 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICE-BeeM: Identifiable Conditional Energy-Based Deep Models
Feb 26, 2020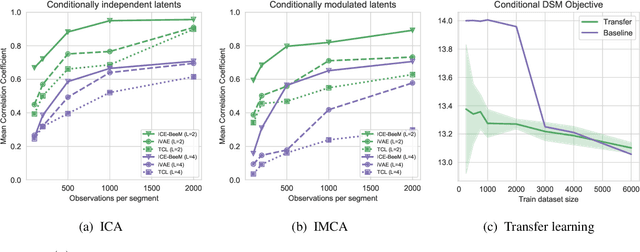

Despite the growing popularity of energy-based models, their identifiability properties are not well-understood. In this paper we establish sufficient conditions under which a large family of conditional energy-based models is identifiable in function space, up to a simple transformation. Our results build on recent developments in the theory of nonlinear ICA, showing that the latent representations in certain families of deep latent-variable models are identifiable. We extend these results to a very broad family of conditional energy-based models. In this family, the energy function is simply the dot-product between two feature extractors, one for the dependent variable, and one for the conditioning variable. We show that under mild conditions, the features are unique up to scaling and permutation. Second, we propose the framework of independently modulated component analysis (IMCA), a new form of nonlinear ICA where the indepencence assumption is relaxed. Importantly, we show that our energy-based model can be used for the estimation of the components: the features learned are a simple and often trivial transformation of the latents.
Flow Contrastive Estimation of Energy-Based Models
Dec 02, 2019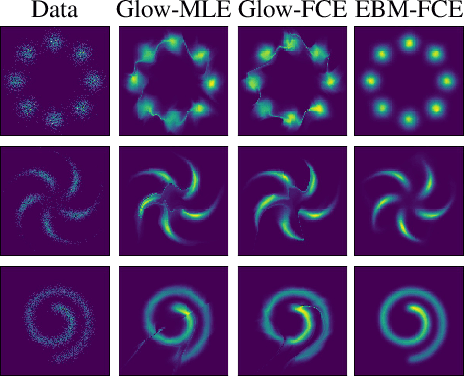
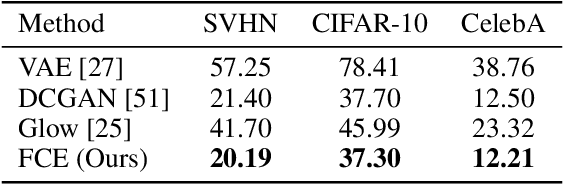
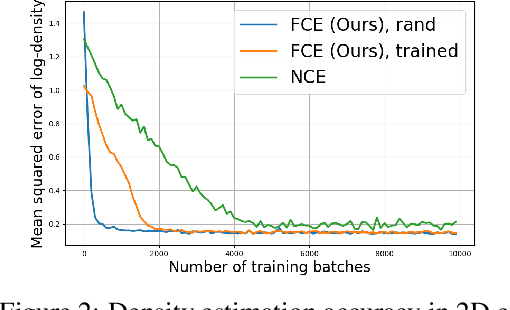
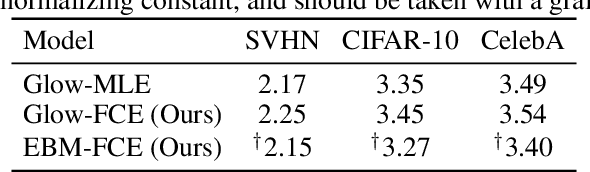
This paper studies a training method to jointly estimate an energy-based model and a flow-based model, in which the two models are iteratively updated based on a shared adversarial value function. This joint training method has the following traits. (1) The update of the energy-based model is based on noise contrastive estimation, with the flow model serving as a strong noise distribution. (2) The update of the flow model approximately minimizes the Jensen-Shannon divergence between the flow model and the data distribution. (3) Unlike generative adversarial networks (GAN) which estimates an implicit probability distribution defined by a generator model, our method estimates two explicit probabilistic distributions on the data. Using the proposed method we demonstrate a significant improvement on the synthesis quality of the flow model, and show the effectiveness of unsupervised feature learning by the learned energy-based model. Furthermore, the proposed training method can be easily adapted to semi-supervised learning. We achieve competitive results to the state-of-the-art semi-supervised learning methods.
An Introduction to Variational Autoencoders
Jul 24, 2019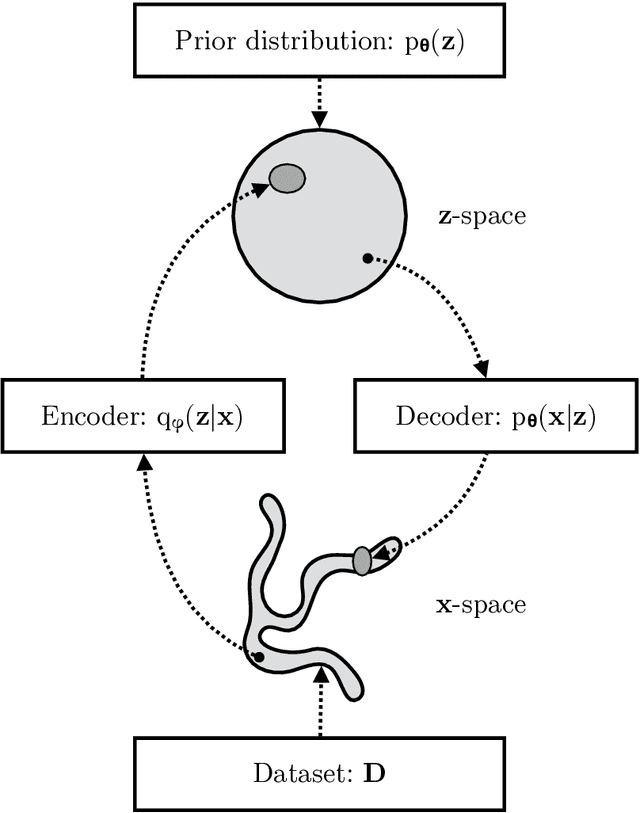
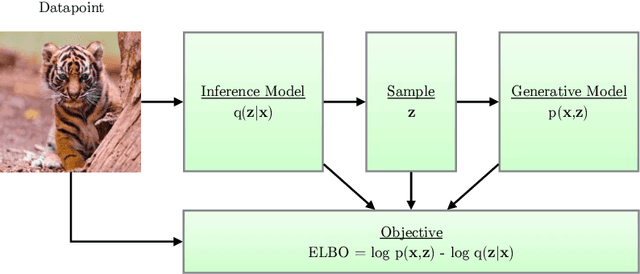
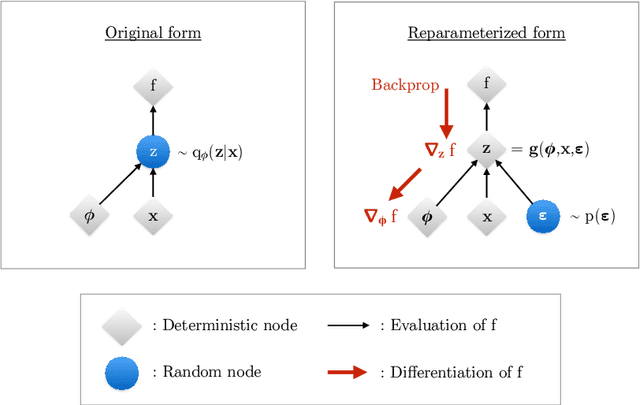
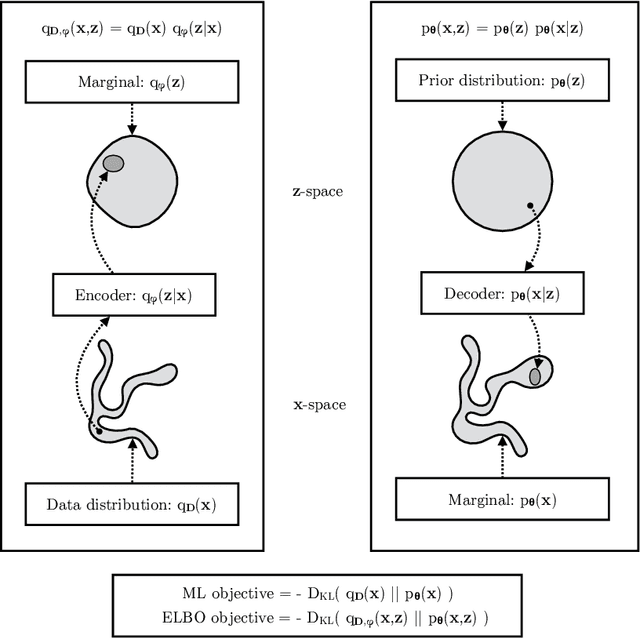
Variational autoencoders provide a principled framework for learning deep latent-variable models and corresponding inference models. In this work, we provide an introduction to variational autoencoders and some important extensions.
Variational Autoencoders and Nonlinear ICA: A Unifying Framework
Jul 10, 2019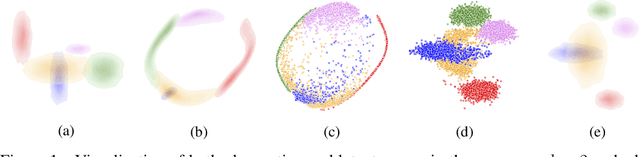
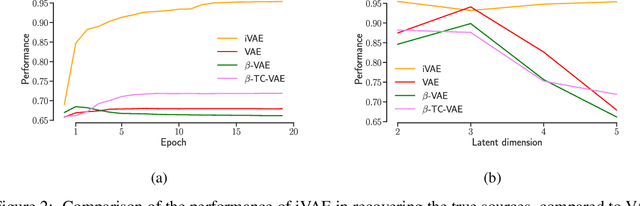
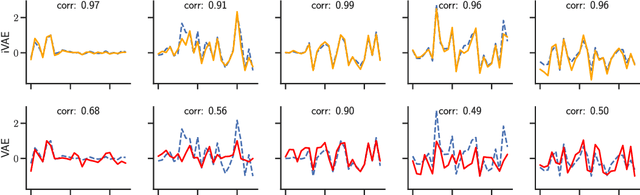
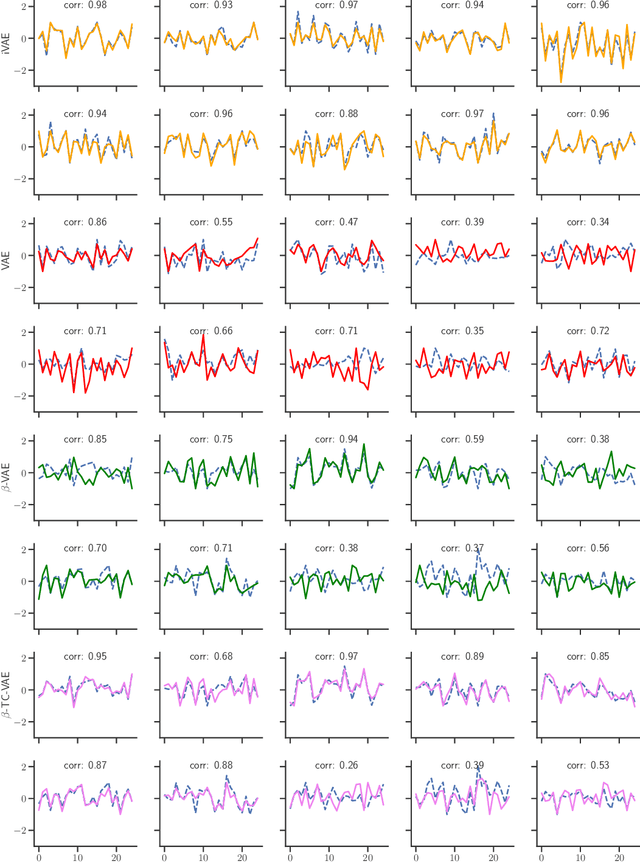
The framework of variational autoencoders allows us to efficiently learn deep latent-variable models, such that the model's marginal distribution over observed variables fits the data. Often, we're interested in going a step further, and want to approximate the true joint distribution over observed and latent variables, including the true prior and posterior distributions over latent variables. This is known to be generally impossible due to unidentifiability of the model. We address this issue by showing that for a broad family of deep latent-variable models, identification of the true joint distribution over observed and latent variables is actually possible up to a simple transformation, thus achieving a principled and powerful form of disentanglement. Our result requires a factorized prior distribution over the latent variables that is conditioned on an additionally observed variable, such as a class label or almost any other observation. We build on recent developments in nonlinear ICA, which we extend to the case with noisy, undercomplete or discrete observations, integrated in a maximum likelihood framework. The result also trivially contains identifiable flow-based generative models as a special case.
Glow: Generative Flow with Invertible 1x1 Convolutions
Jul 10, 2018

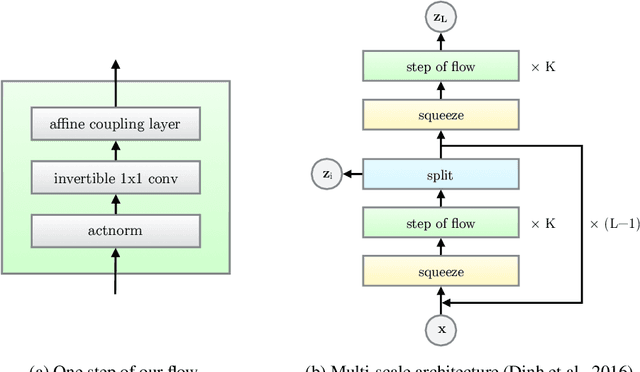
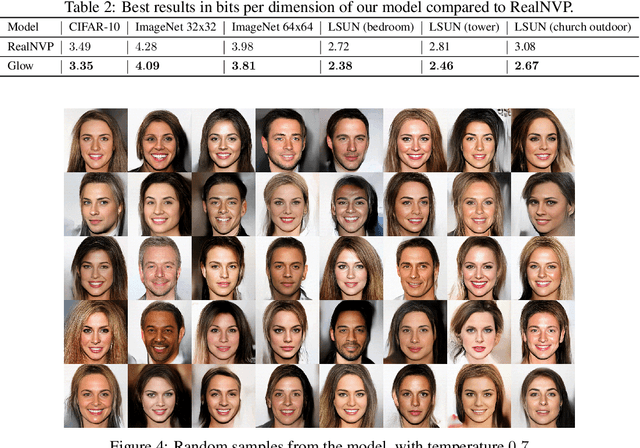
Flow-based generative models (Dinh et al., 2014) are conceptually attractive due to tractability of the exact log-likelihood, tractability of exact latent-variable inference, and parallelizability of both training and synthesis. In this paper we propose Glow, a simple type of generative flow using an invertible 1x1 convolution. Using our method we demonstrate a significant improvement in log-likelihood on standard benchmarks. Perhaps most strikingly, we demonstrate that a generative model optimized towards the plain log-likelihood objective is capable of efficient realistic-looking synthesis and manipulation of large images. The code for our model is available at https://github.com/openai/glow
Learning Sparse Neural Networks through $L_0$ Regularization
Jun 22, 2018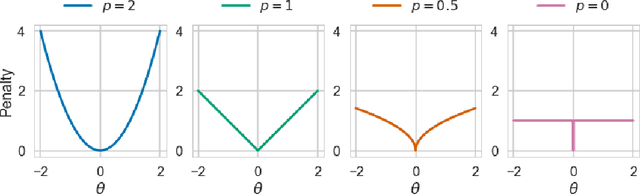
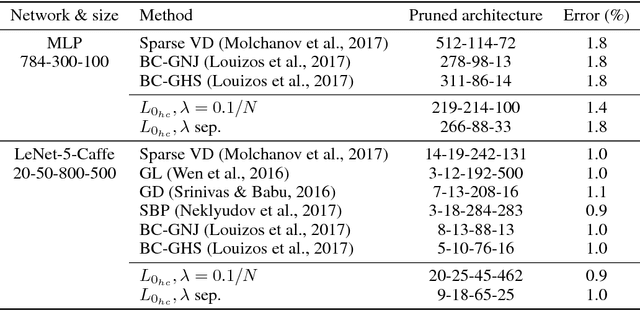
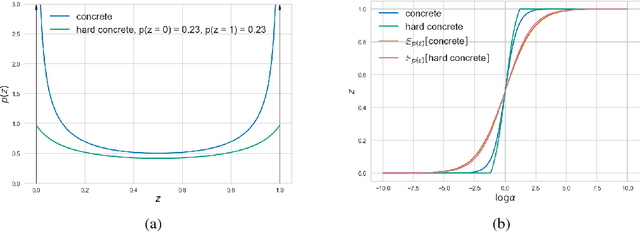
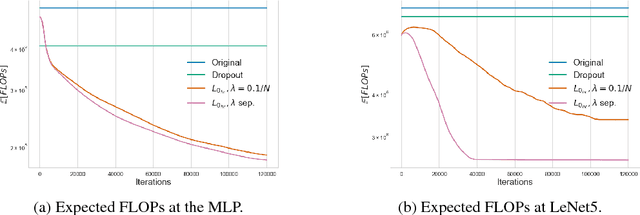
We propose a practical method for $L_0$ norm regularization for neural networks: pruning the network during training by encouraging weights to become exactly zero. Such regularization is interesting since (1) it can greatly speed up training and inference, and (2) it can improve generalization. AIC and BIC, well-known model selection criteria, are special cases of $L_0$ regularization. However, since the $L_0$ norm of weights is non-differentiable, we cannot incorporate it directly as a regularization term in the objective function. We propose a solution through the inclusion of a collection of non-negative stochastic gates, which collectively determine which weights to set to zero. We show that, somewhat surprisingly, for certain distributions over the gates, the expected $L_0$ norm of the resulting gated weights is differentiable with respect to the distribution parameters. We further propose the \emph{hard concrete} distribution for the gates, which is obtained by "stretching" a binary concrete distribution and then transforming its samples with a hard-sigmoid. The parameters of the distribution over the gates can then be jointly optimized with the original network parameters. As a result our method allows for straightforward and efficient learning of model structures with stochastic gradient descent and allows for conditional computation in a principled way. We perform various experiments to demonstrate the effectiveness of the resulting approach and regularizer.
Variational Lossy Autoencoder
Mar 04, 2017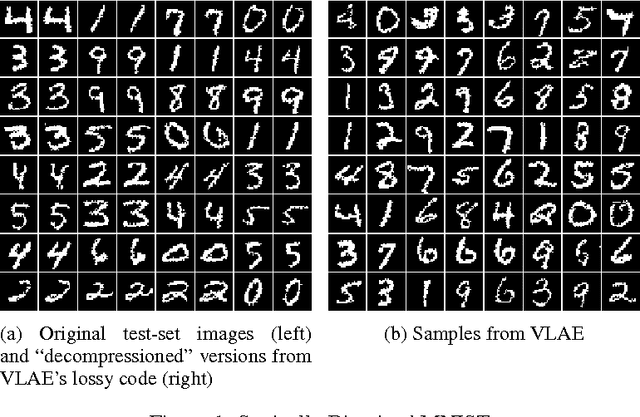
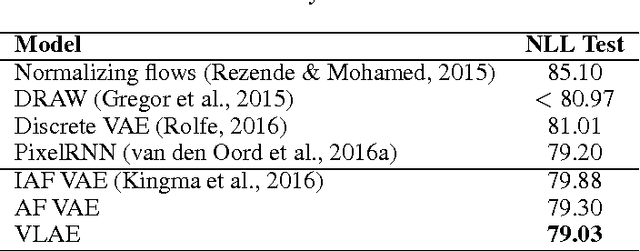


Representation learning seeks to expose certain aspects of observed data in a learned representation that's amenable to downstream tasks like classification. For instance, a good representation for 2D images might be one that describes only global structure and discards information about detailed texture. In this paper, we present a simple but principled method to learn such global representations by combining Variational Autoencoder (VAE) with neural autoregressive models such as RNN, MADE and PixelRNN/CNN. Our proposed VAE model allows us to have control over what the global latent code can learn and , by designing the architecture accordingly, we can force the global latent code to discard irrelevant information such as texture in 2D images, and hence the VAE only "autoencodes" data in a lossy fashion. In addition, by leveraging autoregressive models as both prior distribution $p(z)$ and decoding distribution $p(x|z)$, we can greatly improve generative modeling performance of VAEs, achieving new state-of-the-art results on MNIST, OMNIGLOT and Caltech-101 Silhouettes density estimation tasks.
Improving Variational Inference with Inverse Autoregressive Flow
Jan 30, 2017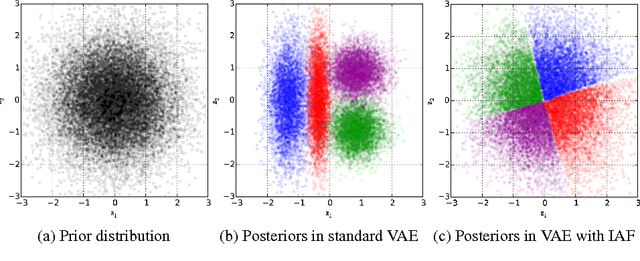
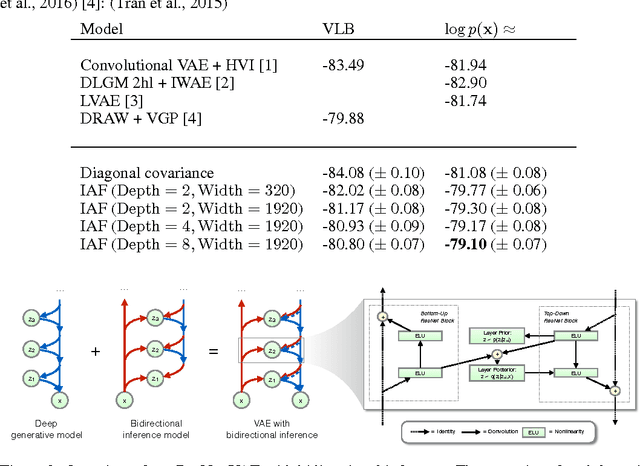
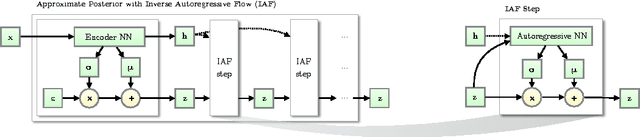
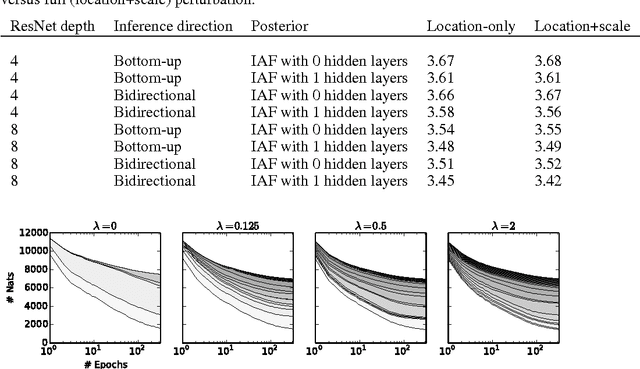
The framework of normalizing flows provides a general strategy for flexible variational inference of posteriors over latent variables. We propose a new type of normalizing flow, inverse autoregressive flow (IAF), that, in contrast to earlier published flows, scales well to high-dimensional latent spaces. The proposed flow consists of a chain of invertible transformations, where each transformation is based on an autoregressive neural network. In experiments, we show that IAF significantly improves upon diagonal Gaussian approximate posteriors. In addition, we demonstrate that a novel type of variational autoencoder, coupled with IAF, is competitive with neural autoregressive models in terms of attained log-likelihood on natural images, while allowing significantly faster synthesis.
Adam: A Method for Stochastic Optimization
Jan 30, 2017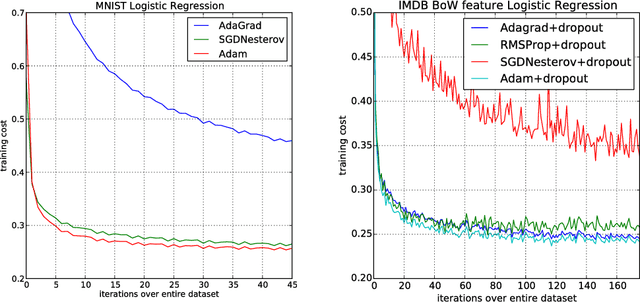
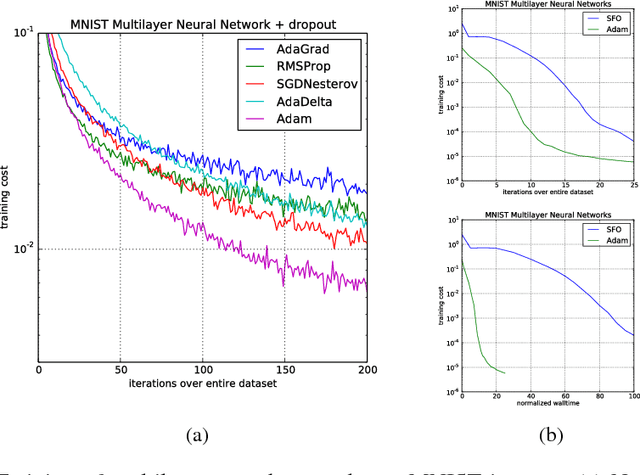
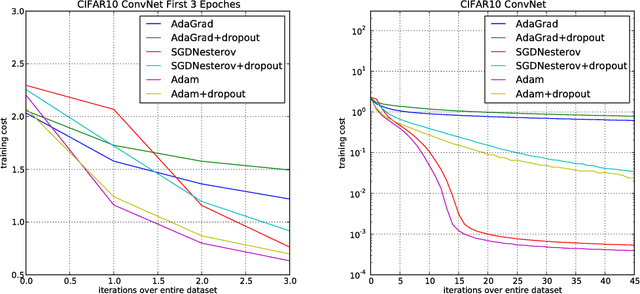
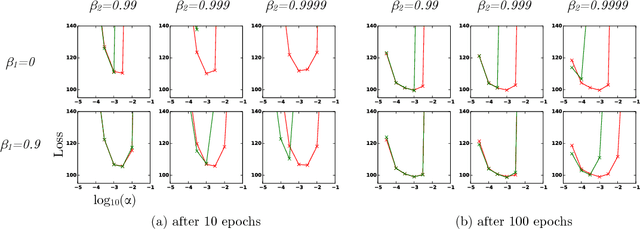
We introduce Adam, an algorithm for first-order gradient-based optimization of stochastic objective functions, based on adaptive estimates of lower-order moments. The method is straightforward to implement, is computationally efficient, has little memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data and/or parameters. The method is also appropriate for non-stationary objectives and problems with very noisy and/or sparse gradients. The hyper-parameters have intuitive interpretations and typically require little tuning. Some connections to related algorithms, on which Adam was inspired, are discussed. We also analyze the theoretical convergence properties of the algorithm and provide a regret bound on the convergence rate that is comparable to the best known results under the online convex optimization framework. Empirical results demonstrate that Adam works well in practice and compares favorably to other stochastic optimization methods. Finally, we discuss AdaMax, a variant of Adam based on the infinity norm.
PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications
Jan 19, 2017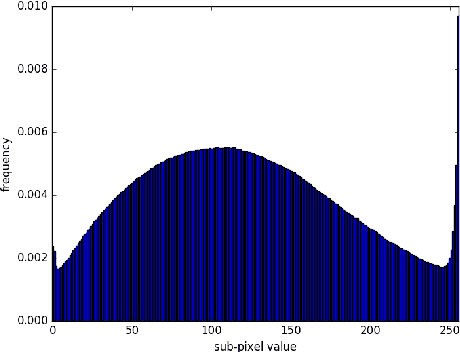
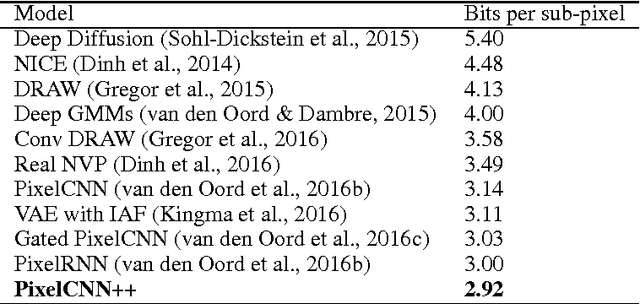
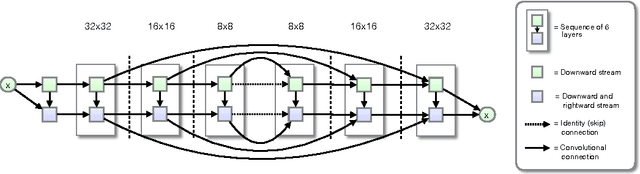

PixelCNNs are a recently proposed class of powerful generative models with tractable likelihood. Here we discuss our implementation of PixelCNNs which we make available at https://github.com/openai/pixel-cnn. Our implementation contains a number of modifications to the original model that both simplify its structure and improve its performance. 1) We use a discretized logistic mixture likelihood on the pixels, rather than a 256-way softmax, which we find to speed up training. 2) We condition on whole pixels, rather than R/G/B sub-pixels, simplifying the model structure. 3) We use downsampling to efficiently capture structure at multiple resolutions. 4) We introduce additional short-cut connections to further speed up optimization. 5) We regularize the model using dropout. Finally, we present state-of-the-art log likelihood results on CIFAR-10 to demonstrate the usefulness of these modifications.