 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid AI Methodology for Generating Ontologies of Research Topics from Scientific Paper Corpora
Aug 06, 2025

Taxonomies and ontologies of research topics (e.g., MeSH, UMLS, CSO, NLM) play a central role in providing the primary framework through which intelligent systems can explore and interpret the literature. However, these resources have traditionally been manually curated, a process that is time-consuming, prone to obsolescence, and limited in granularity. This paper presents Sci-OG, a semi-auto\-mated methodology for generating research topic ontologies, employing a multi-step approach: 1) Topic Discovery, extracting potential topics from research papers; 2) Relationship Classification, determining semantic relationships between topic pairs; and 3) Ontology Construction, refining and organizing topics into a structured ontology. The relationship classification component, which constitutes the core of the system, integrates an encoder-based language model with features describing topic occurrence in the scientific literature. We evaluate this approach against a range of alternative solutions using a dataset of 21,649 manually annotated semantic triples. Our method achieves the highest F1 score (0.951), surpassing various competing approaches, including a fine-tuned SciBERT model and several LLM baselines, such as the fine-tuned GPT4-mini. Our work is corroborated by a use case which illustrates the practical application of our system to extend the CSO ontology in the area of cybersecurity. The presented solution is designed to improve the accessibility, organization, and analysis of scientific knowledge, thereby supporting advancements in AI-enabled literature management and research exploration.
A Comparative Study of Task Adaptation Techniques of Large Language Models for Identifying Sustainable Development Goals
Jun 18, 2025In 2012, the United Nations introduced 17 Sustainable Development Goals (SDGs) aimed at creating a more sustainable and improved future by 2030. However, tracking progress toward these goals is difficult because of the extensive scale and complexity of the data involved. Text classification models have become vital tools in this area, automating the analysis of vast amounts of text from a variety of sources. Additionally, large language models (LLMs) have recently proven indispensable for many natural language processing tasks, including text classification, thanks to their ability to recognize complex linguistic patterns and semantics. This study analyzes various proprietary and open-source LLMs for a single-label, multi-class text classification task focused on the SDGs. Then, it also evaluates the effectiveness of task adaptation techniques (i.e., in-context learning approaches), namely Zero-Shot and Few-Shot Learning, as well as Fine-Tuning within this domain. The results reveal that smaller models, when optimized through prompt engineering, can perform on par with larger models like OpenAI's GPT (Generative Pre-trained Transformer).
Extending the SAREF4ENER Ontology with Flexibility Based on FlexOffers
Apr 04, 2025



A key element to support the increased amounts of renewable energy in the energy system is flexibility, i.e., the possibility of changing energy loads in time and amount. Many flexibility models have been designed; however, exact models fail to scale for long time horizons or many devices. Because of this, the FlexOffer (FOs) model has been designed, to provide device-independent approximations of flexibility with good accuracy, and much better scaling for long time horizons and many devices. An important aspect of the real-life implementation of energy flexibility is enabling flexible data exchange with many types of smart energy appliances and market systems, e.g., in smart buildings. For this, ontologies standardizing data formats are required. However, the current industry standard ontology for integrating smart devices for energy purposes, SAREF for Energy Flexibility (SAREF4ENER) only has limited support for flexibility and thus cannot support important use cases. In this paper we propose an extension of SAREF4ENER that integrates full support for the complete FlexOffer model, including advanced use cases, while maintaining backward compatibility. This novel ontology module can accurately describe flexibility for advanced devices such as electric vehicles, batteries, and heat pumps. It can also capture the inherent uncertainty associated with many flexible load types.
Unlocking LLMs: Addressing Scarce Data and Bias Challenges in Mental Health
Dec 17, 2024



Large language models (LLMs) have shown promising capabilities in healthcare analysis but face several challenges like hallucinations, parroting, and bias manifestation. These challenges are exacerbated in complex, sensitive, and low-resource domains. Therefore, in this work we introduce IC-AnnoMI, an expert-annotated motivational interviewing (MI) dataset built upon AnnoMI by generating in-context conversational dialogues leveraging LLMs, particularly ChatGPT. IC-AnnoMI employs targeted prompts accurately engineered through cues and tailored information, taking into account therapy style (empathy, reflection), contextual relevance, and false semantic change. Subsequently, the dialogues are annotated by experts, strictly adhering to the Motivational Interviewing Skills Code (MISC), focusing on both the psychological and linguistic dimensions of MI dialogues. We comprehensively evaluate the IC-AnnoMI dataset and ChatGPT's emotional reasoning ability and understanding of domain intricacies by modeling novel classification tasks employing several classical machine learning and current state-of-the-art transformer approaches. Finally, we discuss the effects of progressive prompting strategies and the impact of augmented data in mitigating the biases manifested in IC-AnnoM. Our contributions provide the MI community with not only a comprehensive dataset but also valuable insights for using LLMs in empathetic text generation for conversational therapy in supervised settings.
Triplètoile: Extraction of Knowledge from Microblogging Text
Aug 27, 2024



Numerous methods and pipelines have recently emerged for the automatic extraction of knowledge graphs from documents such as scientific publications and patents. However, adapting these methods to incorporate alternative text sources like micro-blogging posts and news has proven challenging as they struggle to model open-domain entities and relations, typically found in these sources. In this paper, we propose an enhanced information extraction pipeline tailored to the extraction of a knowledge graph comprising open-domain entities from micro-blogging posts on social media platforms. Our pipeline leverages dependency parsing and classifies entity relations in an unsupervised manner through hierarchical clustering over word embeddings. We provide a use case on extracting semantic triples from a corpus of 100 thousand tweets about digital transformation and publicly release the generated knowledge graph. On the same dataset, we conduct two experimental evaluations, showing that the system produces triples with precision over 95% and outperforms similar pipelines of around 5% in terms of precision, while generating a comparatively higher number of triples.
* 42 pages, 6 figures
PhilHumans: Benchmarking Machine Learning for Personal Health
May 04, 2024



The use of machine learning in Healthcare has the potential to improve patient outcomes as well as broaden the reach and affordability of Healthcare. The history of other application areas indicates that strong benchmarks are essential for the development of intelligent systems. We present Personal Health Interfaces Leveraging HUman-MAchine Natural interactions (PhilHumans), a holistic suite of benchmarks for machine learning across different Healthcare settings - talk therapy, diet coaching, emergency care, intensive care, obstetric sonography - as well as different learning settings, such as action anticipation, timeseries modeling, insight mining, language modeling, computer vision, reinforcement learning and program synthesis
Ask the experts: sourcing high-quality datasets for nutritional counselling through Human-AI collaboration
Jan 16, 2024Large Language Models (LLMs), with their flexible generation abilities, can be powerful data sources in domains with few or no available corpora. However, problems like hallucinations and biases limit such applications. In this case study, we pick nutrition counselling, a domain lacking any public resource, and show that high-quality datasets can be gathered by combining LLMs, crowd-workers and nutrition experts. We first crowd-source and cluster a novel dataset of diet-related issues, then work with experts to prompt ChatGPT into producing related supportive text. Finally, we let the experts evaluate the safety of the generated text. We release HAI-coaching, the first expert-annotated nutrition counselling dataset containing ~2.4K dietary struggles from crowd workers, and ~97K related supportive texts generated by ChatGPT. Extensive analysis shows that ChatGPT while producing highly fluent and human-like text, also manifests harmful behaviours, especially in sensitive topics like mental health, making it unsuitable for unsupervised use.
Human-Centric Artificial Intelligence Architecture for Industry 5.0 Applications
Mar 21, 2022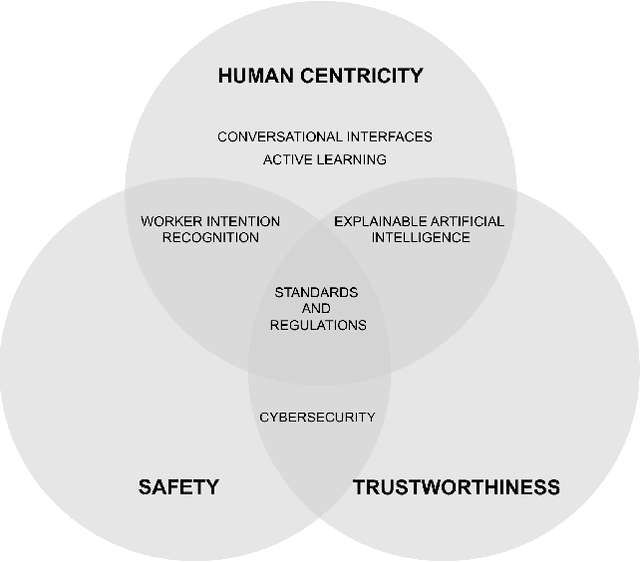
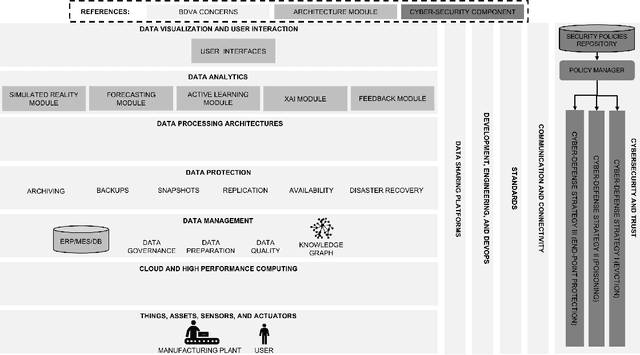
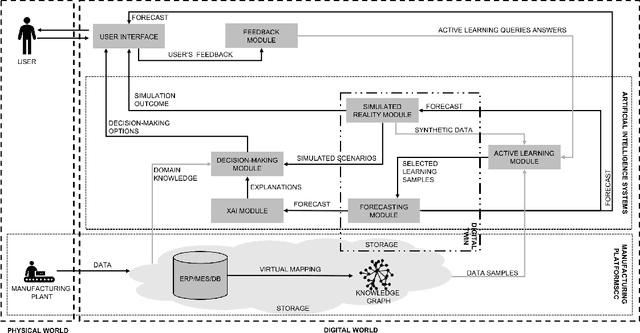

Human-centricity is the core value behind the evolution of manufacturing towards Industry 5.0. Nevertheless, there is a lack of architecture that considers safety, trustworthiness, and human-centricity at its core. Therefore, we propose an architecture that integrates Artificial Intelligence (Active Learning, Forecasting, Explainable Artificial Intelligence), simulated reality, decision-making, and users' feedback, focusing on synergies between humans and machines. Furthermore, we align the proposed architecture with the Big Data Value Association Reference Architecture Model. Finally, we validate it on two use cases from real-world case studies.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021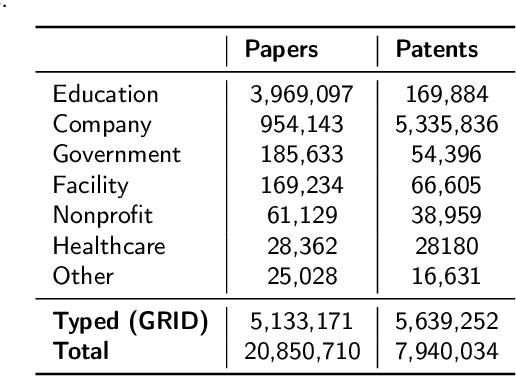
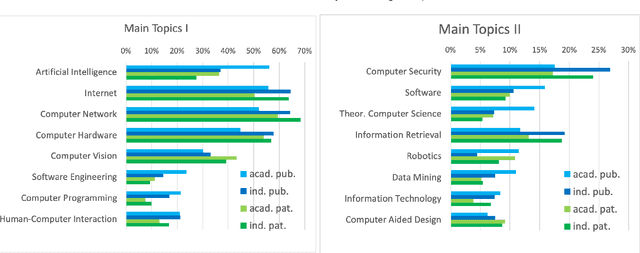
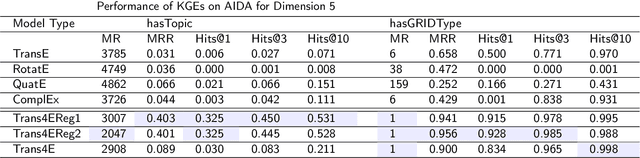
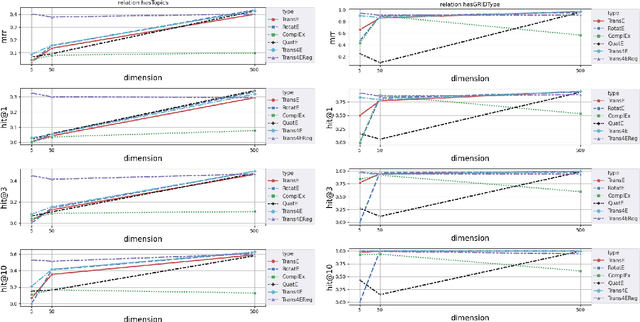
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
TF-IDF vs Word Embeddings for Morbidity Identification in Clinical Notes: An Initial Study
Jun 09, 2021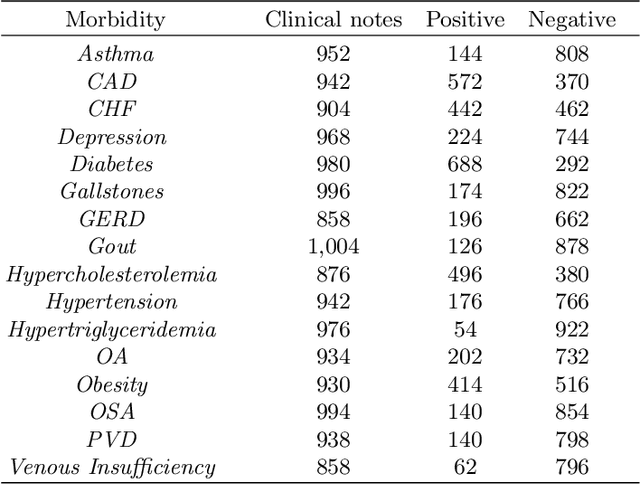
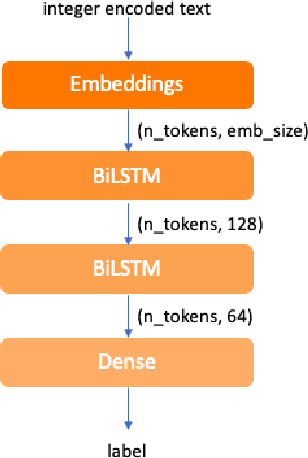
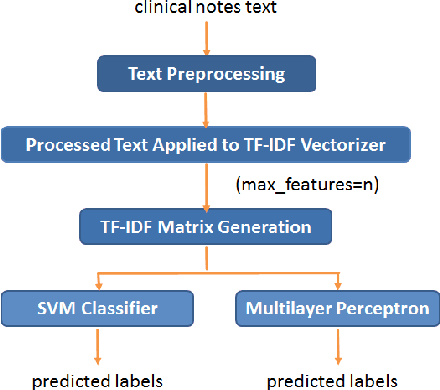
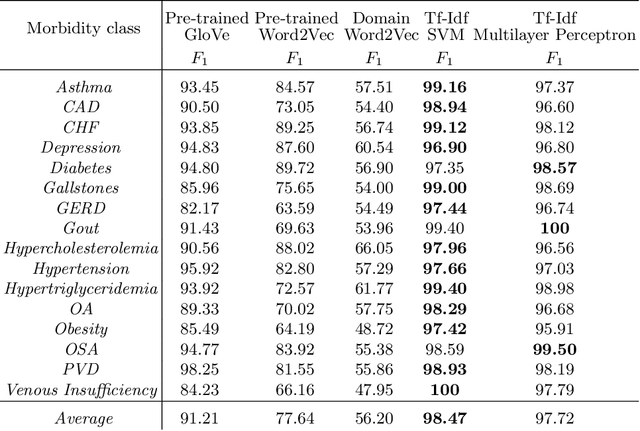
Today, we are seeing an ever-increasing number of clinical notes that contain clinical results, images, and textual descriptions of patient's health state. All these data can be analyzed and employed to cater novel services that can help people and domain experts with their common healthcare tasks. However, many technologies such as Deep Learning and tools like Word Embeddings have started to be investigated only recently, and many challenges remain open when it comes to healthcare domain applications. To address these challenges, we propose the use of Deep Learning and Word Embeddings for identifying sixteen morbidity types within textual descriptions of clinical records. For this purpose, we have used a Deep Learning model based on Bidirectional Long-Short Term Memory (LSTM) layers which can exploit state-of-the-art vector representations of data such as Word Embeddings. We have employed pre-trained Word Embeddings namely GloVe and Word2Vec, and our own Word Embeddings trained on the target domain. Furthermore, we have compared the performances of the deep learning approaches against the traditional tf-idf using Support Vector Machine and Multilayer perceptron (our baselines). From the obtained results it seems that the latter outperforms the combination of Deep Learning approaches using any word embeddings. Our preliminary results indicate that there are specific features that make the dataset biased in favour of traditional machine learning approaches.