of a human co-worker and the capabilities of different human-co-workers in collision avoidance and singularity of the robot operation. As the system's admittance becomes variable throughout the workspace, a potential solution is to tune the interaction forces and control the parameters based on the operator's requirements. To overcome this issue, we have demonstrated a novel closed-loop-neuroadaptive framework for pHRC. We have applied cognitive conflict information in a closed-loop manner, with the help of reinforcement learning, to adapt to robot strategy and compare this with open-loop settings. The experiment results show that the closed-loop-based neuroadaptive framework successfully reduces the level of cognitive conflict during pHRC, consequently increasing the smoothness and intuitiveness of human-robot collaboration. These results suggest the feasibility of a neuroadaptive approach for future pHRC control systems through electroencephalogram (EEG) signals.
A novel model for layer jamming-based continuum robots
Sep 11, 2023



Continuum robots with variable stiffness have gained wide popularity in the last decade. Layer jamming (LJ) has emerged as a simple and efficient technique to achieve tunable stiffness for continuum robots. Despite its merits, the development of a control-oriented dynamical model tailored for this specific class of robots remains an open problem in the literature. This paper aims to present the first solution, to the best of our knowledge, to close the gap. We propose an energy-based model that is integrated with the LuGre frictional model for LJ-based continuum robots. Then, we take a comprehensive theoretical analysis for this model, focusing on two fundamental characteristics of LJ-based continuum robots: shape locking and adjustable stiffness. To validate the modeling approach and theoretical results, a series of experiments using our \textit{OctRobot-I} continuum robotic platform was conducted. The results show that the proposed model is capable of interpreting and predicting the dynamical behaviors in LJ-based continuum robots.
Towards Building AI-CPS with NVIDIA Isaac Sim: An Industrial Benchmark and Case Study for Robotics Manipulation
Jul 31, 2023



As a representative cyber-physical system (CPS), robotic manipulator has been widely adopted in various academic research and industrial processes, indicating its potential to act as a universal interface between the cyber and the physical worlds. Recent studies in robotics manipulation have started employing artificial intelligence (AI) approaches as controllers to achieve better adaptability and performance. However, the inherent challenge of explaining AI components introduces uncertainty and unreliability to these AI-enabled robotics systems, necessitating a reliable development platform for system design and performance assessment. As a foundational step towards building reliable AI-enabled robotics systems, we propose a public industrial benchmark for robotics manipulation in this paper. It leverages NVIDIA Omniverse Isaac Sim as the simulation platform, encompassing eight representative manipulation tasks and multiple AI software controllers. An extensive evaluation is conducted to analyze the performance of AI controllers in solving robotics manipulation tasks, enabling a thorough understanding of their effectiveness. To further demonstrate the applicability of our benchmark, we develop a falsification framework that is compatible with physical simulators and OpenAI Gym environments. This framework bridges the gap between traditional testing methods and modern physics engine-based simulations. The effectiveness of different optimization methods in falsifying AI-enabled robotics manipulation with physical simulators is examined via a falsification test. Our work not only establishes a foundation for the design and development of AI-enabled robotics systems but also provides practical experience and guidance to practitioners in this field, promoting further research in this critical academic and industrial domain.
Simultaneous Position-and-Stiffness Control of Underactuated Antagonistic Tendon-Driven Continuum Robots
Jun 06, 2023Continuum robots have gained widespread popularity due to their inherent compliance and flexibility, particularly their adjustable levels of stiffness for various application scenarios. Despite efforts to dynamic modeling and control synthesis over the past decade, few studies have focused on incorporating stiffness regulation in their feedback control design; however, this is one of the initial motivations to develop continuum robots. This paper aims to address the crucial challenge of controlling both the position and stiffness of a class of highly underactuated continuum robots that are actuated by antagonistic tendons. To this end, the first step involves presenting a high-dimensional rigid-link dynamical model that can analyze the open-loop stiffening of tendon-driven continuum robots. Based on this model, we propose a novel passivity-based position-and-stiffness controller adheres to the non-negative tension constraint. To demonstrate the effectiveness of our approach, we tested the theoretical results on our continuum robot, and the experimental results show the efficacy and precise performance of the proposed methodology.
Saving the Limping: Fault-tolerant Quadruped Locomotion via Reinforcement Learning
Oct 02, 2022
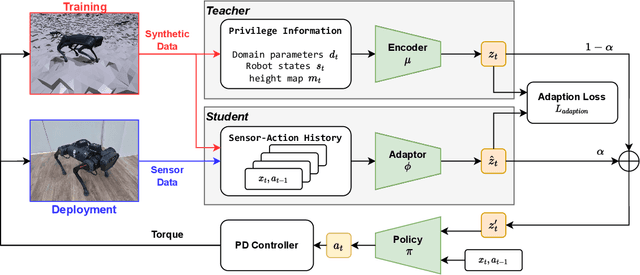

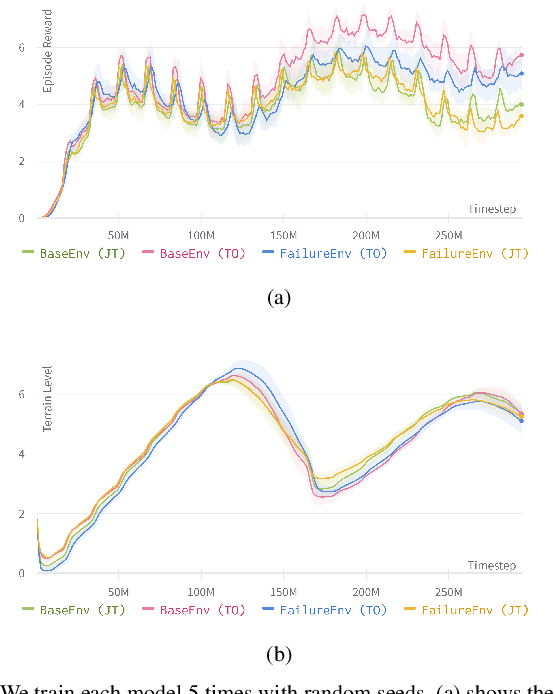
Quadruped locomotion now has acquired the skill to traverse or even sprint on uneven terrains in remote uncontrolled environment. However, surviving in the wild requires not only the maneuverability, but also the ability to handle unexpected hardware failures. We present the first deep reinforcement learning based methodology to train fault-tolerant controllers, which can bring an injured quadruped back home safely and speedily. We adopt the teacher-student framework to train the controller with close-to-reality joint-locking failure in the simulation, which can be zero-shot transferred to the physical robot without any fine-tuning. Extensive simulation and real-world experiments demonstrate that our fault-tolerant controller can efficiently lead a quadruped stably when it faces joint failure during locomotion.