 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAS-Attention: Memory-Aware Stream Processing for Attention Acceleration on Resource-Constrained Edge Devices
Nov 20, 2024The advent of foundation models have revolutionized various fields, enabling unprecedented task accuracy and flexibility in computational linguistics, computer vision and other domains. Attention mechanism has become an essential component of foundation models, due to their superb capability of capturing correlations in a sequence. However, attention results in quadratic complexity in memory and compute as the context length grows. Although many fusion-based exact attention acceleration algorithms have been developed for datacenter-grade GPUs and accelerators leveraging multi-core parallelism and data locality, yet it remains a significant challenge to accelerate attention on resource-constrained edge neural accelerators with limited compute units and stringent on-chip caches. In this paper, we propose a scheme for exact attention inference acceleration on memory-constrained edge accelerators, by parallelizing the utilization of heterogeneous compute units, i.e., vector processing units and matrix processing units. Our method involves scheduling workloads onto these different compute units in a multi-tiered tiling scheme to process tiled vector workloads and matrix workloads in attention as two streams, respecting the workload dependencies. We search for tiling factors to maximize the parallelization of both compute units while considering I/O overhead, and propose a proactive cache overwrite strategy to avoid undesirable cache spills in reality. Extensive results based on open-sourced simulation frameworks show up to 2.75x speedup and 54% reduction in energy consumption as compared to the state-of-the-art attention fusion method (FLAT) in the edge computing scenario. Further experiments on a real-world edge neural processing unit demonstrate speedup of up to 1.76x for attention as compared to FLAT, without affecting model output accuracy.
Learning Truncated Causal History Model for Video Restoration
Oct 15, 2024



One key challenge to video restoration is to model the transition dynamics of video frames governed by motion. In this work, we propose TURTLE to learn the truncated causal history model for efficient and high-performing video restoration. Unlike traditional methods that process a range of contextual frames in parallel, TURTLE enhances efficiency by storing and summarizing a truncated history of the input frame latent representation into an evolving historical state. This is achieved through a sophisticated similarity-based retrieval mechanism that implicitly accounts for inter-frame motion and alignment. The causal design in TURTLE enables recurrence in inference through state-memorized historical features while allowing parallel training by sampling truncated video clips. We report new state-of-the-art results on a multitude of video restoration benchmark tasks, including video desnowing, nighttime video deraining, video raindrops and rain streak removal, video super-resolution, real-world and synthetic video deblurring, and blind video denoising while reducing the computational cost compared to existing best contextual methods on all these tasks.
FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Aug 21, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt's semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token's weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation on the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality.
Achieving Complex Image Edits via Function Aggregation with Diffusion Models
Aug 16, 2024



Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.
Optimizing and Testing Instruction-Following: Analyzing the Impact of Fine-Grained Instruction Variants on instruction-tuned LLMs
Jun 17, 2024The effective alignment of Large Language Models (LLMs) with precise instructions is essential for their application in diverse real-world scenarios. Current methods focus on enhancing the diversity and complexity of training and evaluation samples, yet they fall short in accurately assessing LLMs' ability to follow similar instruction variants. We introduce an effective data augmentation technique that decomposes complex instructions into simpler sub-components, modifies these, and reconstructs them into new variants, thereby preserves the original instruction's context and complexity while introducing variability, which is critical for training and evaluating LLMs' instruction-following precision. We developed the DeMoRecon dataset using this method to both fine-tune and evaluate LLMs. Our findings show that LLMs fine-tuned with DeMoRecon will gain significant performance boost on both ours and commonly used instructions-following benchmarks.
CTRL: Continuous-Time Representation Learning on Temporal Heterogeneous Information Network
May 11, 2024


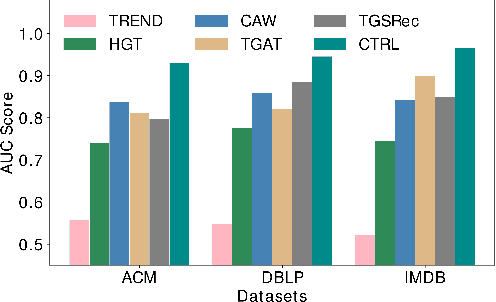
Inductive representation learning on temporal heterogeneous graphs is crucial for scalable deep learning on heterogeneous information networks (HINs) which are time-varying, such as citation networks. However, most existing approaches are not inductive and thus cannot handle new nodes or edges. Moreover, previous temporal graph embedding methods are often trained with the temporal link prediction task to simulate the link formation process of temporal graphs, while ignoring the evolution of high-order topological structures on temporal graphs. To fill these gaps, we propose a Continuous-Time Representation Learning (CTRL) model on temporal HINs. To preserve heterogeneous node features and temporal structures, CTRL integrates three parts in a single layer, they are 1) a \emph{heterogeneous attention} unit that measures the semantic correlation between nodes, 2) a \emph{edge-based Hawkes process} to capture temporal influence between heterogeneous nodes, and 3) \emph{dynamic centrality} that indicates the dynamic importance of a node. We train the CTRL model with a future event (a subgraph) prediction task to capture the evolution of the high-order network structure. Extensive experiments have been conducted on three benchmark datasets. The results demonstrate that our model significantly boosts performance and outperforms various state-of-the-art approaches. Ablation studies are conducted to demonstrate the effectiveness of the model design.
EiG-Search: Generating Edge-Induced Subgraphs for GNN Explanation in Linear Time
May 02, 2024Understanding and explaining the predictions of Graph Neural Networks (GNNs), is crucial for enhancing their safety and trustworthiness. Subgraph-level explanations are gaining attention for their intuitive appeal. However, most existing subgraph-level explainers face efficiency challenges in explaining GNNs due to complex search processes. The key challenge is to find a balance between intuitiveness and efficiency while ensuring transparency. Additionally, these explainers usually induce subgraphs by nodes, which may introduce less-intuitive disconnected nodes in the subgraph-level explanations or omit many important subgraph structures. In this paper, we reveal that inducing subgraph explanations by edges is more comprehensive than other subgraph inducing techniques. We also emphasize the need of determining the subgraph explanation size for each data instance, as different data instances may involve different important substructures. Building upon these considerations, we introduce a training-free approach, named EiG-Search. We employ an efficient linear-time search algorithm over the edge-induced subgraphs, where the edges are ranked by an enhanced gradient-based importance. We conduct extensive experiments on a total of seven datasets, demonstrating its superior performance and efficiency both quantitatively and qualitatively over the leading baselines.
* 19 pages
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024



Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
SIFiD: Reassess Summary Factual Inconsistency Detection with LLM
Mar 12, 2024

Ensuring factual consistency between the summary and the original document is paramount in summarization tasks. Consequently, considerable effort has been dedicated to detecting inconsistencies. With the advent of Large Language Models (LLMs), recent studies have begun to leverage their advanced language understanding capabilities for inconsistency detection. However, early attempts have shown that LLMs underperform traditional models due to their limited ability to follow instructions and the absence of an effective detection methodology. In this study, we reassess summary inconsistency detection with LLMs, comparing the performances of GPT-3.5 and GPT-4. To advance research in LLM-based inconsistency detection, we propose SIFiD (Summary Inconsistency Detection with Filtered Document) that identify key sentences within documents by either employing natural language inference or measuring semantic similarity between summaries and documents.
Boosting of Thoughts: Trial-and-Error Problem Solving with Large Language Models
Feb 17, 2024



The reasoning performance of Large Language Models (LLMs) on a wide range of problems critically relies on chain-of-thought prompting, which involves providing a few chain of thought demonstrations as exemplars in prompts. Recent work, e.g., Tree of Thoughts, has pointed out the importance of exploration and self-evaluation in reasoning step selection for complex problem solving. In this paper, we present Boosting of Thoughts (BoT), an automated prompting framework for problem solving with LLMs by iteratively exploring and self-evaluating many trees of thoughts in order to acquire an ensemble of trial-and-error reasoning experiences, which will serve as a new form of prompting to solve the complex problem. Starting from a simple prompt without requiring examples, BoT iteratively explores and evaluates a large collection of reasoning steps, and more importantly, uses error analysis obtained from the LLM on them to explicitly revise prompting, which in turn enhances reasoning step generation, until a final answer is attained. Our experiments with GPT-4 and Llama2 across extensive complex mathematical problems demonstrate that BoT consistently achieves higher or comparable problem-solving rates than other advanced prompting approaches.