 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do LLMs Encode Scientific Quality? An Empirical Study Using Monosemantic Features from Sparse Autoencoders
Feb 22, 2026In recent years, there has been a growing use of generative AI, and large language models (LLMs) in particular, to support both the assessment and generation of scientific work. Although some studies have shown that LLMs can, to a certain extent, evaluate research according to perceived quality, our understanding of the internal mechanisms that enable this capability remains limited. This paper presents the first study that investigates how LLMs encode the concept of scientific quality through relevant monosemantic features extracted using sparse autoencoders. We derive such features under different experimental settings and assess their ability to serve as predictors across three tasks related to research quality: predicting citation count, journal SJR, and journal h-index. The results indicate that LLMs encode features associated with multiple dimensions of scientific quality. In particular, we identify four recurring types of features that capture key aspects of how research quality is represented: 1) features reflecting research methodologies; 2) features related to publication type, with literature reviews typically exhibiting higher impact; 3) features associated with high-impact research fields and technologies; and 4) features corresponding to specific scientific jargons. These findings represent an important step toward understanding how LLMs encapsulate concepts related to research quality.
A Hybrid AI Methodology for Generating Ontologies of Research Topics from Scientific Paper Corpora
Aug 06, 2025

Taxonomies and ontologies of research topics (e.g., MeSH, UMLS, CSO, NLM) play a central role in providing the primary framework through which intelligent systems can explore and interpret the literature. However, these resources have traditionally been manually curated, a process that is time-consuming, prone to obsolescence, and limited in granularity. This paper presents Sci-OG, a semi-auto\-mated methodology for generating research topic ontologies, employing a multi-step approach: 1) Topic Discovery, extracting potential topics from research papers; 2) Relationship Classification, determining semantic relationships between topic pairs; and 3) Ontology Construction, refining and organizing topics into a structured ontology. The relationship classification component, which constitutes the core of the system, integrates an encoder-based language model with features describing topic occurrence in the scientific literature. We evaluate this approach against a range of alternative solutions using a dataset of 21,649 manually annotated semantic triples. Our method achieves the highest F1 score (0.951), surpassing various competing approaches, including a fine-tuned SciBERT model and several LLM baselines, such as the fine-tuned GPT4-mini. Our work is corroborated by a use case which illustrates the practical application of our system to extend the CSO ontology in the area of cybersecurity. The presented solution is designed to improve the accessibility, organization, and analysis of scientific knowledge, thereby supporting advancements in AI-enabled literature management and research exploration.
A Comparative Study of Task Adaptation Techniques of Large Language Models for Identifying Sustainable Development Goals
Jun 18, 2025



In 2012, the United Nations introduced 17 Sustainable Development Goals (SDGs) aimed at creating a more sustainable and improved future by 2030. However, tracking progress toward these goals is difficult because of the extensive scale and complexity of the data involved. Text classification models have become vital tools in this area, automating the analysis of vast amounts of text from a variety of sources. Additionally, large language models (LLMs) have recently proven indispensable for many natural language processing tasks, including text classification, thanks to their ability to recognize complex linguistic patterns and semantics. This study analyzes various proprietary and open-source LLMs for a single-label, multi-class text classification task focused on the SDGs. Then, it also evaluates the effectiveness of task adaptation techniques (i.e., in-context learning approaches), namely Zero-Shot and Few-Shot Learning, as well as Fine-Tuning within this domain. The results reveal that smaller models, when optimized through prompt engineering, can perform on par with larger models like OpenAI's GPT (Generative Pre-trained Transformer).
Large Language Models for Scholarly Ontology Generation: An Extensive Analysis in the Engineering Field
Dec 11, 2024



Ontologies of research topics are crucial for structuring scientific knowledge, enabling scientists to navigate vast amounts of research, and forming the backbone of intelligent systems such as search engines and recommendation systems. However, manual creation of these ontologies is expensive, slow, and often results in outdated and overly general representations. As a solution, researchers have been investigating ways to automate or semi-automate the process of generating these ontologies. This paper offers a comprehensive analysis of the ability of large language models (LLMs) to identify semantic relationships between different research topics, which is a critical step in the development of such ontologies. To this end, we developed a gold standard based on the IEEE Thesaurus to evaluate the task of identifying four types of relationships between pairs of topics: broader, narrower, same-as, and other. Our study evaluates the performance of seventeen LLMs, which differ in scale, accessibility (open vs. proprietary), and model type (full vs. quantised), while also assessing four zero-shot reasoning strategies. Several models have achieved outstanding results, including Mixtral-8x7B, Dolphin-Mistral-7B, and Claude 3 Sonnet, with F1-scores of 0.847, 0.920, and 0.967, respectively. Furthermore, our findings demonstrate that smaller, quantised models, when optimised through prompt engineering, can deliver performance comparable to much larger proprietary models, while requiring significantly fewer computational resources.
A Survey on Knowledge Organization Systems of Research Fields: Resources and Challenges
Sep 06, 2024



Knowledge Organization Systems (KOSs), such as term lists, thesauri, taxonomies, and ontologies, play a fundamental role in categorising, managing, and retrieving information. In the academic domain, KOSs are often adopted for representing research areas and their relationships, primarily aiming to classify research articles, academic courses, patents, books, scientific venues, domain experts, grants, software, experiment materials, and several other relevant products and agents. These structured representations of research areas, widely embraced by many academic fields, have proven effective in empowering AI-based systems to i) enhance retrievability of relevant documents, ii) enable advanced analytic solutions to quantify the impact of academic research, and iii) analyse and forecast research dynamics. This paper aims to present a comprehensive survey of the current KOS for academic disciplines. We analysed and compared 45 KOSs according to five main dimensions: scope, structure, curation, usage, and links to other KOSs. Our results reveal a very heterogeneous scenario in terms of scope, scale, quality, and usage, highlighting the need for more integrated solutions for representing research knowledge across academic fields. We conclude by discussing the main challenges and the most promising future directions.
Artificial Intelligence for Literature Reviews: Opportunities and Challenges
Feb 13, 2024



This manuscript presents a comprehensive review of the use of Artificial Intelligence (AI) in Systematic Literature Reviews (SLRs). A SLR is a rigorous and organised methodology that assesses and integrates previous research on a given topic. Numerous tools have been developed to assist and partially automate the SLR process. The increasing role of AI in this field shows great potential in providing more effective support for researchers, moving towards the semi-automatic creation of literature reviews. Our study focuses on how AI techniques are applied in the semi-automation of SLRs, specifically in the screening and extraction phases. We examine 21 leading SLR tools using a framework that combines 23 traditional features with 11 AI features. We also analyse 11 recent tools that leverage large language models for searching the literature and assisting academic writing. Finally, the paper discusses current trends in the field, outlines key research challenges, and suggests directions for future research.
Characterising Research Areas in the field of AI
May 26, 2022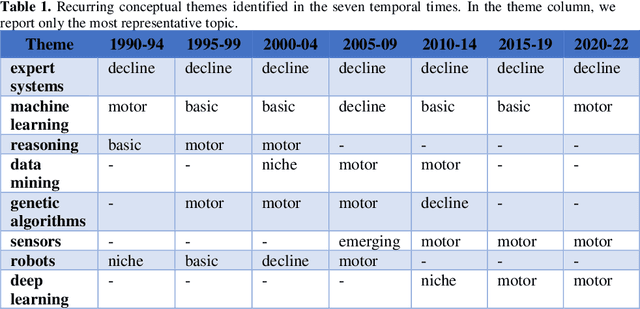
Interest in Artificial Intelligence (AI) continues to grow rapidly, hence it is crucial to support researchers and organisations in understanding where AI research is heading. In this study, we conducted a bibliometric analysis on 257K articles in AI, retrieved from OpenAlex. We identified the main conceptual themes by performing clustering analysis on the co-occurrence network of topics. Finally, we observed how such themes evolved over time. The results highlight the growing academic interest in research themes like deep learning, machine learning, and internet of things.
Trans4E: Link Prediction on Scholarly Knowledge Graphs
Jul 03, 2021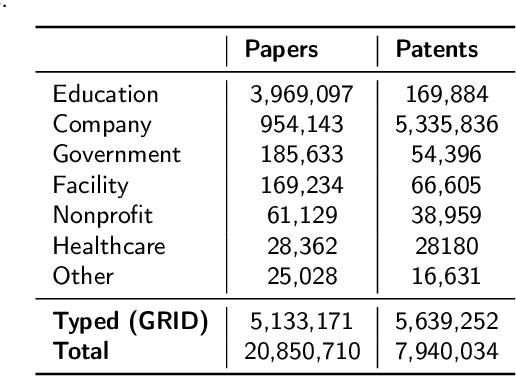
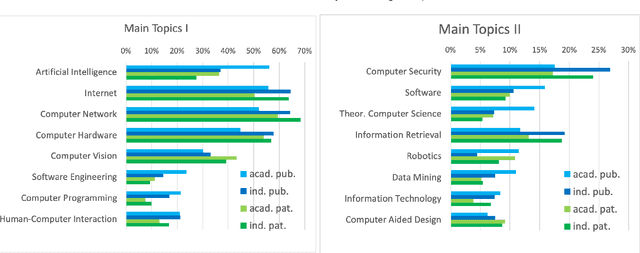
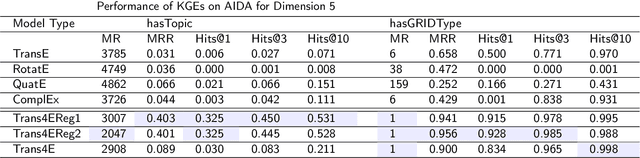
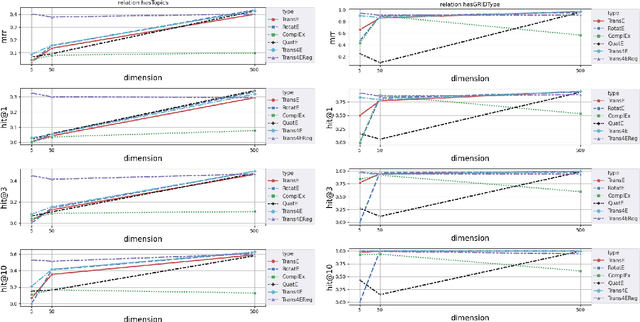
The incompleteness of Knowledge Graphs (KGs) is a crucial issue affecting the quality of AI-based services. In the scholarly domain, KGs describing research publications typically lack important information, hindering our ability to analyse and predict research dynamics. In recent years, link prediction approaches based on Knowledge Graph Embedding models became the first aid for this issue. In this work, we present Trans4E, a novel embedding model that is particularly fit for KGs which include N to M relations with N$\gg$M. This is typical for KGs that categorize a large number of entities (e.g., research articles, patents, persons) according to a relatively small set of categories. Trans4E was applied on two large-scale knowledge graphs, the Academia/Industry DynAmics (AIDA) and Microsoft Academic Graph (MAG), for completing the information about Fields of Study (e.g., 'neural networks', 'machine learning', 'artificial intelligence'), and affiliation types (e.g., 'education', 'company', 'government'), improving the scope and accuracy of the resulting data. We evaluated our approach against alternative solutions on AIDA, MAG, and four other benchmarks (FB15k, FB15k-237, WN18, and WN18RR). Trans4E outperforms the other models when using low embedding dimensions and obtains competitive results in high dimensions.
Detection, Analysis, and Prediction of Research Topics with Scientific Knowledge Graphs
Jun 24, 2021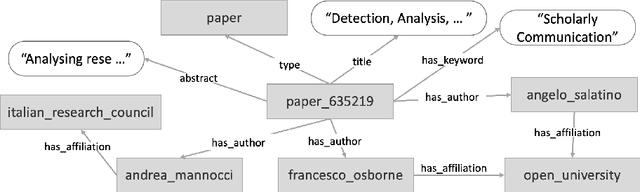
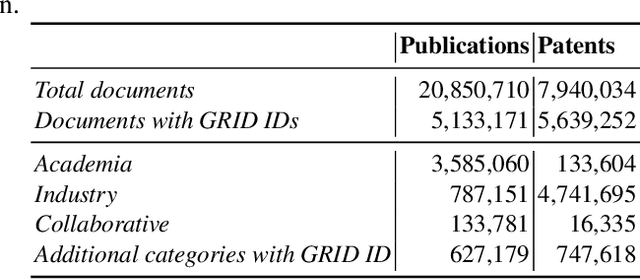
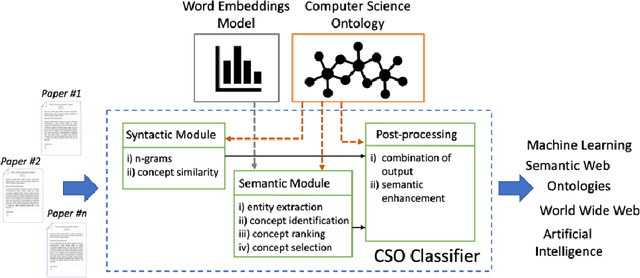
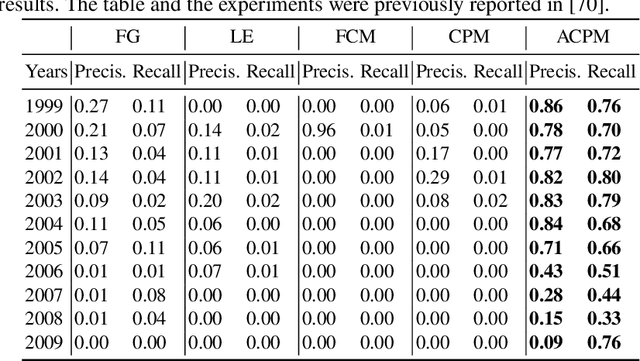
Analysing research trends and predicting their impact on academia and industry is crucial to gain a deeper understanding of the advances in a research field and to inform critical decisions about research funding and technology adoption. In the last years, we saw the emergence of several publicly-available and large-scale Scientific Knowledge Graphs fostering the development of many data-driven approaches for performing quantitative analyses of research trends. This chapter presents an innovative framework for detecting, analysing, and forecasting research topics based on a large-scale knowledge graph characterising research articles according to the research topics from the Computer Science Ontology. We discuss the advantages of a solution based on a formal representation of topics and describe how it was applied to produce bibliometric studies and innovative tools for analysing and predicting research dynamics.