 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Efficient Multi-task Network for 3D Object Detection and Road Understanding
Mar 06, 2021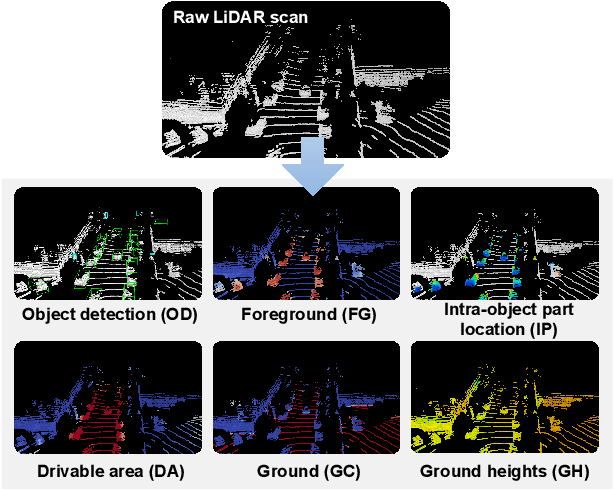
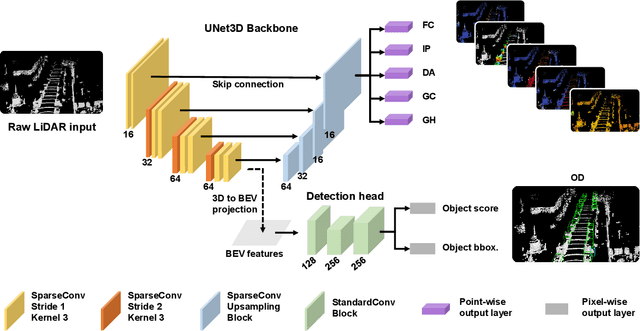
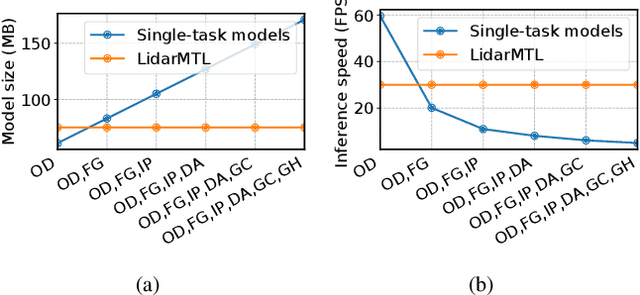
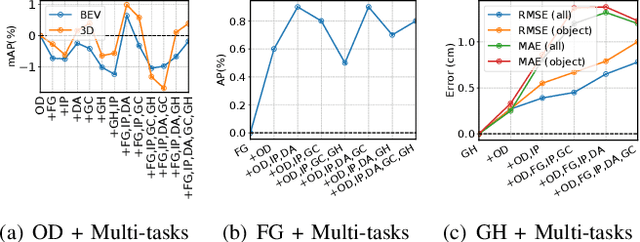
Detecting dynamic objects and predicting static road information such as drivable areas and ground heights are crucial for safe autonomous driving. Previous works studied each perception task separately, and lacked a collective quantitative analysis. In this work, we show that it is possible to perform all perception tasks via a simple and efficient multi-task network. Our proposed network, LidarMTL, takes raw LiDAR point cloud as inputs, and predicts six perception outputs for 3D object detection and road understanding. The network is based on an encoder-decoder architecture with 3D sparse convolution and deconvolution operations. Extensive experiments verify the proposed method with competitive accuracies compared to state-of-the-art object detectors and other task-specific networks. LidarMTL is also leveraged for online localization. Code and pre-trained model have been made available at https://github.com/frankfengdi/LidarMTL.
Labels Are Not Perfect: Inferring Spatial Uncertainty in Object Detection
Dec 18, 2020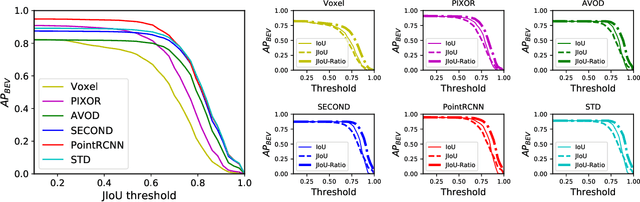
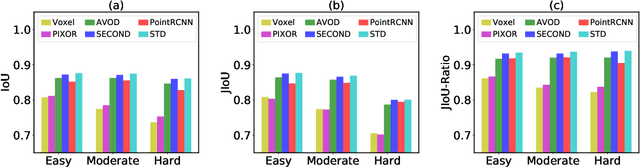
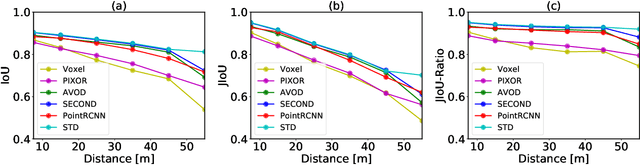
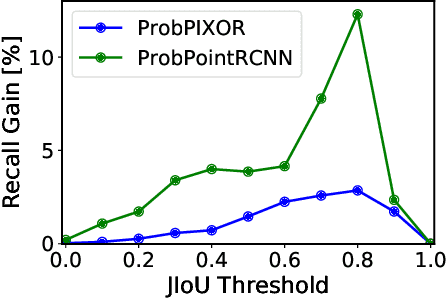
The availability of many real-world driving datasets is a key reason behind the recent progress of object detection algorithms in autonomous driving. However, there exist ambiguity or even failures in object labels due to error-prone annotation process or sensor observation noise. Current public object detection datasets only provide deterministic object labels without considering their inherent uncertainty, as does the common training process or evaluation metrics for object detectors. As a result, an in-depth evaluation among different object detection methods remains challenging, and the training process of object detectors is sub-optimal, especially in probabilistic object detection. In this work, we infer the uncertainty in bounding box labels from LiDAR point clouds based on a generative model, and define a new representation of the probabilistic bounding box through a spatial uncertainty distribution. Comprehensive experiments show that the proposed model reflects complex environmental noises in LiDAR perception and the label quality. Furthermore, we propose Jaccard IoU (JIoU) as a new evaluation metric that extends IoU by incorporating label uncertainty. We conduct an in-depth comparison among several LiDAR-based object detectors using the JIoU metric. Finally, we incorporate the proposed label uncertainty in a loss function to train a probabilistic object detector and to improve its detection accuracy. We verify our proposed methods on two public datasets (KITTI, Waymo), as well as on simulation data. Code is released at https://bit.ly/2W534yo.
A Review and Comparative Study on Probabilistic Object Detection in Autonomous Driving
Nov 20, 2020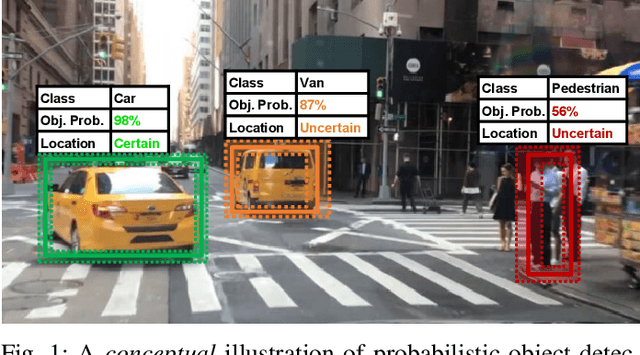
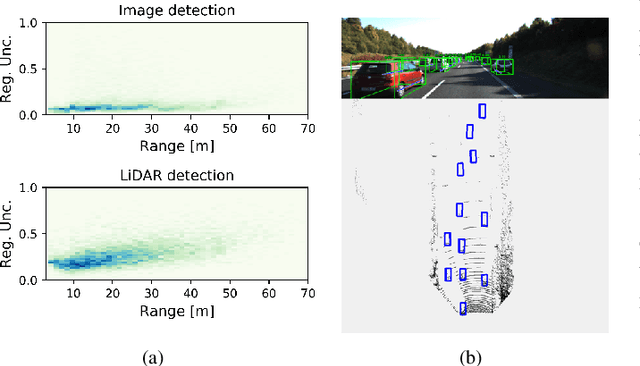
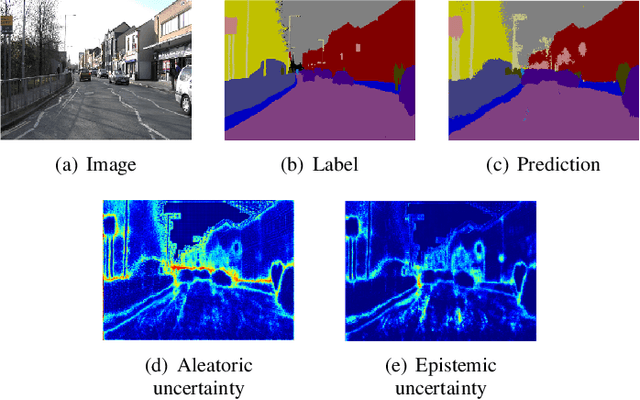
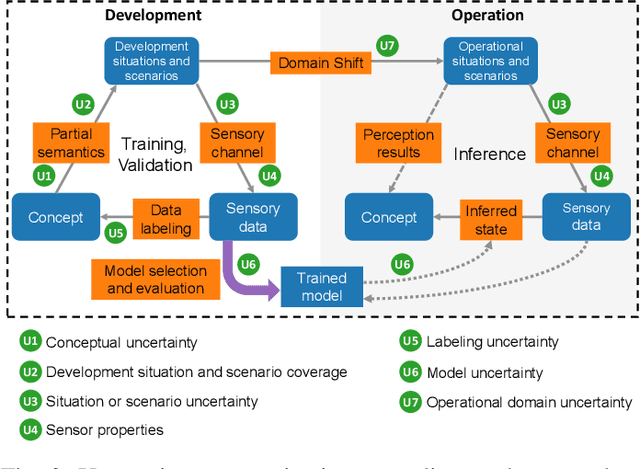
Capturing uncertainty in object detection is indispensable for safe autonomous driving. In recent years, deep learning has become the de-facto approach for object detection, and many probabilistic object detectors have been proposed. However, there is no summary on uncertainty estimation in deep object detection, and existing methods are not only built with different network architectures and uncertainty estimation methods, but also evaluated on different datasets with a wide range of evaluation metrics. As a result, a comparison among methods remains challenging, as does the selection of a model that best suits a particular application. This paper aims to alleviate this problem by providing a review and comparative study on existing probabilistic object detection methods for autonomous driving applications. First, we provide an overview of generic uncertainty estimation in deep learning, and then systematically survey existing methods and evaluation metrics for probabilistic object detection. Next, we present a strict comparative study for probabilistic object detection based on an image detector and three public autonomous driving datasets. Finally, we present a discussion of the remaining challenges and future works. Code has been made available at https://github.com/asharakeh/pod_compare.git
Labels Are Not Perfect: Improving Probabilistic Object Detection via Label Uncertainty
Aug 10, 2020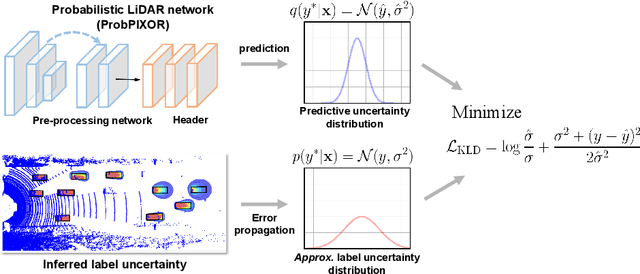
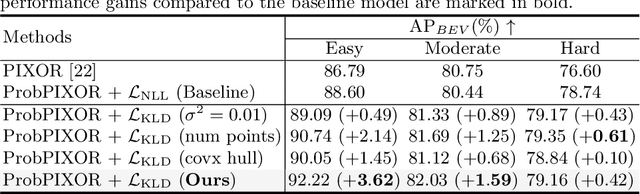
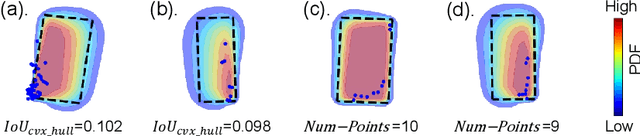

Reliable uncertainty estimation is crucial for robust object detection in autonomous driving. However, previous works on probabilistic object detection either learn predictive probability for bounding box regression in an un-supervised manner, or use simple heuristics to do uncertainty regularization. This leads to unstable training or suboptimal detection performance. In this work, we leverage our previously proposed method for estimating uncertainty inherent in ground truth bounding box parameters (which we call label uncertainty) to improve the detection accuracy of a probabilistic LiDAR-based object detector. Experimental results on the KITTI dataset show that our method surpasses both the baseline model and the models based on simple heuristics by up to 3.6% in terms of Average Precision.
Where can I drive? Deep Ego-Corridor Estimation for Robust Automated Driving
Apr 16, 2020


Lane detection is an essential part of the perception module of any automated driving (AD) or advanced driver assistance system (ADAS). So far, model-driven approaches for the detection of lane markings proved sufficient. More recently, however data-driven approaches have been proposed that show superior results. These deep learning approaches typically propose a classification of the free-space using for example semantic segmentation. While these examples focus and optimize on unmarked inner-city roads, we believe that mapless driving in complex highway scenarios is still not handled with sufficient robustness and availability. Especially in challenging weather situations such as heavy rain, fog at night or reflections in puddles, the reliable detection of lane markings will decrease significantly or completely fail with low-cost video-only AD systems. Therefore, we propose to specifically classify a drivable corridor in the ego-lane on a pixel level with a deep learning approach. Our approach is intentionally kept simple with only 660k parameters. Thus, we were able to easily integrate our algorithm into an online AD system of a test vehicle. We demonstrate the performance of our approach under challenging conditions qualitatively and quantitatively in comparison to a state-of-the-art model-driven approach. We see the current approach as a fallback method whenever a model-driven approach cannot cope with a specific scenario. Due to this, a fallback method does not have to fulfill the same requirements on comfort in lateral control as the primary algorithm: Its task is to catch the temporal shortcomings of the main perception task.
Inferring Spatial Uncertainty in Object Detection
Mar 07, 2020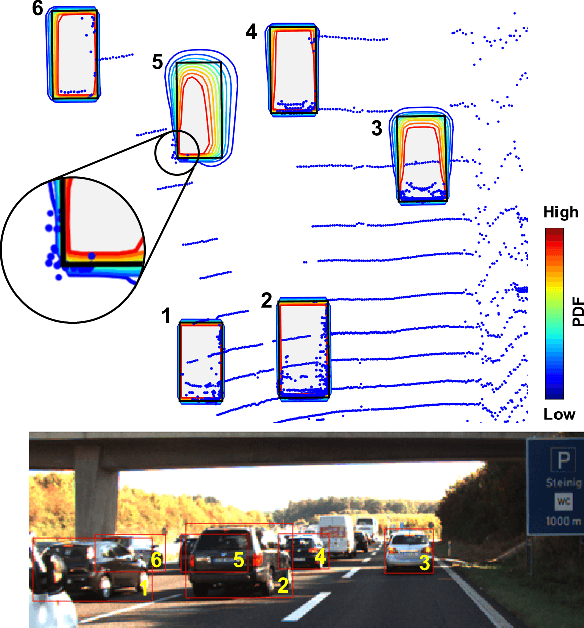
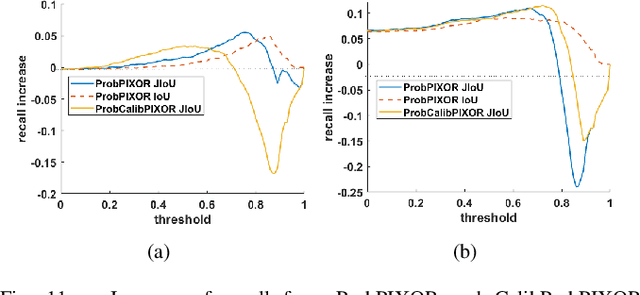
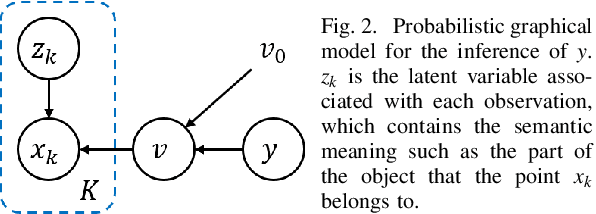
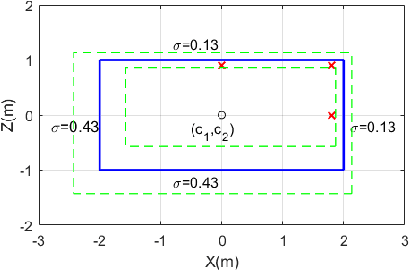
The availability of real-world datasets is the prerequisite to develop object detection methods for autonomous driving. While ambiguity exists in object labels due to error-prone annotation process or sensor observation noises, current object detection datasets only provide deterministic annotations, without considering their uncertainty. This precludes an in-depth evaluation among different object detection methods, especially for those that explicitly model predictive probability. In this work, we propose a generative model to estimate bounding box label uncertainties from LiDAR point clouds, and define a new representation of the probabilistic bounding box through spatial distribution. Comprehensive experiments show that the proposed model represents uncertainties commonly seen in driving scenarios. Based on the spatial distribution, we further propose an extension of IoU, called the Jaccard IoU (JIoU), as a new evaluation metric that incorporates label uncertainty. The experiments on the KITTI and the Waymo Open Datasets show that JIoU is superior to IoU when evaluating probabilistic object detectors.
Leveraging Uncertainties for Deep Multi-modal Object Detection in Autonomous Driving
Feb 01, 2020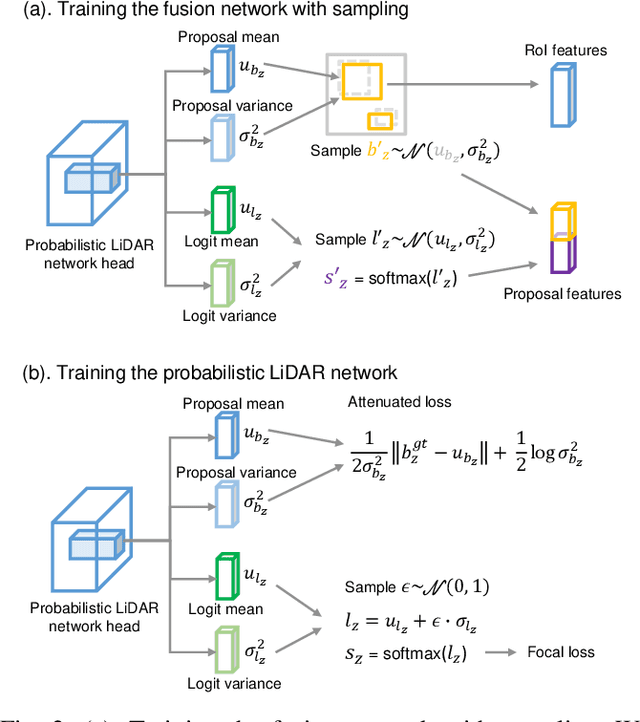
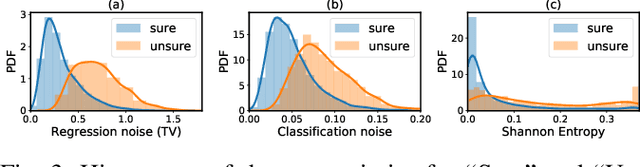
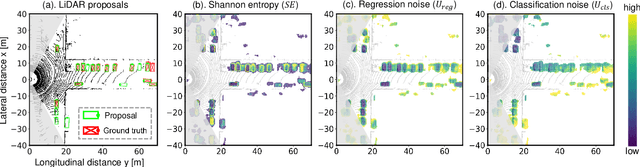
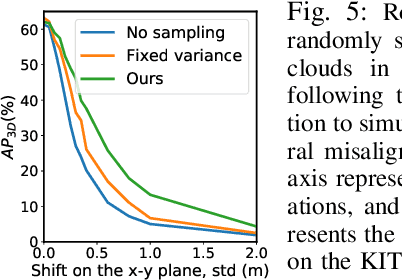
This work presents a probabilistic deep neural network that combines LiDAR point clouds and RGB camera images for robust, accurate 3D object detection. We explicitly model uncertainties in the classification and regression tasks, and leverage uncertainties to train the fusion network via a sampling mechanism. We validate our method on three datasets with challenging real-world driving scenarios. Experimental results show that the predicted uncertainties reflect complex environmental uncertainty like difficulties of a human expert to label objects. The results also show that our method consistently improves the Average Precision by up to 7% compared to the baseline method. When sensors are temporally misaligned, the sampling method improves the Average Precision by up to 20%, showing its high robustness against noisy sensor inputs.
Can We Trust You? On Calibration of a Probabilistic Object Detector for Autonomous Driving
Sep 26, 2019
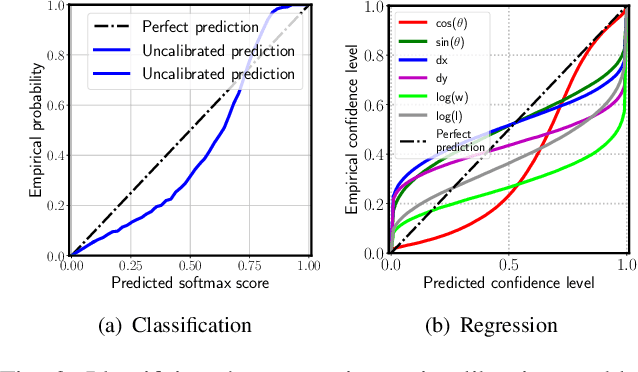
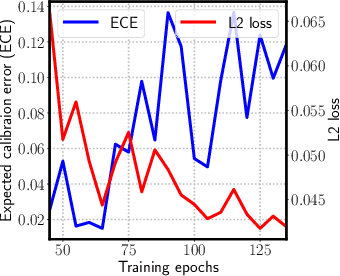
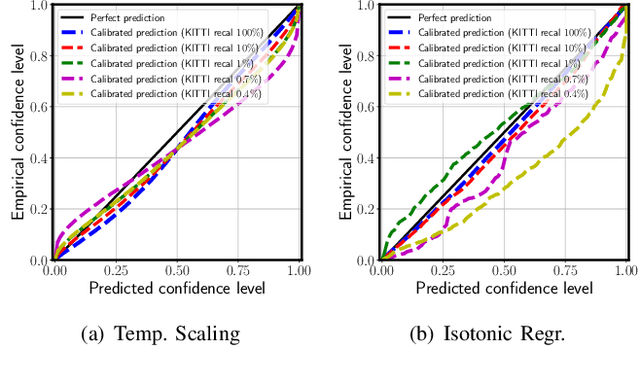
Reliable uncertainty estimation is crucial for perception systems in safe autonomous driving. Recently, many methods have been proposed to model uncertainties in deep learning based object detectors. However, the estimated probabilities are often uncalibrated, which may lead to severe problems in safety critical scenarios. In this work, we identify such uncertainty miscalibration problems in a probabilistic LiDAR 3D object detection network, and propose three practical methods to significantly reduce errors in uncertainty calibration. Extensive experiments on several datasets show that our methods produce well-calibrated uncertainties, and generalize well between different datasets.
Deep Multi-modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges
Feb 21, 2019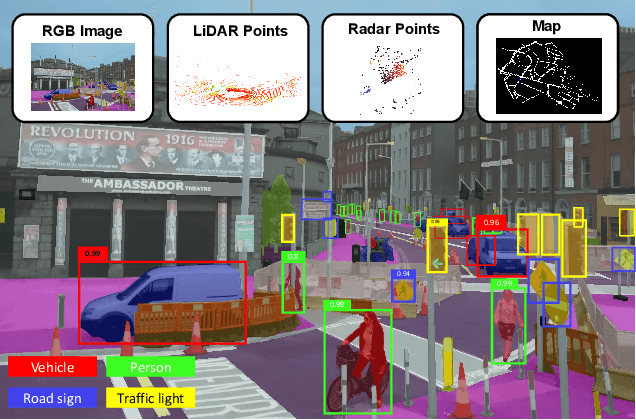
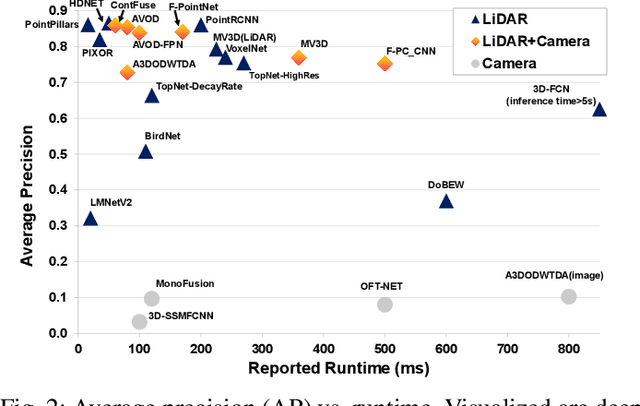

Recent advancements in the perception for autonomous driving are driven by deep learning. In order to achieve the robust and accurate scene understanding, autonomous vehicles are usually equipped with different sensors (e.g. cameras, LiDARs, Radars), and multiple sensing modalities can be fused to exploit their complementary properties. In this context, many methods have been proposed for deep multi-modal perception problems. However, there is no general guideline for network architecture design, and questions of "what to fuse", "when to fuse", and "how to fuse" remain open. This review paper attempts to systematically summarize methodologies and discuss challenges for deep multi-modal object detection and semantic segmentation in autonomous driving. To this end, we first provide an overview of on-board sensors on test vehicles, open datasets and the background information of object detection and semantic segmentation for the autonomous driving research. We then summarize the fusion methodologies and discuss challenges and open questions. In the appendix, we provide tables that summarize topics and methods. We also provide an interactive online platform to navigate each reference: https://multimodalperception.github.io.
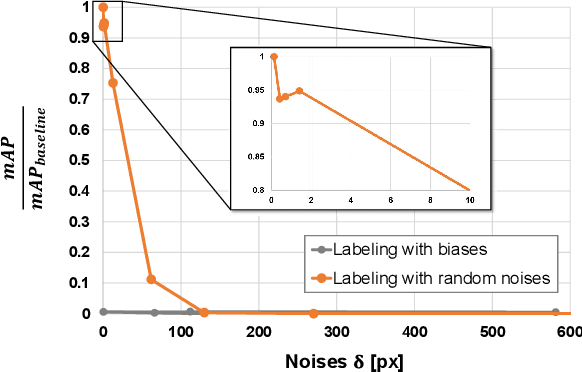
Leveraging Heteroscedastic Aleatoric Uncertainties for Robust Real-Time LiDAR 3D Object Detection
Feb 03, 2019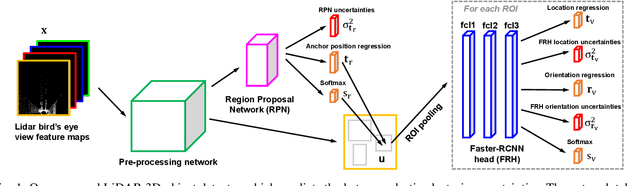

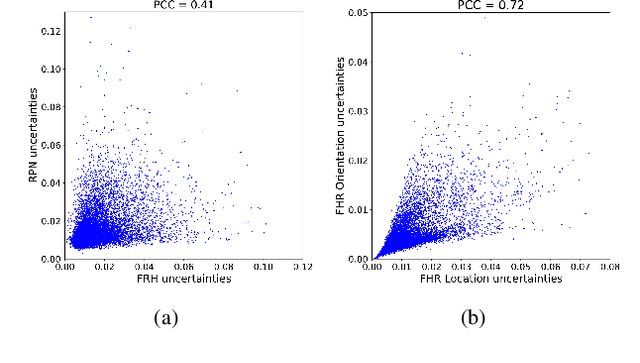
We present a robust real-time LiDAR 3D object detector that leverages heteroscedastic aleatoric uncertainties to significantly improve its detection performance. A multi-loss function is designed to incorporate uncertainty estimations predicted by auxiliary output layers. Using our proposed method, the network ignores to train from noisy samples, and focuses more on informative ones. We validate our method on the KITTI object detection benchmark. Our method surpasses the baseline method which does not explicitly estimate uncertainties by up to nearly 9% in terms of Average Precision (AP). It also produces state-of-the-art results compared to other methods while running with an inference time of only 72 ms. In addition, we conduct extensive experiments to understand how aleatoric uncertainties behave. Extracting aleatoric uncertainties brings almost no additional computation cost during the deployment, making our method highly desirable for autonomous driving applications.