 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle-Consistent Adversarial Autoencoders for Unsupervised Text Style Transfer
Oct 02, 2020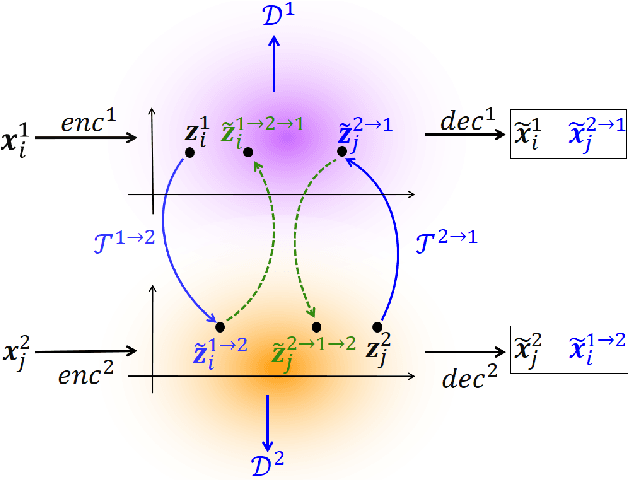

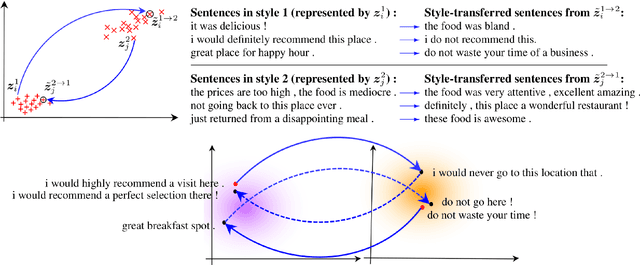
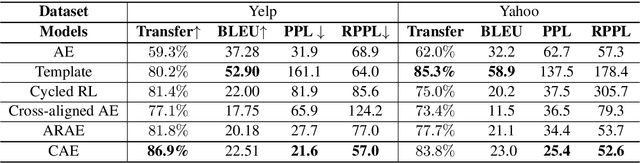
Unsupervised text style transfer is full of challenges due to the lack of parallel data and difficulties in content preservation. In this paper, we propose a novel neural approach to unsupervised text style transfer, which we refer to as Cycle-consistent Adversarial autoEncoders (CAE) trained from non-parallel data. CAE consists of three essential components: (1) LSTM autoencoders that encode a text in one style into its latent representation and decode an encoded representation into its original text or a transferred representation into a style-transferred text, (2) adversarial style transfer networks that use an adversarially trained generator to transform a latent representation in one style into a representation in another style, and (3) a cycle-consistent constraint that enhances the capacity of the adversarial style transfer networks in content preservation. The entire CAE with these three components can be trained end-to-end. Extensive experiments and in-depth analyses on two widely-used public datasets consistently validate the effectiveness of proposed CAE in both style transfer and content preservation against several strong baselines in terms of four automatic evaluation metrics and human evaluation.
Bootstrapping Named Entity Recognition in E-Commerce with Positive Unlabeled Learning
May 22, 2020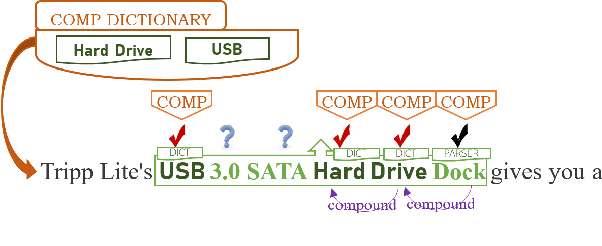
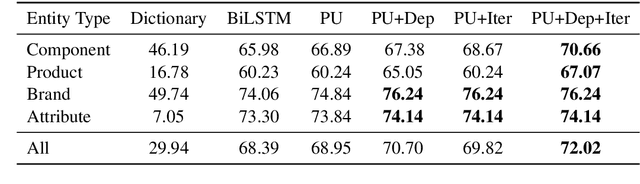
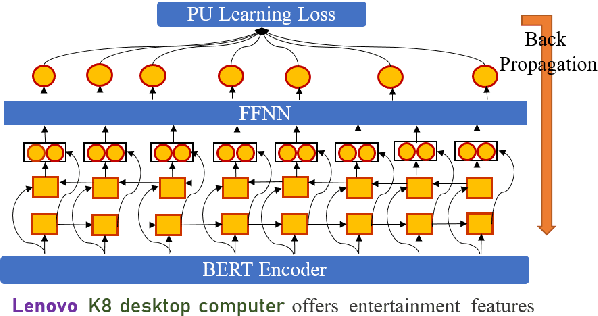
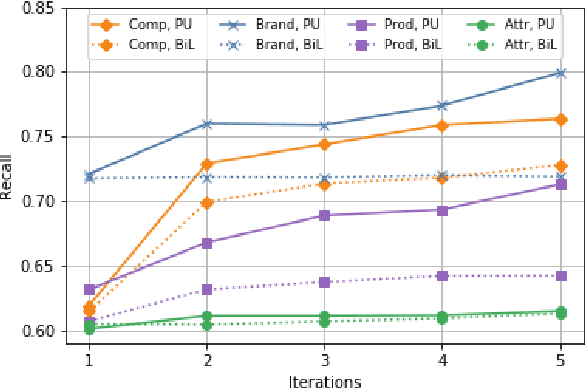
Named Entity Recognition (NER) in domains like e-commerce is an understudied problem due to the lack of annotated datasets. Recognizing novel entity types in this domain, such as products, components, and attributes, is challenging because of their linguistic complexity and the low coverage of existing knowledge resources. To address this problem, we present a bootstrapped positive-unlabeled learning algorithm that integrates domain-specific linguistic features to quickly and efficiently expand the seed dictionary. The model achieves an average F1 score of 72.02% on a novel dataset of product descriptions, an improvement of 3.63% over a baseline BiLSTM classifier, and in particular exhibits better recall (4.96% on average).
GECOR: An End-to-End Generative Ellipsis and Co-reference Resolution Model for Task-Oriented Dialogue
Sep 26, 2019
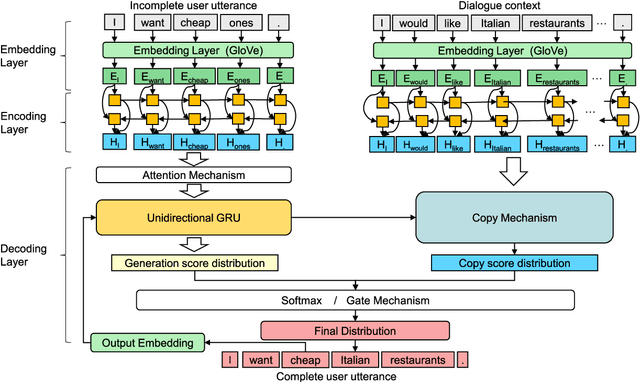
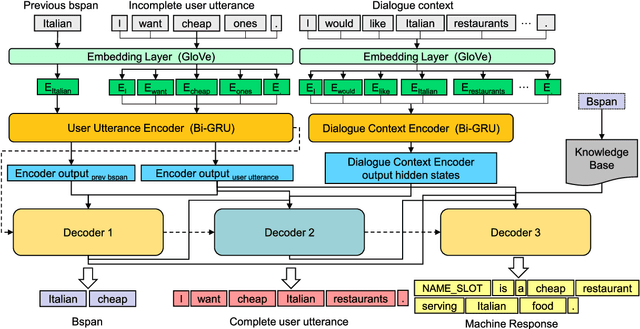

Ellipsis and co-reference are common and ubiquitous especially in multi-turn dialogues. In this paper, we treat the resolution of ellipsis and co-reference in dialogue as a problem of generating omitted or referred expressions from the dialogue context. We therefore propose a unified end-to-end Generative Ellipsis and CO-reference Resolution model (GECOR) in the context of dialogue. The model can generate a new pragmatically complete user utterance by alternating the generation and copy mode for each user utterance. A multi-task learning framework is further proposed to integrate the GECOR into an end-to-end task-oriented dialogue. In order to train both the GECOR and the multi-task learning framework, we manually construct a new dataset on the basis of the public dataset CamRest676 with both ellipsis and co-reference annotation. On this dataset, intrinsic evaluations on the resolution of ellipsis and co-reference show that the GECOR model significantly outperforms the sequence-to-sequence (seq2seq) baseline model in terms of EM, BLEU and F1 while extrinsic evaluations on the downstream dialogue task demonstrate that our multi-task learning framework with GECOR achieves a higher success rate of task completion than TSCP, a state-of-the-art end-to-end task-oriented dialogue model.