 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInducer-tuning: Connecting Prefix-tuning and Adapter-tuning
Oct 26, 2022



Prefix-tuning, or more generally continuous prompt tuning, has become an essential paradigm of parameter-efficient transfer learning. Using a large pre-trained language model (PLM), prefix-tuning can obtain strong performance by training only a small portion of parameters. In this paper, we propose to understand and further develop prefix-tuning through the kernel lens. Specifically, we make an analogy between \textit{prefixes} and \textit{inducing variables} in kernel methods and hypothesize that \textit{prefixes} serving as \textit{inducing variables} would improve their overall mechanism. From the kernel estimator perspective, we suggest a new variant of prefix-tuning -- \textit{inducer-tuning}, which shares the exact mechanism as prefix-tuning while leveraging the residual form found in adapter-tuning. This mitigates the initialization issue in prefix-tuning. Through comprehensive empirical experiments on natural language understanding and generation tasks, we demonstrate that inducer-tuning can close the performance gap between prefix-tuning and fine-tuning.
Analyzing Modality Robustness in Multimodal Sentiment Analysis
May 30, 2022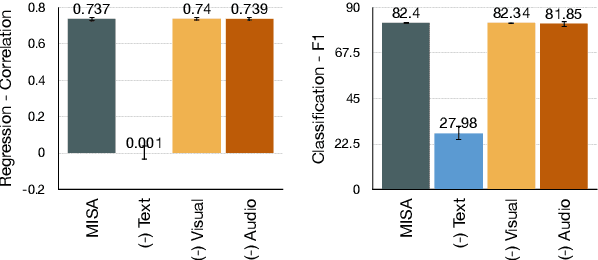
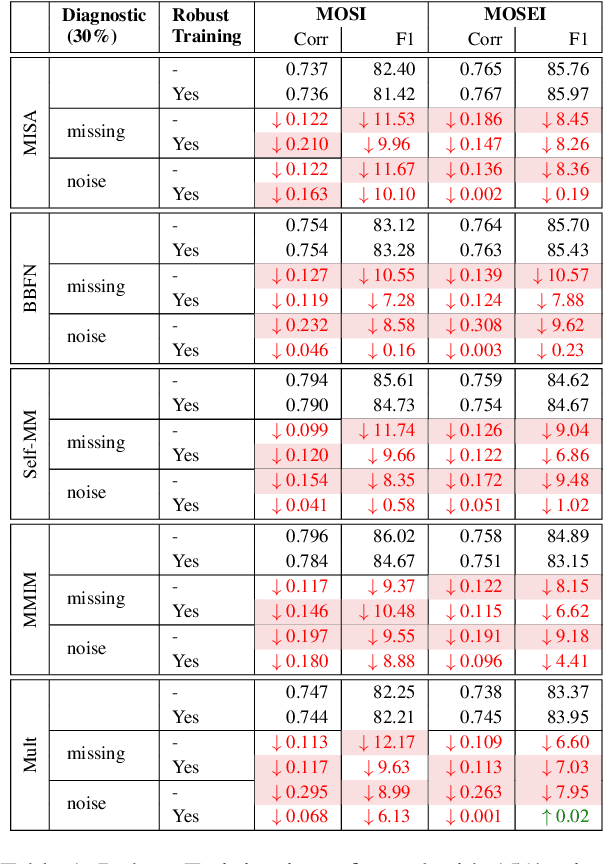
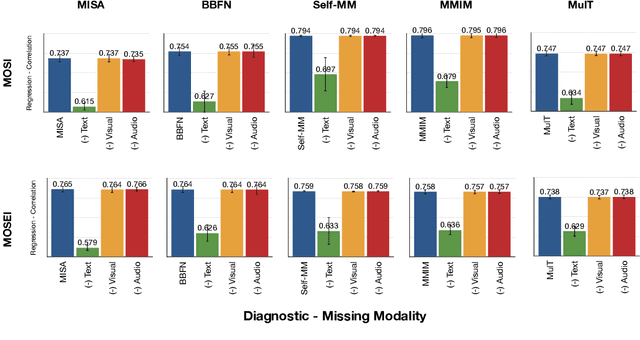
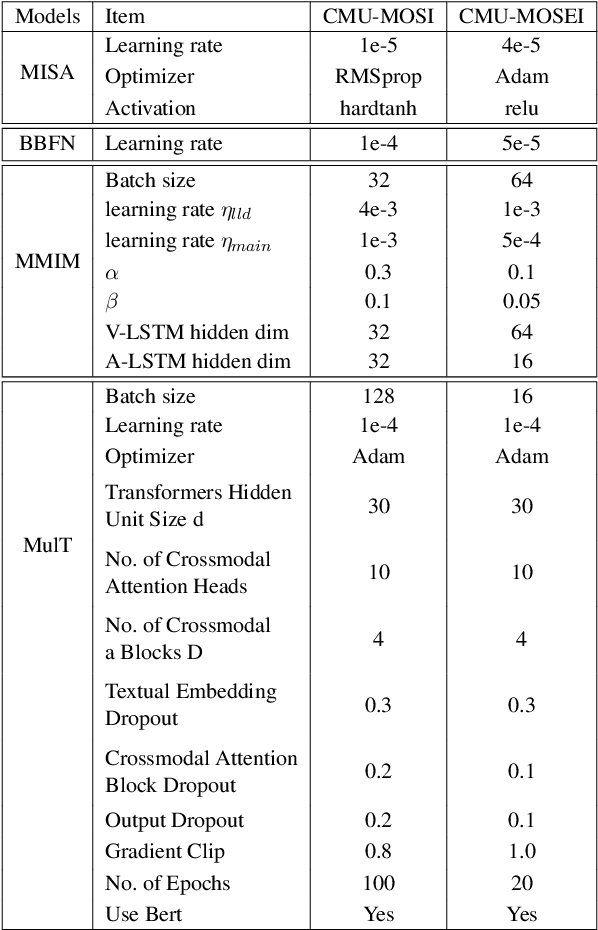
Building robust multimodal models are crucial for achieving reliable deployment in the wild. Despite its importance, less attention has been paid to identifying and improving the robustness of Multimodal Sentiment Analysis (MSA) models. In this work, we hope to address that by (i) Proposing simple diagnostic checks for modality robustness in a trained multimodal model. Using these checks, we find MSA models to be highly sensitive to a single modality, which creates issues in their robustness; (ii) We analyze well-known robust training strategies to alleviate the issues. Critically, we observe that robustness can be achieved without compromising on the original performance. We hope our extensive study-performed across five models and two benchmark datasets-and proposed procedures would make robustness an integral component in MSA research. Our diagnostic checks and robust training solutions are simple to implement and available at https://github. com/declare-lab/MSA-Robustness.
So Different Yet So Alike! Constrained Unsupervised Text Style Transfer
May 09, 2022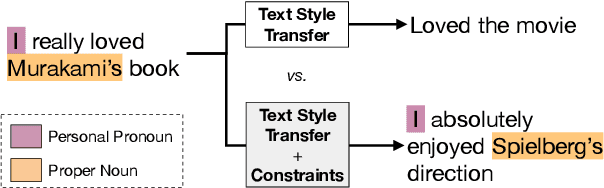
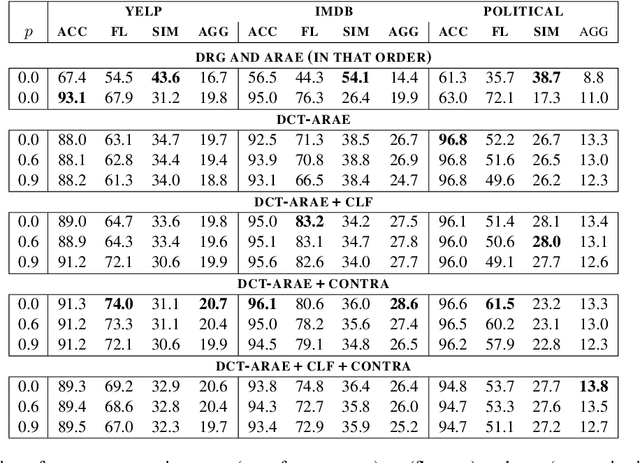
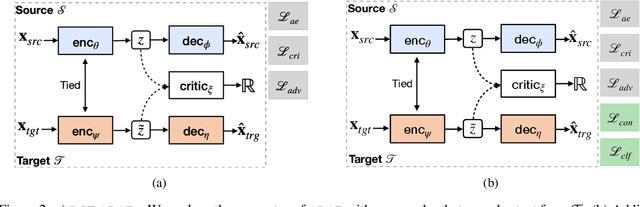
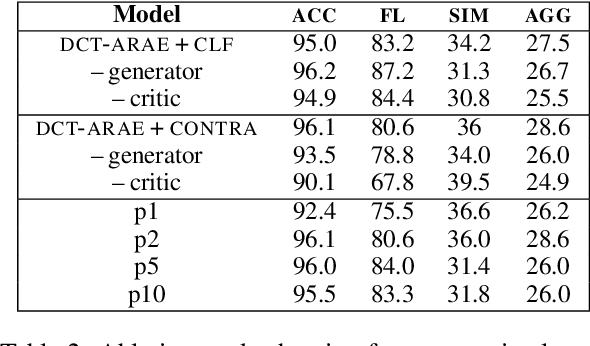
Automatic transfer of text between domains has become popular in recent times. One of its aims is to preserve the semantic content of text being translated from source to target domain. However, it does not explicitly maintain other attributes between the source and translated text, for e.g., text length and descriptiveness. Maintaining constraints in transfer has several downstream applications, including data augmentation and de-biasing. We introduce a method for such constrained unsupervised text style transfer by introducing two complementary losses to the generative adversarial network (GAN) family of models. Unlike the competing losses used in GANs, we introduce cooperative losses where the discriminator and the generator cooperate and reduce the same loss. The first is a contrastive loss and the second is a classification loss, aiming to regularize the latent space further and bring similar sentences across domains closer together. We demonstrate that such training retains lexical, syntactic, and domain-specific constraints between domains for multiple benchmark datasets, including ones where more than one attribute change. We show that the complementary cooperative losses improve text quality, according to both automated and human evaluation measures.
Empowering parameter-efficient transfer learning by recognizing the kernel structure in self-attention
May 07, 2022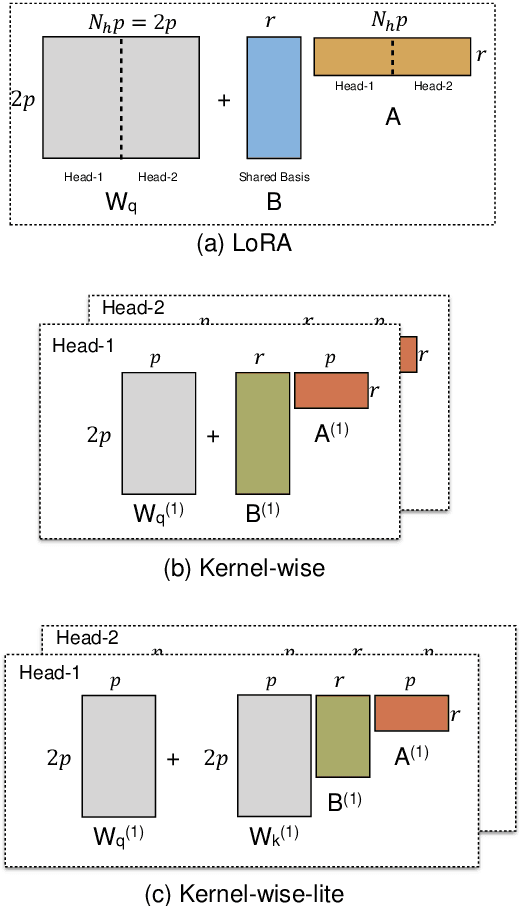
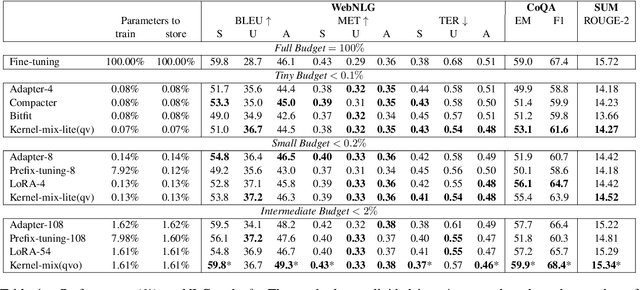
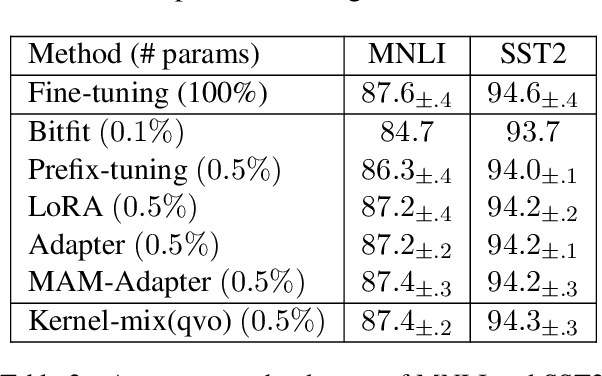
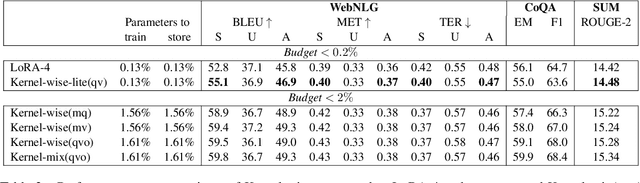
The massive amount of trainable parameters in the pre-trained language models (PLMs) makes them hard to be deployed to multiple downstream tasks. To address this issue, parameter-efficient transfer learning methods have been proposed to tune only a few parameters during fine-tuning while freezing the rest. This paper looks at existing methods along this line through the \textit{kernel lens}. Motivated by the connection between self-attention in transformer-based PLMs and kernel learning, we propose \textit{kernel-wise adapters}, namely \textit{Kernel-mix}, that utilize the kernel structure in self-attention to guide the assignment of the tunable parameters. These adapters use guidelines found in classical kernel learning and enable separate parameter tuning for each attention head. Our empirical results, over a diverse set of natural language generation and understanding tasks, show that our proposed adapters can attain or improve the strong performance of existing baselines.
Exemplars-guided Empathetic Response Generation Controlled by the Elements of Human Communication
Jun 22, 2021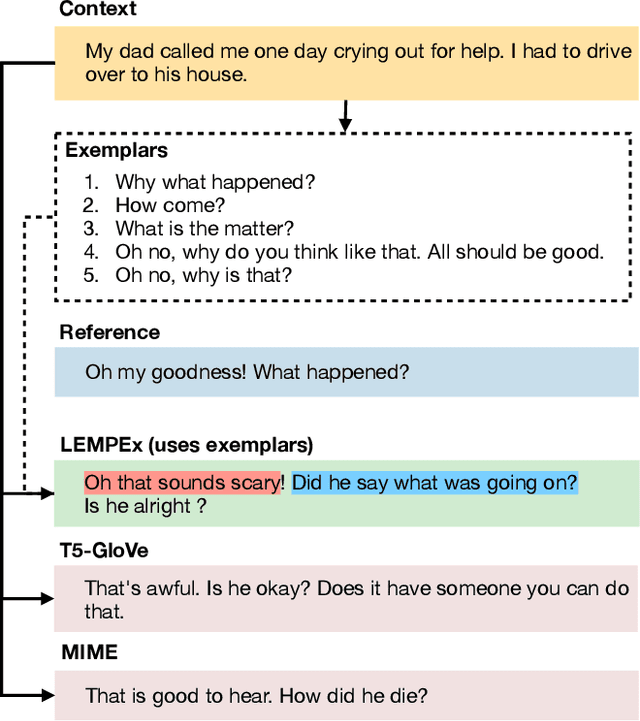
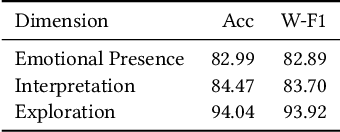
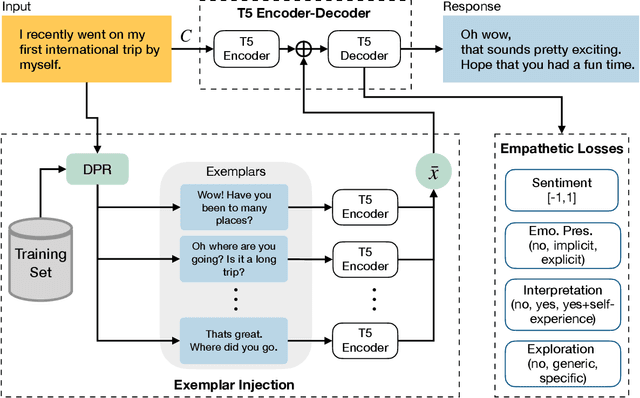
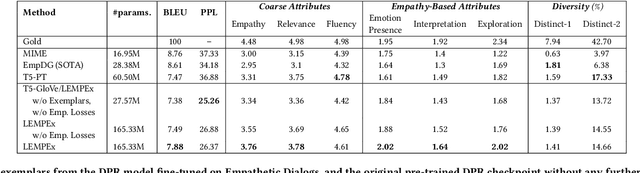
The majority of existing methods for empathetic response generation rely on the emotion of the context to generate empathetic responses. However, empathy is much more than generating responses with an appropriate emotion. It also often entails subtle expressions of understanding and personal resonance with the situation of the other interlocutor. Unfortunately, such qualities are difficult to quantify and the datasets lack the relevant annotations. To address this issue, in this paper we propose an approach that relies on exemplars to cue the generative model on fine stylistic properties that signal empathy to the interlocutor. To this end, we employ dense passage retrieval to extract relevant exemplary responses from the training set. Three elements of human communication -- emotional presence, interpretation, and exploration, and sentiment are additionally introduced using synthetic labels to guide the generation towards empathy. The human evaluation is also extended by these elements of human communication. We empirically show that these approaches yield significant improvements in empathetic response quality in terms of both automated and human-evaluated metrics. The implementation is available at https://github.com/declare-lab/exemplary-empathy.
Zero-Shot Controlled Generation with Encoder-Decoder Transformers
Jun 15, 2021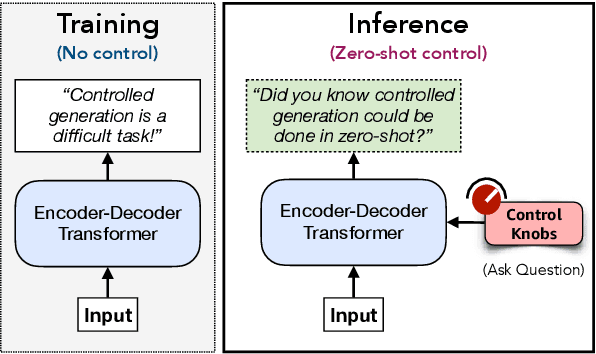

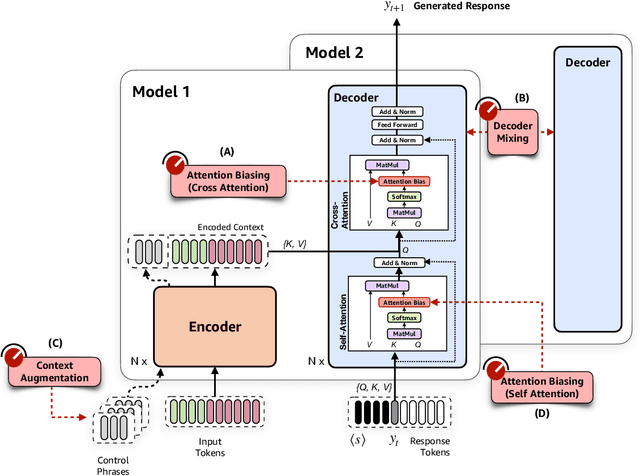

Controlling neural network-based models for natural language generation (NLG) has broad applications in numerous areas such as machine translation, document summarization, and dialog systems. Approaches that enable such control in a zero-shot manner would be of great importance as, among other reasons, they remove the need for additional annotated data and training. In this work, we propose novel approaches for controlling encoder-decoder transformer-based NLG models in zero-shot. This is done by introducing three control knobs, namely, attention biasing, decoder mixing, and context augmentation, that are applied to these models at generation time. These knobs control the generation process by directly manipulating trained NLG models (e.g., biasing cross-attention layers) to realize the desired attributes in the generated outputs. We show that not only are these NLG models robust to such manipulations, but also their behavior could be controlled without an impact on their generation performance. These results, to the best of our knowledge, are the first of their kind. Through these control knobs, we also investigate the role of transformer decoder's self-attention module and show strong evidence that its primary role is maintaining fluency of sentences generated by these models. Based on this hypothesis, we show that alternative architectures for transformer decoders could be viable options. We also study how this hypothesis could lead to more efficient ways for training encoder-decoder transformer models.
Recognizing Emotion Cause in Conversations
Dec 24, 2020
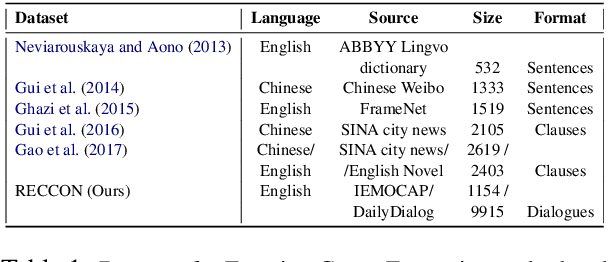
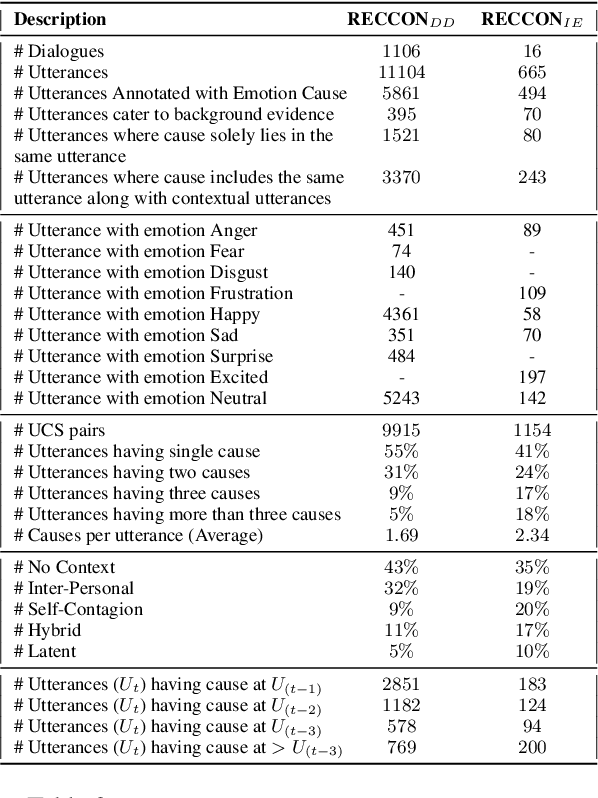

Recognizing the cause behind emotions in text is a fundamental yet under-explored area of research in NLP. Advances in this area hold the potential to improve interpretability and performance in affect-based models. Identifying emotion causes at the utterance level in conversations is particularly challenging due to the intermingling dynamic among the interlocutors. To this end, we introduce the task of recognizing emotion cause in conversations with an accompanying dataset named RECCON. Furthermore, we define different cause types based on the source of the causes and establish strong transformer-based baselines to address two different sub-tasks of RECCON: 1) Causal Span Extraction and 2) Causal Emotion Entailment. The dataset is available at https://github.com/declare-lab/RECCON.
Domain Divergences: a Survey and Empirical Analysis
Oct 23, 2020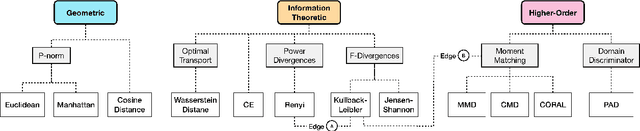
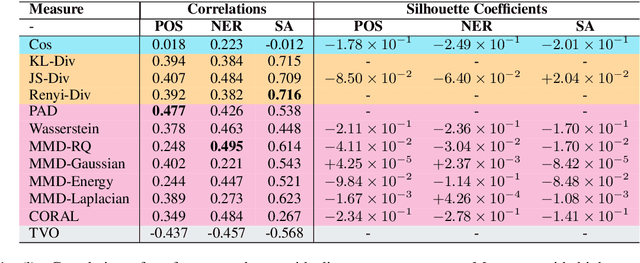

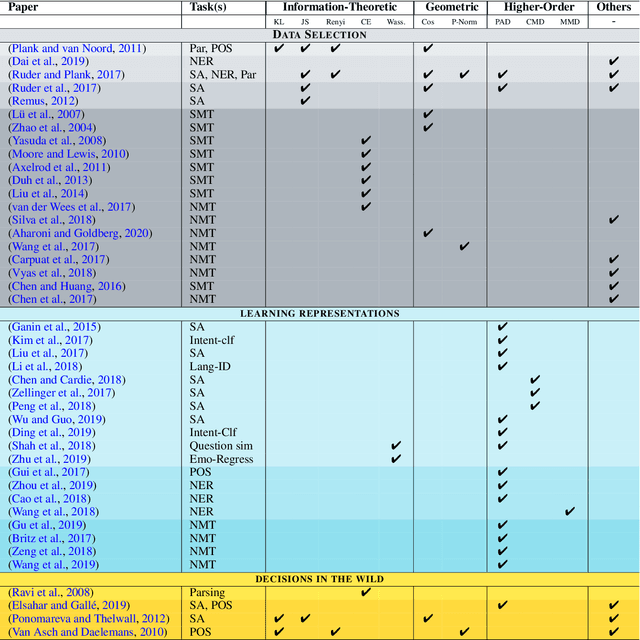
Domain divergence plays a significant role in estimating the performance of a model when applied to new domains. While there is significant literature on divergence measures, choosing an appropriate divergence measures remains difficult for researchers. We address this shortcoming by both surveying the literature and through an empirical study. We contribute a taxonomy of divergence measures consisting of three groups -- Information-theoretic, Geometric, and Higher-order measures -- and identify the relationships between them. We then ground the use of divergence measures in three different application groups -- 1) Data Selection, 2) Learning Representation, and 3) Decisions in the Wild. From this, we identify that Information-theoretic measures are prevalent for 1) and 3), and higher-order measures are common for 2). To further help researchers, we validate these uses empirically through a correlation analysis of performance drops. We consider the current contextual word representations (CWR) to contrast with the older word distribution based representations for this analysis. We find that traditional measures over word distributions still serve as strong baselines, while higher-order measures with CWR are effective.
Emerging Trends of Multimodal Research in Vision and Language
Oct 19, 2020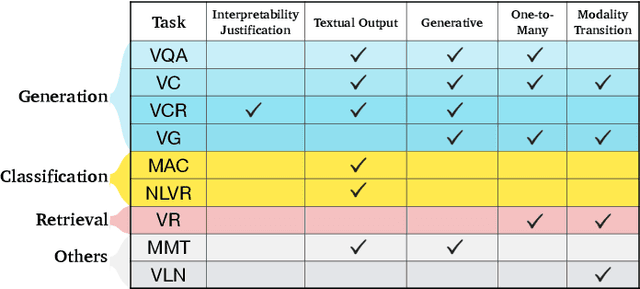
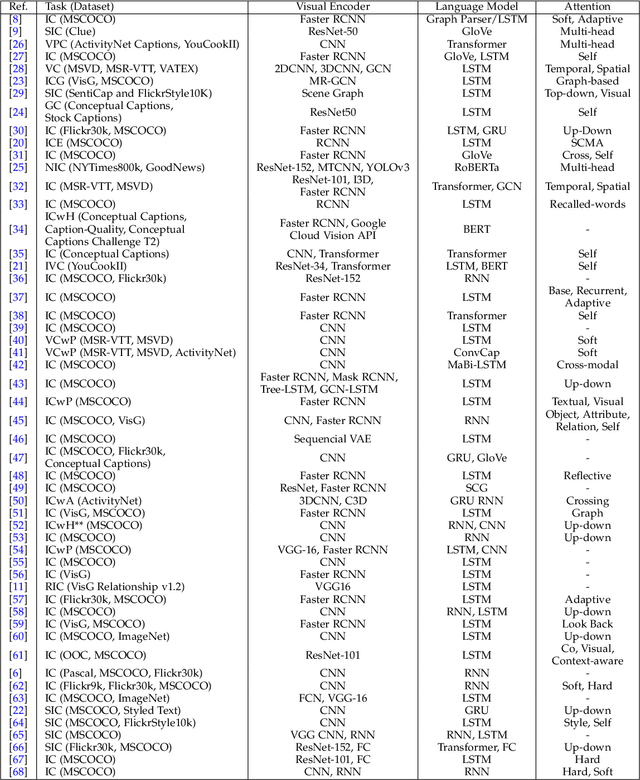
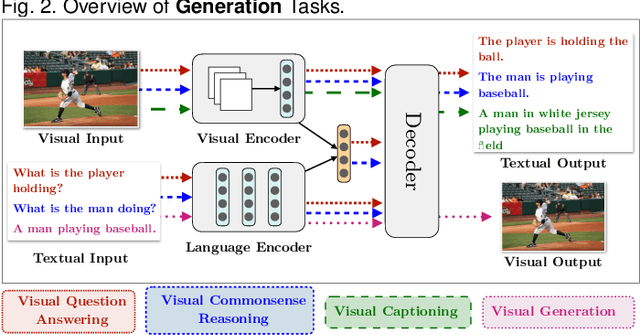
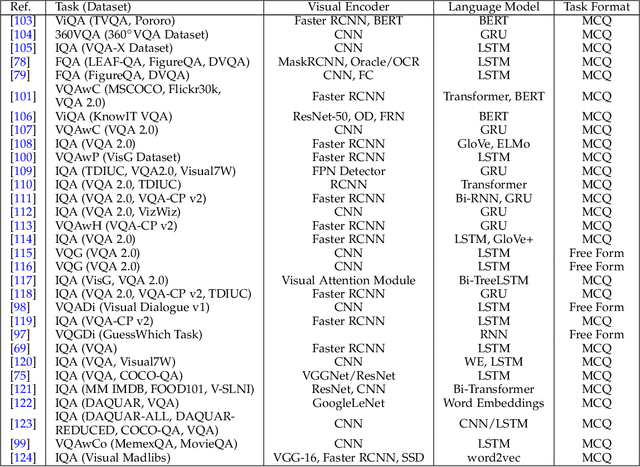
Deep Learning and its applications have cascaded impactful research and development with a diverse range of modalities present in the real-world data. More recently, this has enhanced research interests in the intersection of the Vision and Language arena with its numerous applications and fast-paced growth. In this paper, we present a detailed overview of the latest trends in research pertaining to visual and language modalities. We look at its applications in their task formulations and how to solve various problems related to semantic perception and content generation. We also address task-specific trends, along with their evaluation strategies and upcoming challenges. Moreover, we shed some light on multi-disciplinary patterns and insights that have emerged in the recent past, directing this field towards more modular and transparent intelligent systems. This survey identifies key trends gravitating recent literature in VisLang research and attempts to unearth directions that the field is heading towards.
KinGDOM: Knowledge-Guided DOMain adaptation for sentiment analysis
May 11, 2020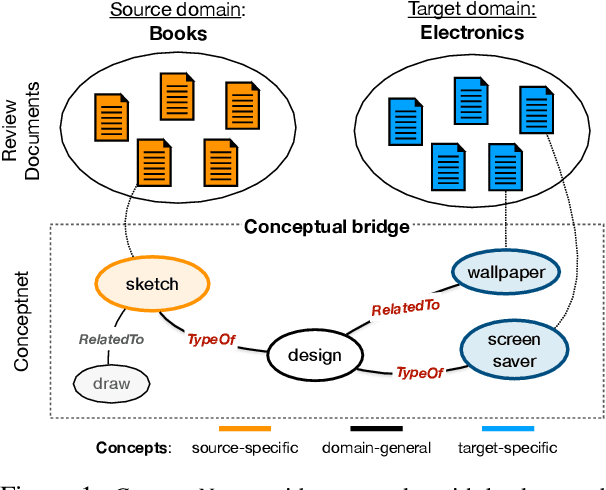
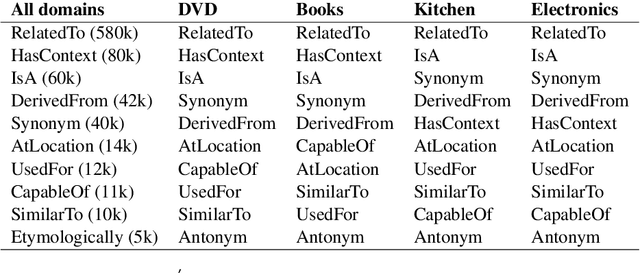
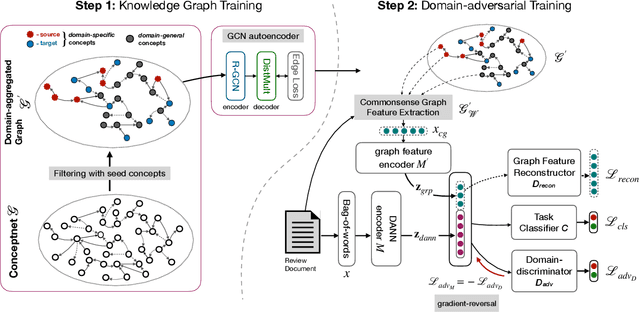
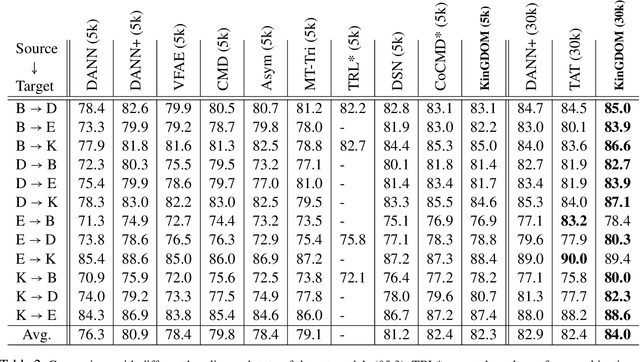
Cross-domain sentiment analysis has received significant attention in recent years, prompted by the need to combat the domain gap between different applications that make use of sentiment analysis. In this paper, we take a novel perspective on this task by exploring the role of external commonsense knowledge. We introduce a new framework, KinGDOM, which utilizes the ConceptNet knowledge graph to enrich the semantics of a document by providing both domain-specific and domain-general background concepts. These concepts are learned by training a graph convolutional autoencoder that leverages inter-domain concepts in a domain-invariant manner. Conditioning a popular domain-adversarial baseline method with these learned concepts helps improve its performance over state-of-the-art approaches, demonstrating the efficacy of our proposed framework.