 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRk-means: Fast Clustering for Relational Data
Oct 11, 2019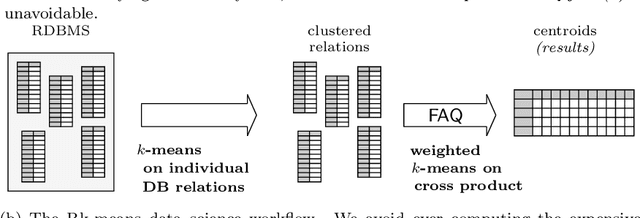
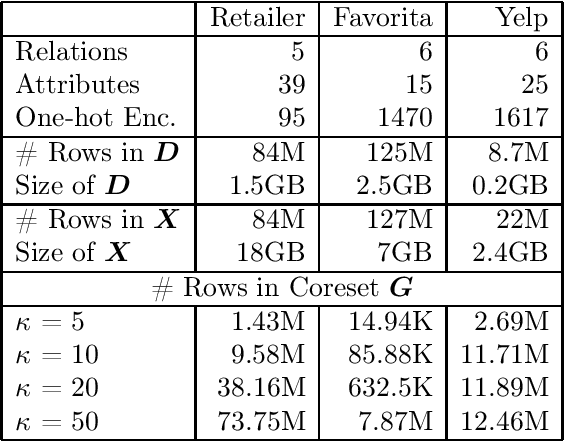
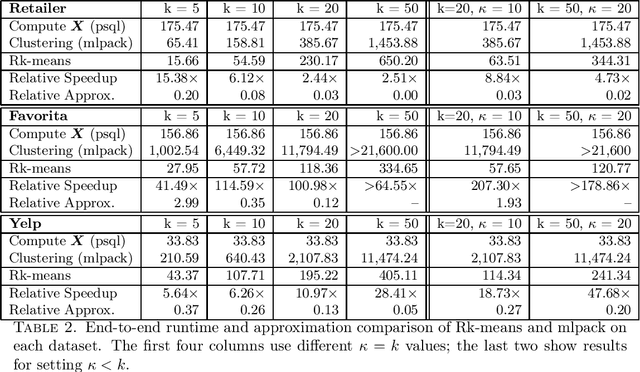
Conventional machine learning algorithms cannot be applied until a data matrix is available to process. When the data matrix needs to be obtained from a relational database via a feature extraction query, the computation cost can be prohibitive, as the data matrix may be (much) larger than the total input relation size. This paper introduces Rk-means, or relational k -means algorithm, for clustering relational data tuples without having to access the full data matrix. As such, we avoid having to run the expensive feature extraction query and storing its output. Our algorithm leverages the underlying structures in relational data. It involves construction of a small {\it grid coreset} of the data matrix for subsequent cluster construction. This gives a constant approximation for the k -means objective, while having asymptotic runtime improvements over standard approaches of first running the database query and then clustering. Empirical results show orders-of-magnitude speedup, and Rk-means can run faster on the database than even just computing the data matrix.
On Functional Aggregate Queries with Additive Inequalities
Dec 22, 2018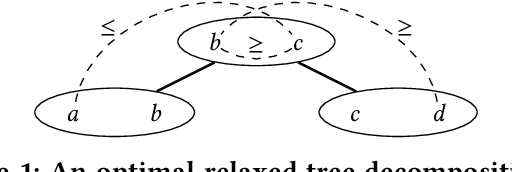
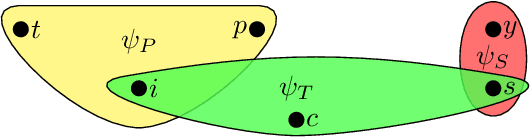
Motivated by fundamental applications in databases and relational machine learning, we formulate and study the problem of answering Functional Aggregate Queries (FAQ) in which some of the input factors are defined by a collection of Additive Inequalities between variables. We refer to these queries as FAQ-AI for short. To answer FAQ-AI in the Boolean semiring, we define "relaxed" tree decompositions and "relaxed" submodular and fractional hypertree width parameters. We show that an extension of the InsideOut algorithm using Chazelle's geometric data structure for solving the semigroup range search problem can answer Boolean FAQ-AI in time given by these new width parameters. This new algorithm achieves lower complexity than known solutions for FAQ-AI. It also recovers some known results in database query answering. Our second contribution is a relaxation of the set of polymatroids that gives rise to the counting version of the submodular width, denoted by "#subw". This new width is sandwiched between the submodular and the fractional hypertree widths. Any FAQ and FAQ-AI over one semiring can be answered in time proportional to #subw and respectively to the relaxed version of #subw. We present three applications of our FAQ-AI framework to relational machine learning: k-means clustering, training linear support vector machines, and training models using non-polynomial loss. These optimization problems can be solved over a database asymptotically faster than computing the join of the database relations.
On Optimality Conditions for Auto-Encoder Signal Recovery
Jul 13, 2017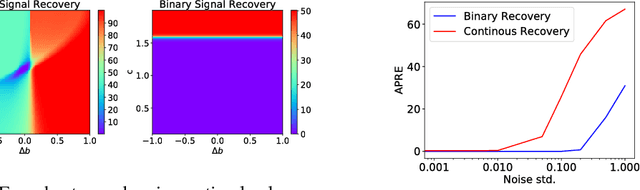
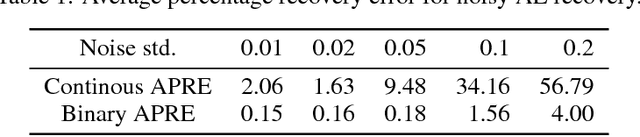
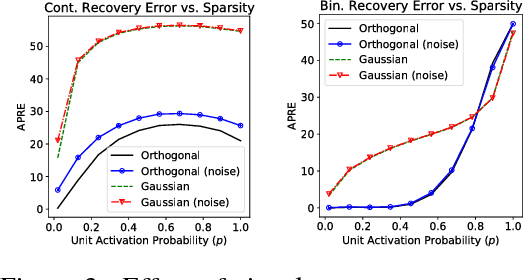
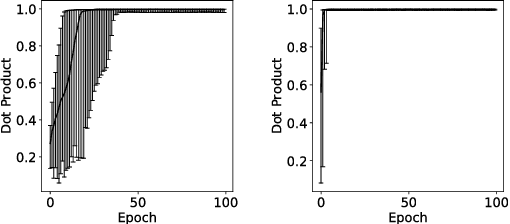
Auto-Encoders are unsupervised models that aim to learn patterns from observed data by minimizing a reconstruction cost. The useful representations learned are often found to be sparse and distributed. On the other hand, compressed sensing and sparse coding assume a data generating process, where the observed data is generated from some true latent signal source, and try to recover the corresponding signal from measurements. Looking at auto-encoders from this \textit{signal recovery perspective} enables us to have a more coherent view of these techniques. In this paper, in particular, we show that the \textit{true} hidden representation can be approximately recovered if the weight matrices are highly incoherent with unit $ \ell^{2} $ row length and the bias vectors takes the value (approximately) equal to the negative of the data mean. The recovery also becomes more and more accurate as the sparsity in hidden signals increases. Additionally, we empirically demonstrate that auto-encoders are capable of recovering the data generating dictionary when only data samples are given.