 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Large Language Models Mirror Cognitive Language Processing?
Feb 28, 2024

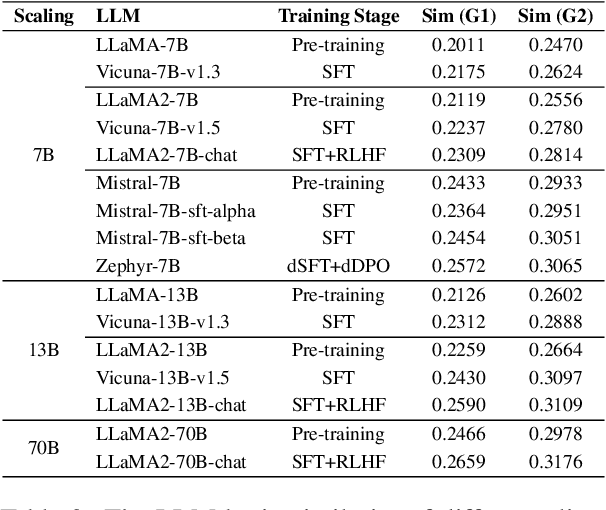

Large language models (LLMs) have demonstrated remarkable capabilities in text comprehension and logical reasoning, achiving or even surpassing human-level performance in numerous cognition tasks. As LLMs are trained from massive textual outputs of human language cognition, it is natural to ask whether LLMs mirror cognitive language processing. Or to what extend LLMs resemble cognitive language processing? In this paper, we propose a novel method that bridge between LLM representations and human cognition signals to evaluate how effectively LLMs simulate cognitive language processing. We employ Representational Similarity Analysis (RSA) to mearsure the alignment between 16 mainstream LLMs and fMRI signals of the brain. We empirically investigate the impact of a variety of factors (e.g., model scaling, alignment training, instruction appending) on such LLM-brain alignment. Experimental results indicate that model scaling is positively correlated with LLM-brain similarity, and alignment training can significantly improve LLM-brain similarity. Additionally, the performance of a wide range of LLM evaluations (e.g., MMLU, Chatbot Arena) is highly correlated with the LLM-brain similarity.
A Comprehensive Evaluation of Quantization Strategies for Large Language Models
Feb 26, 2024



Increasing the number of parameters in large language models (LLMs) usually improves performance in downstream tasks but raises compute and memory costs, making deployment difficult in resource-limited settings. Quantization techniques, which reduce the bits needed for model weights or activations with minimal performance loss, have become popular due to the rise of LLMs. However, most quantization studies use pre-trained LLMs, and the impact of quantization on instruction-tuned LLMs and the relationship between perplexity and benchmark performance of quantized LLMs are not well understood. Evaluation of quantized LLMs is often limited to language modeling and a few classification tasks, leaving their performance on other benchmarks unclear. To address these gaps, we propose a structured evaluation framework consisting of three critical dimensions: (1) knowledge \& capacity, (2) alignment, and (3) efficiency, and conduct extensive experiments across ten diverse benchmarks. Our experimental results indicate that LLMs with 4-bit quantization can retain performance comparable to their non-quantized counterparts, and perplexity can serve as a proxy metric for quantized LLMs on most benchmarks. Furthermore, quantized LLMs with larger parameter scales can outperform smaller LLMs. Despite the memory savings achieved through quantization, it can also slow down the inference speed of LLMs. Consequently, substantial engineering efforts and hardware support are imperative to achieve a balanced optimization of decoding speed and memory consumption in the context of quantized LLMs.
RoleEval: A Bilingual Role Evaluation Benchmark for Large Language Models
Dec 26, 2023The rapid evolution of large language models (LLMs) necessitates effective benchmarks for evaluating their role knowledge, which is essential for establishing connections with the real world and providing more immersive interactions. This paper introduces RoleEval, a bilingual benchmark designed to assess the memorization, utilization, and reasoning capabilities of role knowledge. RoleEval comprises RoleEval-Global (including internationally recognized characters) and RoleEval-Chinese (including characters popular in China), with 6,000 Chinese-English parallel multiple-choice questions focusing on 300 influential people and fictional characters drawn from a variety of domains including celebrities, anime, comics, movies, TV series, games, and fiction. These questions cover basic knowledge and multi-hop reasoning abilities, aiming to systematically probe various aspects such as personal information, relationships, abilities, and experiences of the characters. To maintain high standards, we perform a hybrid quality check process combining automatic and human verification, ensuring that the questions are diverse, challenging, and discriminative. Our extensive evaluations of RoleEval across various open-source and proprietary large language models, under both the zero- and few-shot settings, reveal insightful findings. Notably, while GPT-4 outperforms other models on RoleEval-Global, Chinese LLMs excel on RoleEval-Chinese, highlighting significant knowledge distribution differences. We expect that RoleEval will highlight the significance of assessing role knowledge for foundation models across various languages and cultural settings.
CORECODE: A Common Sense Annotated Dialogue Dataset with Benchmark Tasks for Chinese Large Language Models
Dec 20, 2023



As an indispensable ingredient of intelligence, commonsense reasoning is crucial for large language models (LLMs) in real-world scenarios. In this paper, we propose CORECODE, a dataset that contains abundant commonsense knowledge manually annotated on dyadic dialogues, to evaluate the commonsense reasoning and commonsense conflict detection capabilities of Chinese LLMs. We categorize commonsense knowledge in everyday conversations into three dimensions: entity, event, and social interaction. For easy and consistent annotation, we standardize the form of commonsense knowledge annotation in open-domain dialogues as "domain: slot = value". A total of 9 domains and 37 slots are defined to capture diverse commonsense knowledge. With these pre-defined domains and slots, we collect 76,787 commonsense knowledge annotations from 19,700 dialogues through crowdsourcing. To evaluate and enhance the commonsense reasoning capability for LLMs on the curated dataset, we establish a series of dialogue-level reasoning and detection tasks, including commonsense knowledge filling, commonsense knowledge generation, commonsense conflict phrase detection, domain identification, slot identification, and event causal inference. A wide variety of existing open-source Chinese LLMs are evaluated with these tasks on our dataset. Experimental results demonstrate that these models are not competent to predict CORECODE's plentiful reasoning content, and even ChatGPT could only achieve 0.275 and 0.084 accuracy on the domain identification and slot identification tasks under the zero-shot setting. We release the data and codes of CORECODE at https://github.com/danshi777/CORECODE to promote commonsense reasoning evaluation and study of LLMs in the context of daily conversations.
AI-driven emergence of frequency information non-uniform distribution via THz metasurface spectrum prediction
Dec 05, 2023



Recently, artificial intelligence has been extensively deployed across various scientific disciplines, optimizing and guiding the progression of experiments through the integration of abundant datasets, whilst continuously probing the vast theoretical space encapsulated within the data. Particularly, deep learning models, due to their end-to-end adaptive learning capabilities, are capable of autonomously learning intrinsic data features, thereby transcending the limitations of traditional experience to a certain extent. Here, we unveil previously unreported information characteristics pertaining to different frequencies emerged during our work on predicting the terahertz spectral modulation effects of metasurfaces based on AI-prediction. Moreover, we have substantiated that our proposed methodology of simply adding supplementary multi-frequency inputs to the existing dataset during the target spectral prediction process can significantly enhance the predictive accuracy of the network. This approach effectively optimizes the utilization of existing datasets and paves the way for interdisciplinary research and applications in artificial intelligence, chemistry, composite material design, biomedicine, and other fields.
FollowEval: A Multi-Dimensional Benchmark for Assessing the Instruction-Following Capability of Large Language Models
Nov 16, 2023


The effective assessment of the instruction-following ability of large language models (LLMs) is of paramount importance. A model that cannot adhere to human instructions might be not able to provide reliable and helpful responses. In pursuit of this goal, various benchmarks have been constructed to evaluate the instruction-following capacity of these models. However, these benchmarks are limited to a single language and are constructed using automated approaches, which restricts their applicability and the quality of the test examples they contain. To bridge this gap, we introduce the FollowEval benchmark in this paper. This benchmark is composed of instances in both English and Chinese, and all test examples are crafted by human experts. Furthermore, the FollowEval benchmark is designed to assess LLMs across five critical dimensions of instruction following: string manipulation, commonsense reasoning, logical reasoning, spatial reasoning, and response constraints. To enhance the complexity and present a sufficient challenge, each test example is designed to evaluate more than one dimension. We have evaluated various LLMs using the FollowEval benchmark and found that their performance significantly lags behind that of humans. This highlights the considerable room for improvement in the instruction-following ability of these models.
Language Representation Projection: Can We Transfer Factual Knowledge across Languages in Multilingual Language Models?
Nov 07, 2023



Multilingual pretrained language models serve as repositories of multilingual factual knowledge. Nevertheless, a substantial performance gap of factual knowledge probing exists between high-resource languages and low-resource languages, suggesting limited implicit factual knowledge transfer across languages in multilingual pretrained language models. This paper investigates the feasibility of explicitly transferring relatively rich factual knowledge from English to non-English languages. To accomplish this, we propose two parameter-free $\textbf{L}$anguage $\textbf{R}$epresentation $\textbf{P}$rojection modules (LRP2). The first module converts non-English representations into English-like equivalents, while the second module reverts English-like representations back into representations of the corresponding non-English language. Experimental results on the mLAMA dataset demonstrate that LRP2 significantly improves factual knowledge retrieval accuracy and facilitates knowledge transferability across diverse non-English languages. We further investigate the working mechanism of LRP2 from the perspectives of representation space and cross-lingual knowledge neuron.
Towards a Deep Understanding of Multilingual End-to-End Speech Translation
Oct 31, 2023



In this paper, we employ Singular Value Canonical Correlation Analysis (SVCCA) to analyze representations learnt in a multilingual end-to-end speech translation model trained over 22 languages. SVCCA enables us to estimate representational similarity across languages and layers, enhancing our understanding of the functionality of multilingual speech translation and its potential connection to multilingual neural machine translation. The multilingual speech translation model is trained on the CoVoST 2 dataset in all possible directions, and we utilize LASER to extract parallel bitext data for SVCCA analysis. We derive three major findings from our analysis: (I) Linguistic similarity loses its efficacy in multilingual speech translation when the training data for a specific language is limited. (II) Enhanced encoder representations and well-aligned audio-text data significantly improve translation quality, surpassing the bilingual counterparts when the training data is not compromised. (III) The encoder representations of multilingual speech translation demonstrate superior performance in predicting phonetic features in linguistic typology prediction. With these findings, we propose that releasing the constraint of limited data for low-resource languages and subsequently combining them with linguistically related high-resource languages could offer a more effective approach for multilingual end-to-end speech translation.
Is Robustness Transferable across Languages in Multilingual Neural Machine Translation?
Oct 31, 2023



Robustness, the ability of models to maintain performance in the face of perturbations, is critical for developing reliable NLP systems. Recent studies have shown promising results in improving the robustness of models through adversarial training and data augmentation. However, in machine translation, most of these studies have focused on bilingual machine translation with a single translation direction. In this paper, we investigate the transferability of robustness across different languages in multilingual neural machine translation. We propose a robustness transfer analysis protocol and conduct a series of experiments. In particular, we use character-, word-, and multi-level noises to attack the specific translation direction of the multilingual neural machine translation model and evaluate the robustness of other translation directions. Our findings demonstrate that the robustness gained in one translation direction can indeed transfer to other translation directions. Additionally, we empirically find scenarios where robustness to character-level noise and word-level noise is more likely to transfer.
Evaluating Large Language Models: A Comprehensive Survey
Oct 31, 2023Large language models (LLMs) have demonstrated remarkable capabilities across a broad spectrum of tasks. They have attracted significant attention and been deployed in numerous downstream applications. Nevertheless, akin to a double-edged sword, LLMs also present potential risks. They could suffer from private data leaks or yield inappropriate, harmful, or misleading content. Additionally, the rapid progress of LLMs raises concerns about the potential emergence of superintelligent systems without adequate safeguards. To effectively capitalize on LLM capacities as well as ensure their safe and beneficial development, it is critical to conduct a rigorous and comprehensive evaluation of LLMs. This survey endeavors to offer a panoramic perspective on the evaluation of LLMs. We categorize the evaluation of LLMs into three major groups: knowledge and capability evaluation, alignment evaluation and safety evaluation. In addition to the comprehensive review on the evaluation methodologies and benchmarks on these three aspects, we collate a compendium of evaluations pertaining to LLMs' performance in specialized domains, and discuss the construction of comprehensive evaluation platforms that cover LLM evaluations on capabilities, alignment, safety, and applicability. We hope that this comprehensive overview will stimulate further research interests in the evaluation of LLMs, with the ultimate goal of making evaluation serve as a cornerstone in guiding the responsible development of LLMs. We envision that this will channel their evolution into a direction that maximizes societal benefit while minimizing potential risks. A curated list of related papers has been publicly available at https://github.com/tjunlp-lab/Awesome-LLMs-Evaluation-Papers.