 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Walk with SGD
May 30, 2018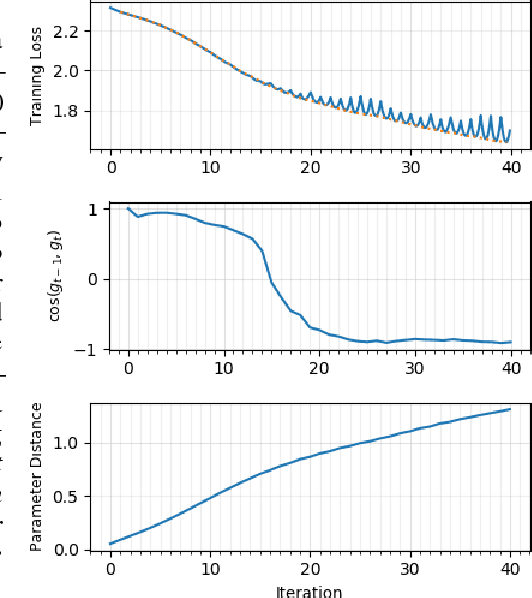
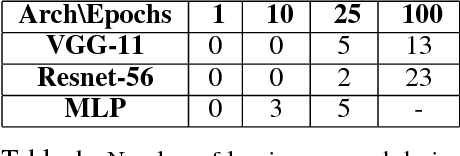
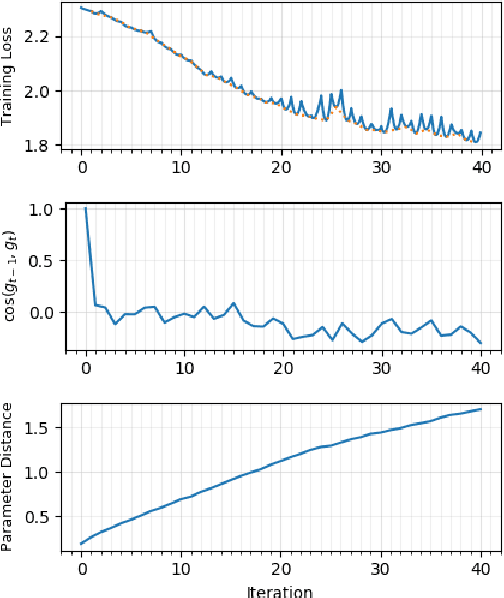
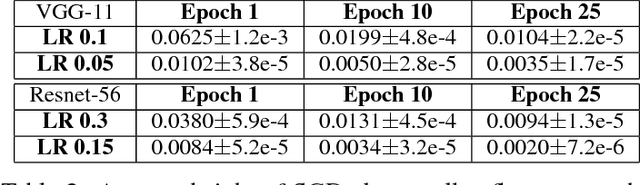
We present novel empirical observations regarding how stochastic gradient descent (SGD) navigates the loss landscape of over-parametrized deep neural networks (DNNs). These observations expose the qualitatively different roles of learning rate and batch-size in DNN optimization and generalization. Specifically we study the DNN loss surface along the trajectory of SGD by interpolating the loss surface between parameters from consecutive \textit{iterations} and tracking various metrics during training. We find that the loss interpolation between parameters before and after each training iteration's update is roughly convex with a minimum (\textit{valley floor}) in between for most of the training. Based on this and other metrics, we deduce that for most of the training update steps, SGD moves in valley like regions of the loss surface by jumping from one valley wall to another at a height above the valley floor. This 'bouncing between walls at a height' mechanism helps SGD traverse larger distance for small batch sizes and large learning rates which we find play qualitatively different roles in the dynamics. While a large learning rate maintains a large height from the valley floor, a small batch size injects noise facilitating exploration. We find this mechanism is crucial for generalization because the valley floor has barriers and this exploration above the valley floor allows SGD to quickly travel far away from the initialization point (without being affected by barriers) and find flatter regions, corresponding to better generalization.
Fraternal Dropout
Mar 28, 2018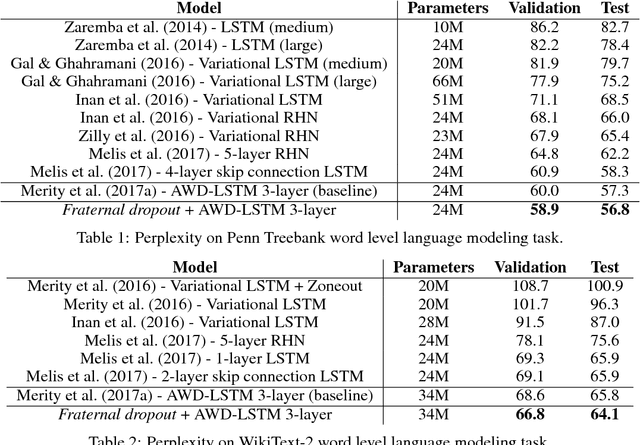
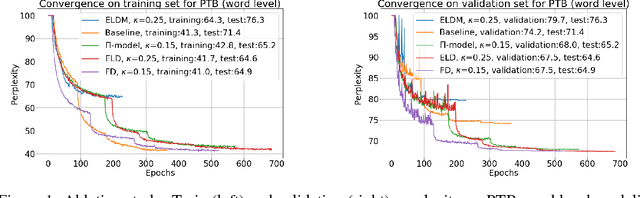
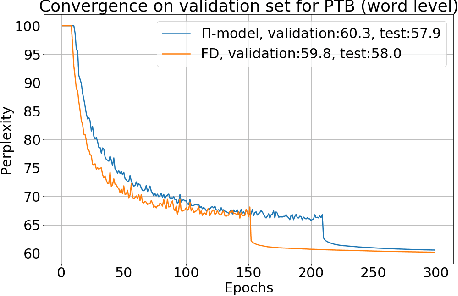

Recurrent neural networks (RNNs) are important class of architectures among neural networks useful for language modeling and sequential prediction. However, optimizing RNNs is known to be harder compared to feed-forward neural networks. A number of techniques have been proposed in literature to address this problem. In this paper we propose a simple technique called fraternal dropout that takes advantage of dropout to achieve this goal. Specifically, we propose to train two identical copies of an RNN (that share parameters) with different dropout masks while minimizing the difference between their (pre-softmax) predictions. In this way our regularization encourages the representations of RNNs to be invariant to dropout mask, thus being robust. We show that our regularization term is upper bounded by the expectation-linear dropout objective which has been shown to address the gap due to the difference between the train and inference phases of dropout. We evaluate our model and achieve state-of-the-art results in sequence modeling tasks on two benchmark datasets - Penn Treebank and Wikitext-2. We also show that our approach leads to performance improvement by a significant margin in image captioning (Microsoft COCO) and semi-supervised (CIFAR-10) tasks.
Residual Connections Encourage Iterative Inference
Mar 08, 2018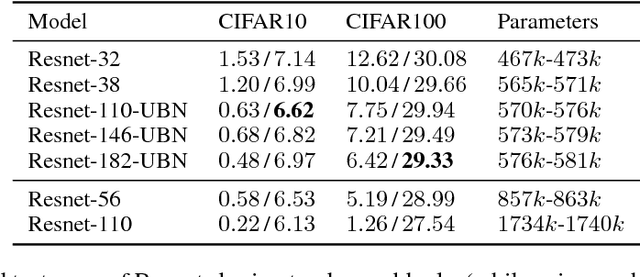



Residual networks (Resnets) have become a prominent architecture in deep learning. However, a comprehensive understanding of Resnets is still a topic of ongoing research. A recent view argues that Resnets perform iterative refinement of features. We attempt to further expose properties of this aspect. To this end, we study Resnets both analytically and empirically. We formalize the notion of iterative refinement in Resnets by showing that residual connections naturally encourage features of residual blocks to move along the negative gradient of loss as we go from one block to the next. In addition, our empirical analysis suggests that Resnets are able to perform both representation learning and iterative refinement. In general, a Resnet block tends to concentrate representation learning behavior in the first few layers while higher layers perform iterative refinement of features. Finally we observe that sharing residual layers naively leads to representation explosion and counterintuitively, overfitting, and we show that simple existing strategies can help alleviating this problem.
Variational Bi-LSTMs
Nov 15, 2017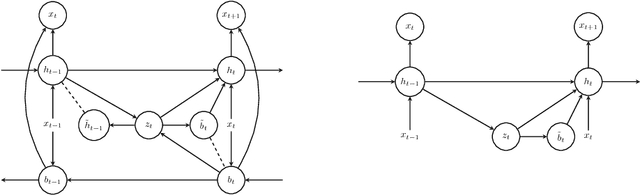
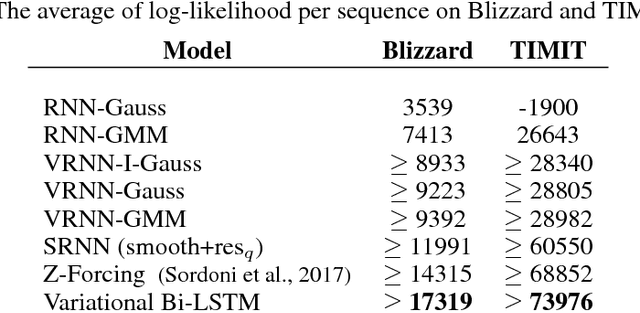
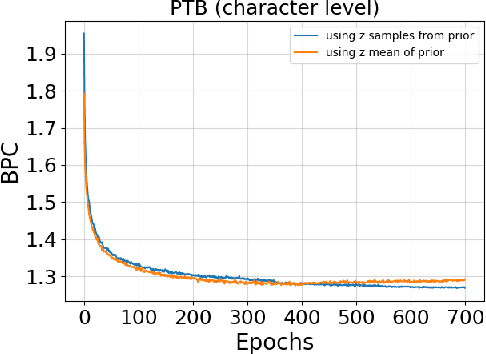
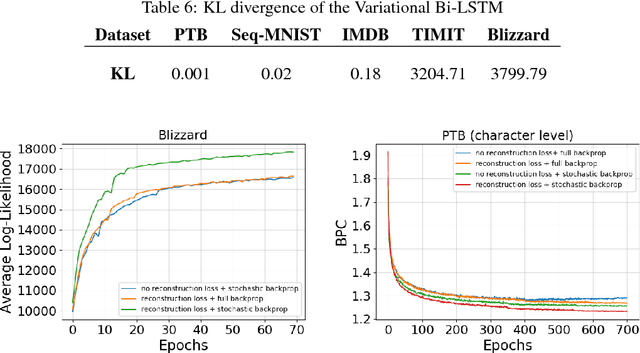
Recurrent neural networks like long short-term memory (LSTM) are important architectures for sequential prediction tasks. LSTMs (and RNNs in general) model sequences along the forward time direction. Bidirectional LSTMs (Bi-LSTMs) on the other hand model sequences along both forward and backward directions and are generally known to perform better at such tasks because they capture a richer representation of the data. In the training of Bi-LSTMs, the forward and backward paths are learned independently. We propose a variant of the Bi-LSTM architecture, which we call Variational Bi-LSTM, that creates a channel between the two paths (during training, but which may be omitted during inference); thus optimizing the two paths jointly. We arrive at this joint objective for our model by minimizing a variational lower bound of the joint likelihood of the data sequence. Our model acts as a regularizer and encourages the two networks to inform each other in making their respective predictions using distinct information. We perform ablation studies to better understand the different components of our model and evaluate the method on various benchmarks, showing state-of-the-art performance.
On Optimality Conditions for Auto-Encoder Signal Recovery
Jul 13, 2017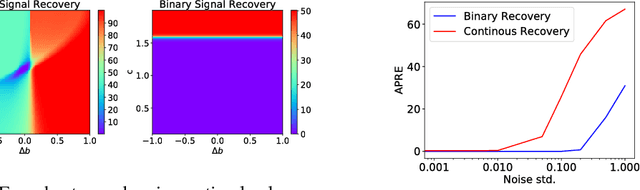
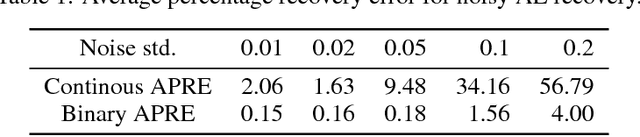
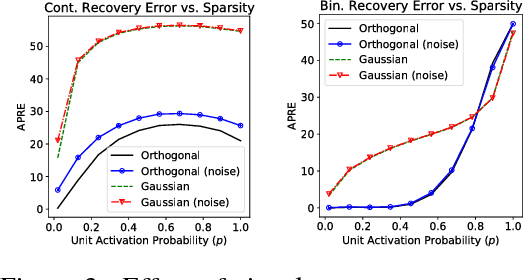
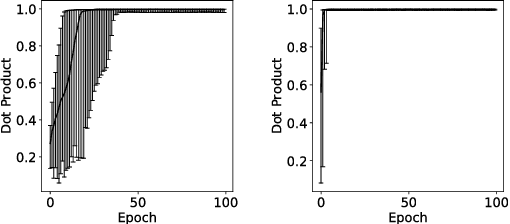
Auto-Encoders are unsupervised models that aim to learn patterns from observed data by minimizing a reconstruction cost. The useful representations learned are often found to be sparse and distributed. On the other hand, compressed sensing and sparse coding assume a data generating process, where the observed data is generated from some true latent signal source, and try to recover the corresponding signal from measurements. Looking at auto-encoders from this \textit{signal recovery perspective} enables us to have a more coherent view of these techniques. In this paper, in particular, we show that the \textit{true} hidden representation can be approximately recovered if the weight matrices are highly incoherent with unit $ \ell^{2} $ row length and the bias vectors takes the value (approximately) equal to the negative of the data mean. The recovery also becomes more and more accurate as the sparsity in hidden signals increases. Additionally, we empirically demonstrate that auto-encoders are capable of recovering the data generating dictionary when only data samples are given.
A Closer Look at Memorization in Deep Networks
Jul 01, 2017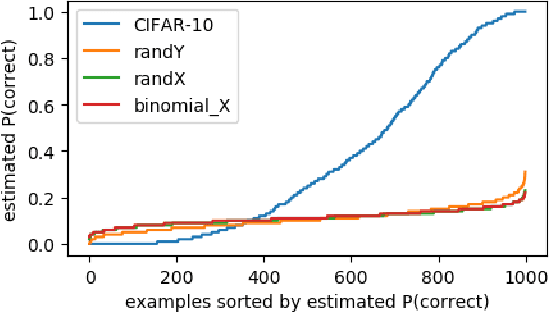

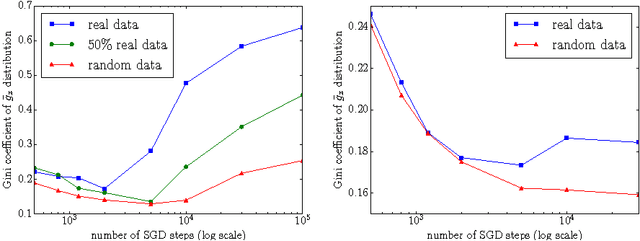
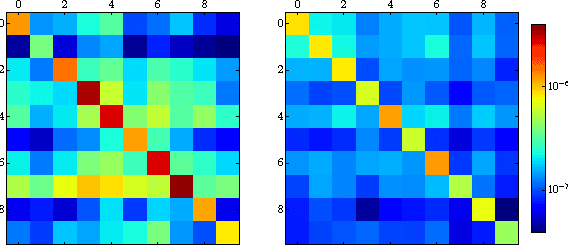
We examine the role of memorization in deep learning, drawing connections to capacity, generalization, and adversarial robustness. While deep networks are capable of memorizing noise data, our results suggest that they tend to prioritize learning simple patterns first. In our experiments, we expose qualitative differences in gradient-based optimization of deep neural networks (DNNs) on noise vs. real data. We also demonstrate that for appropriately tuned explicit regularization (e.g., dropout) we can degrade DNN training performance on noise datasets without compromising generalization on real data. Our analysis suggests that the notions of effective capacity which are dataset independent are unlikely to explain the generalization performance of deep networks when trained with gradient based methods because training data itself plays an important role in determining the degree of memorization.
Normalization Propagation: A Parametric Technique for Removing Internal Covariate Shift in Deep Networks
Jul 12, 2016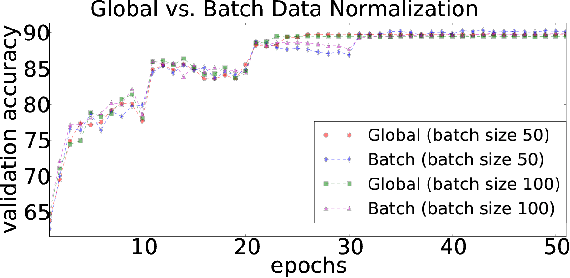
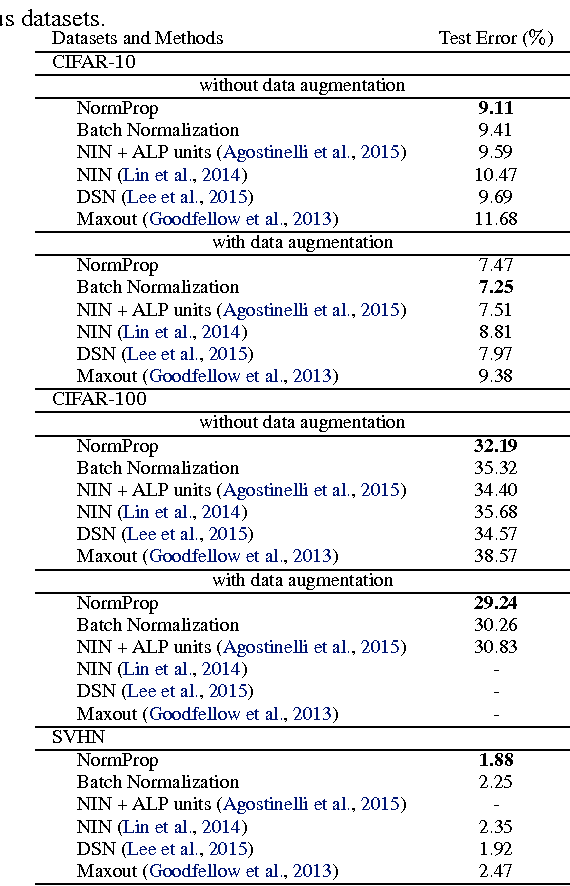

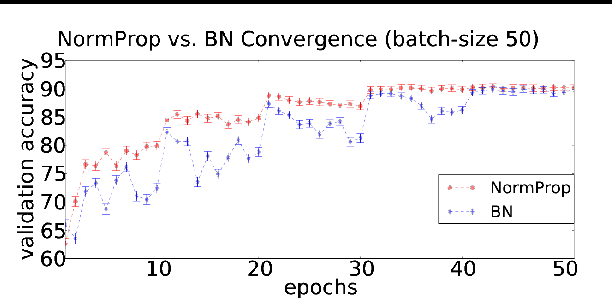
While the authors of Batch Normalization (BN) identify and address an important problem involved in training deep networks-- Internal Covariate Shift-- the current solution has certain drawbacks. Specifically, BN depends on batch statistics for layerwise input normalization during training which makes the estimates of mean and standard deviation of input (distribution) to hidden layers inaccurate for validation due to shifting parameter values (especially during initial training epochs). Also, BN cannot be used with batch-size 1 during training. We address these drawbacks by proposing a non-adaptive normalization technique for removing internal covariate shift, that we call Normalization Propagation. Our approach does not depend on batch statistics, but rather uses a data-independent parametric estimate of mean and standard-deviation in every layer thus being computationally faster compared with BN. We exploit the observation that the pre-activation before Rectified Linear Units follow Gaussian distribution in deep networks, and that once the first and second order statistics of any given dataset are normalized, we can forward propagate this normalization without the need for recalculating the approximate statistics for hidden layers.
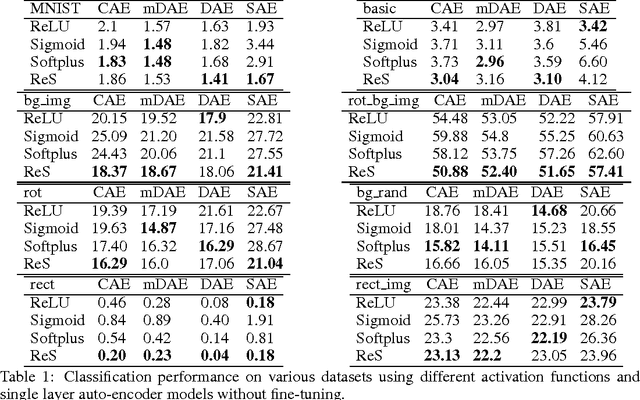
Why Regularized Auto-Encoders learn Sparse Representation?
Jun 17, 2016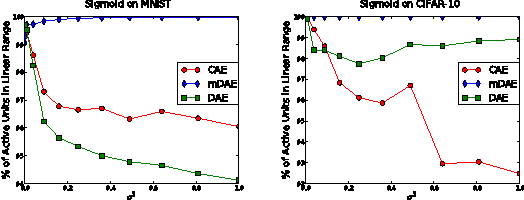
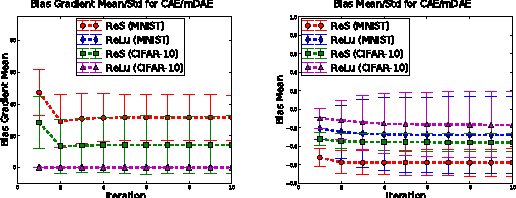
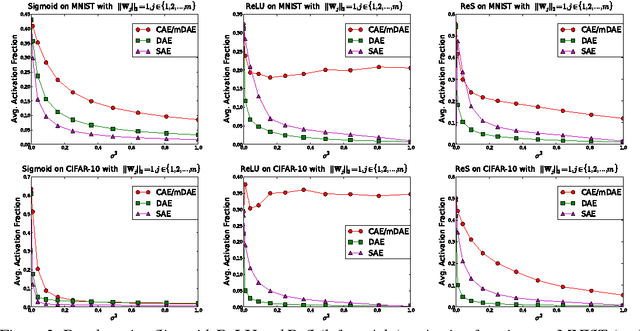
While the authors of Batch Normalization (BN) identify and address an important problem involved in training deep networks-- \textit{Internal Covariate Shift}-- the current solution has certain drawbacks. For instance, BN depends on batch statistics for layerwise input normalization during training which makes the estimates of mean and standard deviation of input (distribution) to hidden layers inaccurate due to shifting parameter values (especially during initial training epochs). Another fundamental problem with BN is that it cannot be used with batch-size $ 1 $ during training. We address these drawbacks of BN by proposing a non-adaptive normalization technique for removing covariate shift, that we call \textit{Normalization Propagation}. Our approach does not depend on batch statistics, but rather uses a data-independent parametric estimate of mean and standard-deviation in every layer thus being computationally faster compared with BN. We exploit the observation that the pre-activation before Rectified Linear Units follow Gaussian distribution in deep networks, and that once the first and second order statistics of any given dataset are normalized, we can forward propagate this normalization without the need for recalculating the approximate statistics for hidden layers.
Dimensionality Reduction with Subspace Structure Preservation
Apr 06, 2016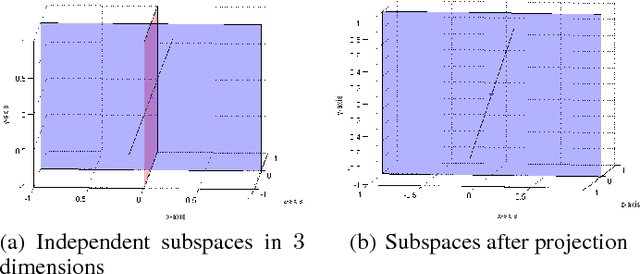

Modeling data as being sampled from a union of independent subspaces has been widely applied to a number of real world applications. However, dimensionality reduction approaches that theoretically preserve this independence assumption have not been well studied. Our key contribution is to show that $2K$ projection vectors are sufficient for the independence preservation of any $K$ class data sampled from a union of independent subspaces. It is this non-trivial observation that we use for designing our dimensionality reduction technique. In this paper, we propose a novel dimensionality reduction algorithm that theoretically preserves this structure for a given dataset. We support our theoretical analysis with empirical results on both synthetic and real world data achieving \textit{state-of-the-art} results compared to popular dimensionality reduction techniques.
Is Joint Training Better for Deep Auto-Encoders?
Jun 15, 2015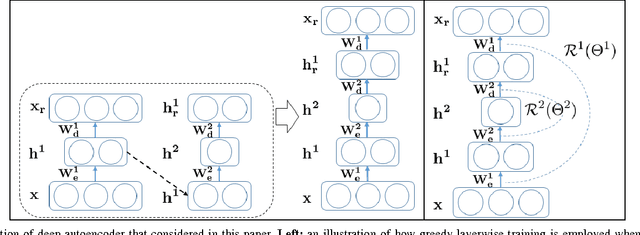
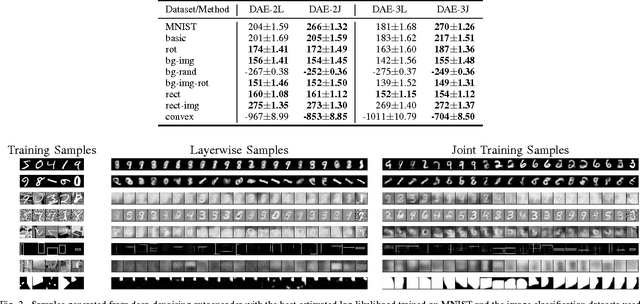
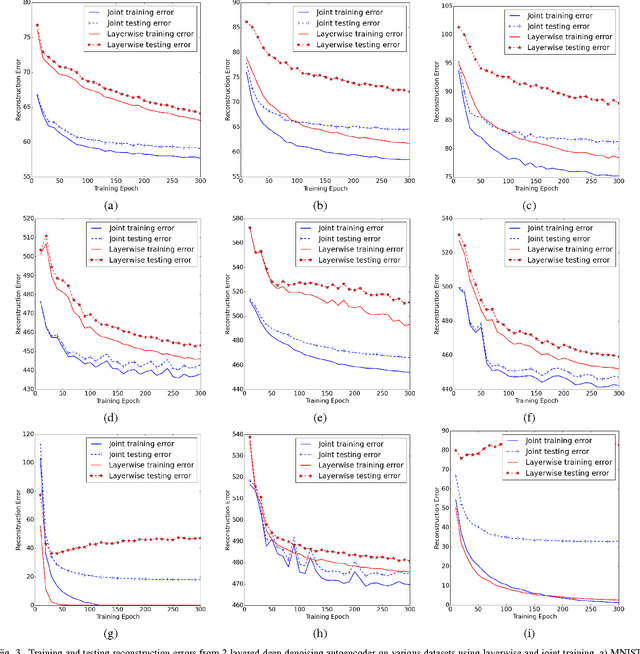

Traditionally, when generative models of data are developed via deep architectures, greedy layer-wise pre-training is employed. In a well-trained model, the lower layer of the architecture models the data distribution conditional upon the hidden variables, while the higher layers model the hidden distribution prior. But due to the greedy scheme of the layerwise training technique, the parameters of lower layers are fixed when training higher layers. This makes it extremely challenging for the model to learn the hidden distribution prior, which in turn leads to a suboptimal model for the data distribution. We therefore investigate joint training of deep autoencoders, where the architecture is viewed as one stack of two or more single-layer autoencoders. A single global reconstruction objective is jointly optimized, such that the objective for the single autoencoders at each layer acts as a local, layer-level regularizer. We empirically evaluate the performance of this joint training scheme and observe that it not only learns a better data model, but also learns better higher layer representations, which highlights its potential for unsupervised feature learning. In addition, we find that the usage of regularizations in the joint training scheme is crucial in achieving good performance. In the supervised setting, joint training also shows superior performance when training deeper models. The joint training framework can thus provide a platform for investigating more efficient usage of different types of regularizers, especially in light of the growing volumes of available unlabeled data.