 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Corpus and Evaluation Framework for Deeper Understanding of Commonsense Stories
Apr 06, 2016
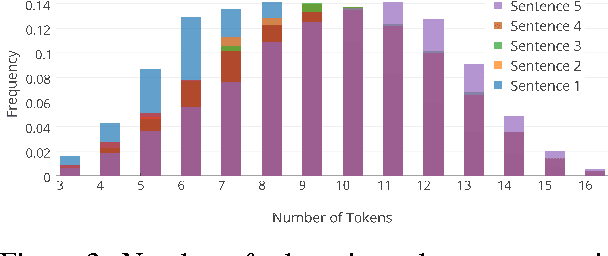

Representation and learning of commonsense knowledge is one of the foundational problems in the quest to enable deep language understanding. This issue is particularly challenging for understanding casual and correlational relationships between events. While this topic has received a lot of interest in the NLP community, research has been hindered by the lack of a proper evaluation framework. This paper attempts to address this problem with a new framework for evaluating story understanding and script learning: the 'Story Cloze Test'. This test requires a system to choose the correct ending to a four-sentence story. We created a new corpus of ~50k five-sentence commonsense stories, ROCStories, to enable this evaluation. This corpus is unique in two ways: (1) it captures a rich set of causal and temporal commonsense relations between daily events, and (2) it is a high quality collection of everyday life stories that can also be used for story generation. Experimental evaluation shows that a host of baselines and state-of-the-art models based on shallow language understanding struggle to achieve a high score on the Story Cloze Test. We discuss these implications for script and story learning, and offer suggestions for deeper language understanding.
Don't Just Listen, Use Your Imagination: Leveraging Visual Common Sense for Non-Visual Tasks
Jul 29, 2015
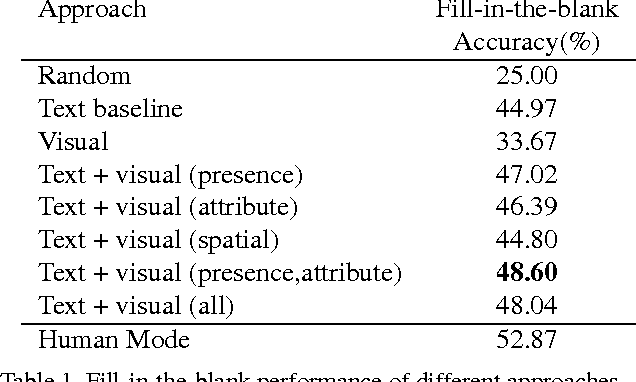
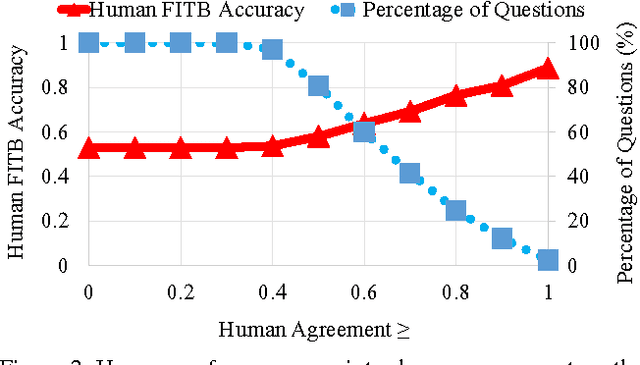
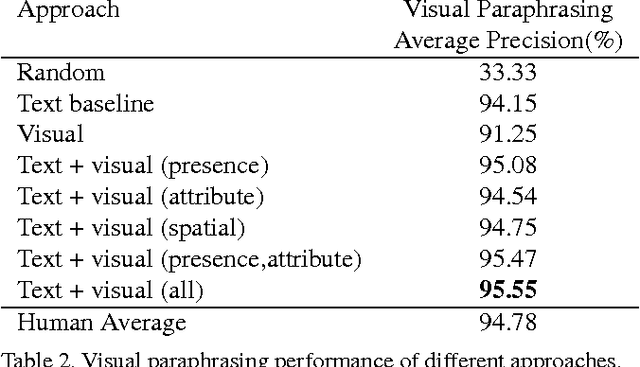
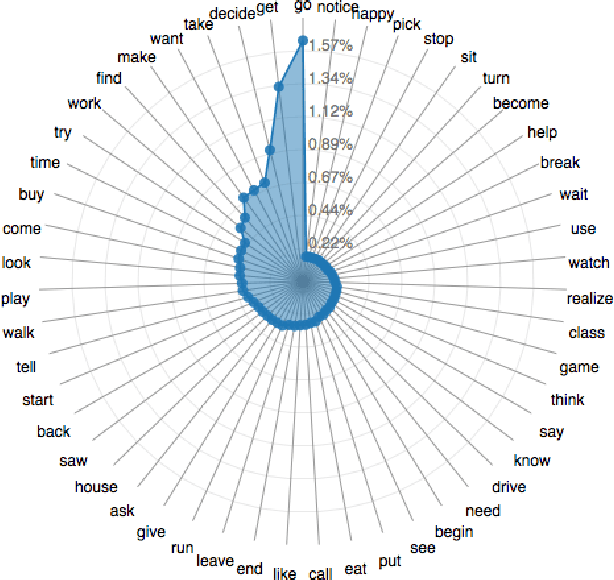
Artificial agents today can answer factual questions. But they fall short on questions that require common sense reasoning. Perhaps this is because most existing common sense databases rely on text to learn and represent knowledge. But much of common sense knowledge is unwritten - partly because it tends not to be interesting enough to talk about, and partly because some common sense is unnatural to articulate in text. While unwritten, it is not unseen. In this paper we leverage semantic common sense knowledge learned from images - i.e. visual common sense - in two textual tasks: fill-in-the-blank and visual paraphrasing. We propose to "imagine" the scene behind the text, and leverage visual cues from the "imagined" scenes in addition to textual cues while answering these questions. We imagine the scenes as a visual abstraction. Our approach outperforms a strong text-only baseline on these tasks. Our proposed tasks can serve as benchmarks to quantitatively evaluate progress in solving tasks that go "beyond recognition". Our code and datasets are publicly available.
CIDEr: Consensus-based Image Description Evaluation
Jun 03, 2015
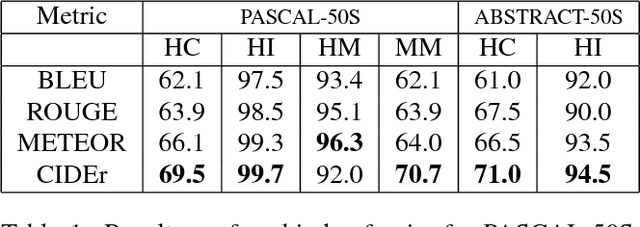

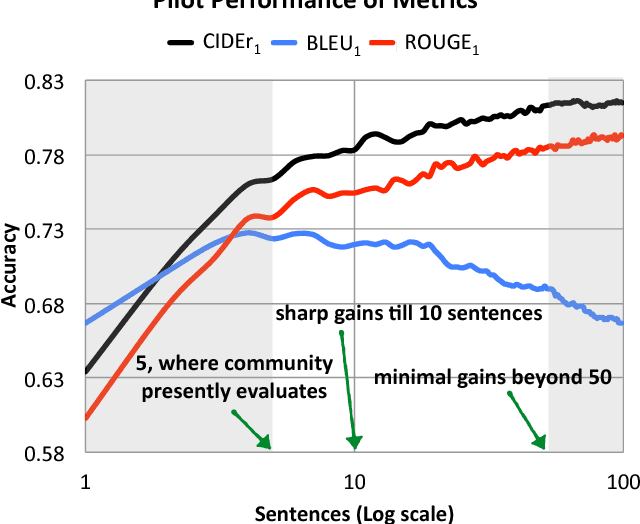
Automatically describing an image with a sentence is a long-standing challenge in computer vision and natural language processing. Due to recent progress in object detection, attribute classification, action recognition, etc., there is renewed interest in this area. However, evaluating the quality of descriptions has proven to be challenging. We propose a novel paradigm for evaluating image descriptions that uses human consensus. This paradigm consists of three main parts: a new triplet-based method of collecting human annotations to measure consensus, a new automated metric (CIDEr) that captures consensus, and two new datasets: PASCAL-50S and ABSTRACT-50S that contain 50 sentences describing each image. Our simple metric captures human judgment of consensus better than existing metrics across sentences generated by various sources. We also evaluate five state-of-the-art image description approaches using this new protocol and provide a benchmark for future comparisons. A version of CIDEr named CIDEr-D is available as a part of MS COCO evaluation server to enable systematic evaluation and benchmarking.
Understanding Image Virality
May 26, 2015
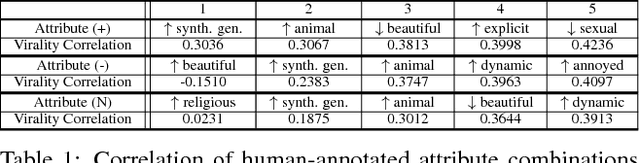
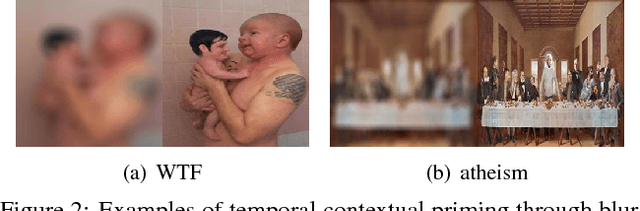
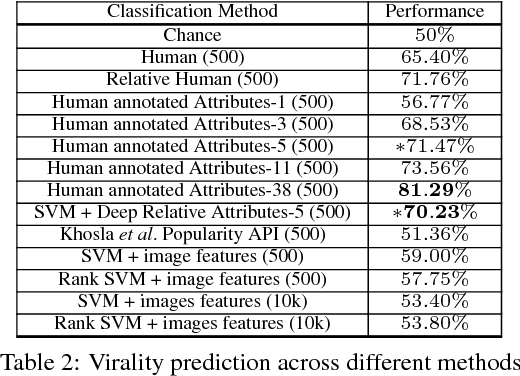
Virality of online content on social networking websites is an important but esoteric phenomenon often studied in fields like marketing, psychology and data mining. In this paper we study viral images from a computer vision perspective. We introduce three new image datasets from Reddit, and define a virality score using Reddit metadata. We train classifiers with state-of-the-art image features to predict virality of individual images, relative virality in pairs of images, and the dominant topic of a viral image. We also compare machine performance to human performance on these tasks. We find that computers perform poorly with low level features, and high level information is critical for predicting virality. We encode semantic information through relative attributes. We identify the 5 key visual attributes that correlate with virality. We create an attribute-based characterization of images that can predict relative virality with 68.10% accuracy (SVM+Deep Relative Attributes) -- better than humans at 60.12%. Finally, we study how human prediction of image virality varies with different `contexts' in which the images are viewed, such as the influence of neighbouring images, images recently viewed, as well as the image title or caption. This work is a first step in understanding the complex but important phenomenon of image virality. Our datasets and annotations will be made publicly available.
WhittleSearch: Interactive Image Search with Relative Attribute Feedback
May 18, 2015



We propose a novel mode of feedback for image search, where a user describes which properties of exemplar images should be adjusted in order to more closely match his/her mental model of the image sought. For example, perusing image results for a query "black shoes", the user might state, "Show me shoe images like these, but sportier." Offline, our approach first learns a set of ranking functions, each of which predicts the relative strength of a nameable attribute in an image (e.g., sportiness). At query time, the system presents the user with a set of exemplar images, and the user relates them to his/her target image with comparative statements. Using a series of such constraints in the multi-dimensional attribute space, our method iteratively updates its relevance function and re-ranks the database of images. To determine which exemplar images receive feedback from the user, we present two variants of the approach: one where the feedback is user-initiated and another where the feedback is actively system-initiated. In either case, our approach allows a user to efficiently "whittle away" irrelevant portions of the visual feature space, using semantic language to precisely communicate her preferences to the system. We demonstrate our technique for refining image search for people, products, and scenes, and we show that it outperforms traditional binary relevance feedback in terms of search speed and accuracy. In addition, the ordinal nature of relative attributes helps make our active approach efficient -- both computationally for the machine when selecting the reference images, and for the user by requiring less user interaction than conventional passive and active methods.
* Published in the International Journal of Computer Vision (IJCV), April 2015. The final publication is available at Springer via http://dx.doi.org/10.1007/s11263-015-0814-0
Image Specificity
Apr 16, 2015
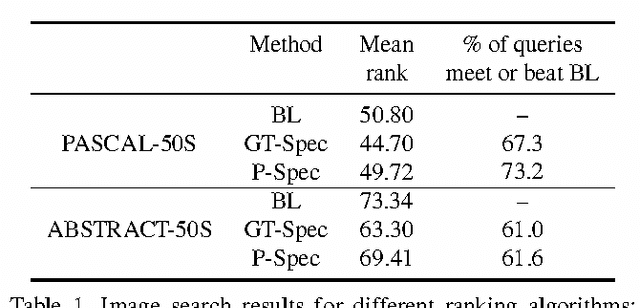

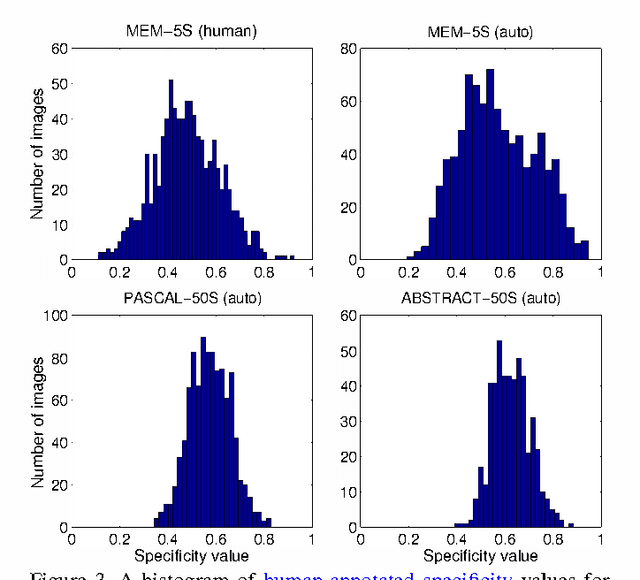
For some images, descriptions written by multiple people are consistent with each other. But for other images, descriptions across people vary considerably. In other words, some images are specific $-$ they elicit consistent descriptions from different people $-$ while other images are ambiguous. Applications involving images and text can benefit from an understanding of which images are specific and which ones are ambiguous. For instance, consider text-based image retrieval. If a query description is moderately similar to the caption (or reference description) of an ambiguous image, that query may be considered a decent match to the image. But if the image is very specific, a moderate similarity between the query and the reference description may not be sufficient to retrieve the image. In this paper, we introduce the notion of image specificity. We present two mechanisms to measure specificity given multiple descriptions of an image: an automated measure and a measure that relies on human judgement. We analyze image specificity with respect to image content and properties to better understand what makes an image specific. We then train models to automatically predict the specificity of an image from image features alone without requiring textual descriptions of the image. Finally, we show that modeling image specificity leads to improvements in a text-based image retrieval application.
Collecting Image Description Datasets using Crowdsourcing
Nov 12, 2014



We describe our two new datasets with images described by humans. Both the datasets were collected using Amazon Mechanical Turk, a crowdsourcing platform. The two datasets contain significantly more descriptions per image than other existing datasets. One is based on a popular image description dataset called the UIUC Pascal Sentence Dataset, whereas the other is based on the Abstract Scenes dataset con- taining images made from clipart objects. In this paper we describe our interfaces, analyze some properties of and show example descriptions from our two datasets.
Human-Machine CRFs for Identifying Bottlenecks in Holistic Scene Understanding
Jun 16, 2014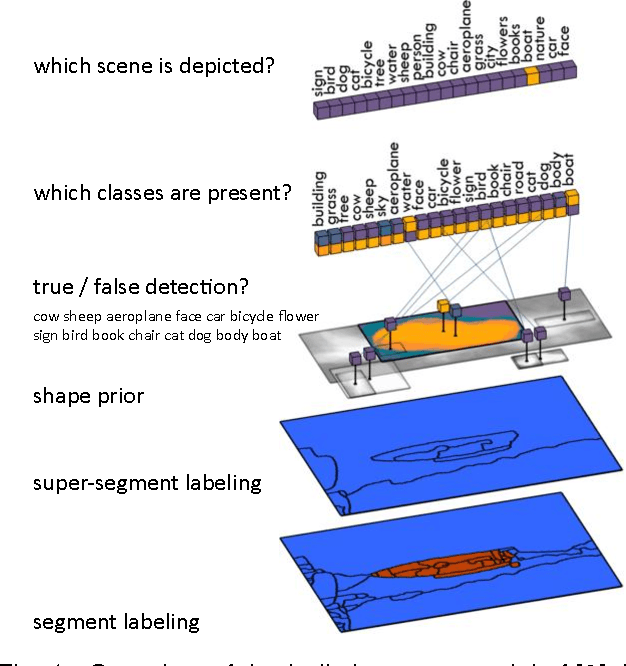



Recent trends in image understanding have pushed for holistic scene understanding models that jointly reason about various tasks such as object detection, scene recognition, shape analysis, contextual reasoning, and local appearance based classifiers. In this work, we are interested in understanding the roles of these different tasks in improved scene understanding, in particular semantic segmentation, object detection and scene recognition. Towards this goal, we "plug-in" human subjects for each of the various components in a state-of-the-art conditional random field model. Comparisons among various hybrid human-machine CRFs give us indications of how much "head room" there is to improve scene understanding by focusing research efforts on various individual tasks.