 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreatment Effect Estimation using Invariant Risk Minimization
Mar 13, 2021
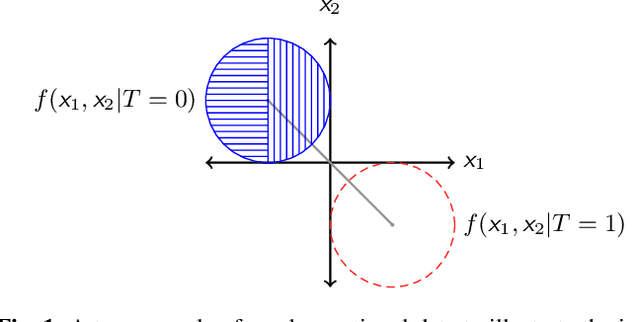
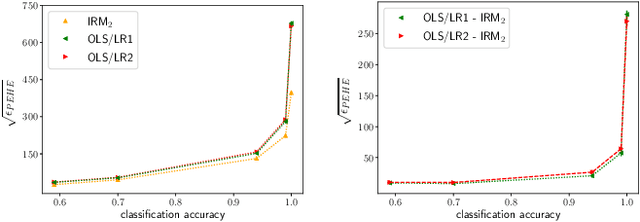
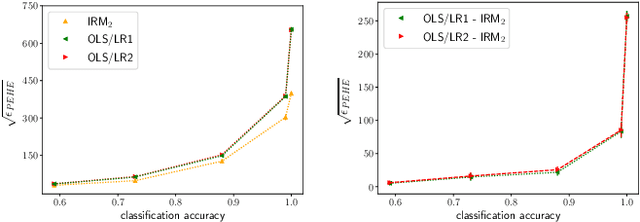
Inferring causal individual treatment effect (ITE) from observational data is a challenging problem whose difficulty is exacerbated by the presence of treatment assignment bias. In this work, we propose a new way to estimate the ITE using the domain generalization framework of invariant risk minimization (IRM). IRM uses data from multiple domains, learns predictors that do not exploit spurious domain-dependent factors, and generalizes better to unseen domains. We propose an IRM-based ITE estimator aimed at tackling treatment assignment bias when there is little support overlap between the control group and the treatment group. We accomplish this by creating diversity: given a single dataset, we split the data into multiple domains artificially. These diverse domains are then exploited by IRM to more effectively generalize regression-based models to data regions that lack support overlap. We show gains over classical regression approaches to ITE estimation in settings when support mismatch is more pronounced.
Optimal Policies for the Homogeneous Selective Labels Problem
Nov 02, 2020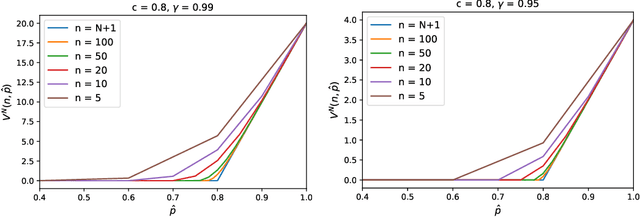
Selective labels are a common feature of consequential decision-making applications, referring to the lack of observed outcomes under one of the possible decisions. This paper reports work in progress on learning decision policies in the face of selective labels. The setting considered is both a simplified homogeneous one, disregarding individuals' features to facilitate determination of optimal policies, and an online one, to balance costs incurred in learning with future utility. For maximizing discounted total reward, the optimal policy is shown to be a threshold policy, and the problem is one of optimal stopping. In contrast, for undiscounted infinite-horizon average reward, optimal policies have positive acceptance probability in all states. Future work stemming from these results is discussed.
DAGs with No Fears: A Closer Look at Continuous Optimization for Learning Bayesian Networks
Oct 18, 2020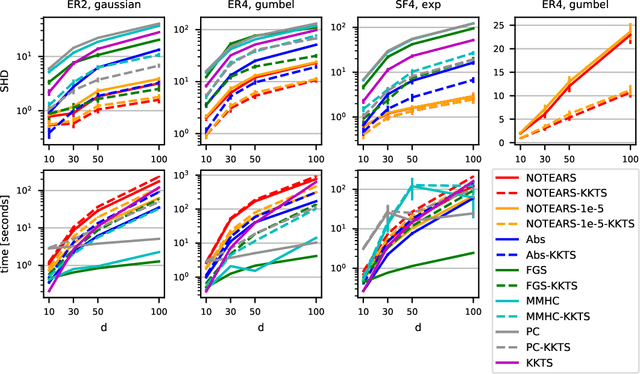
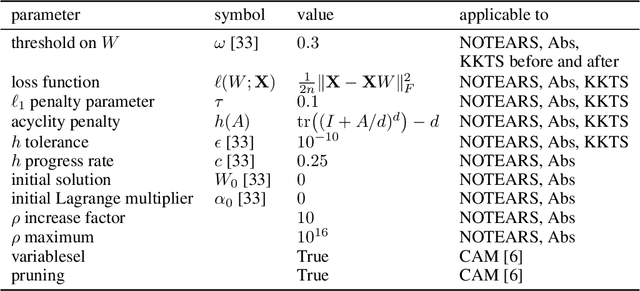
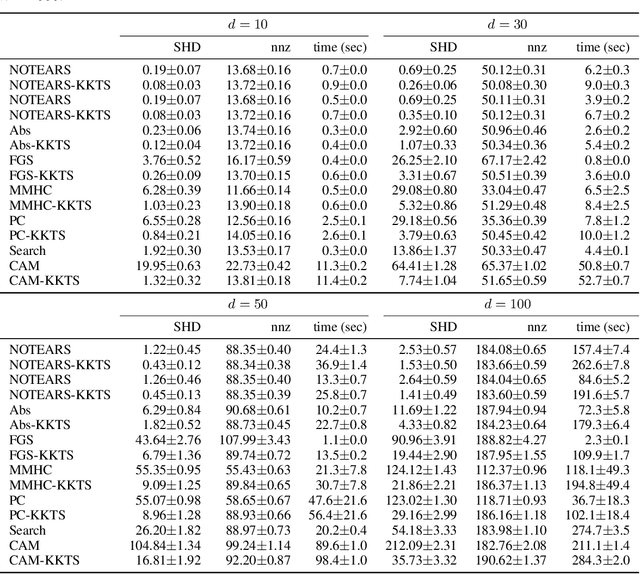
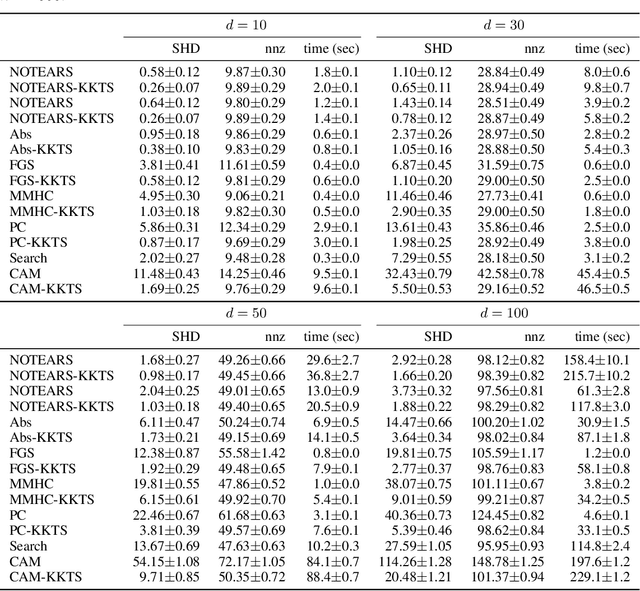
This paper re-examines a continuous optimization framework dubbed NOTEARS for learning Bayesian networks. We first generalize existing algebraic characterizations of acyclicity to a class of matrix polynomials. Next, focusing on a one-parameter-per-edge setting, it is shown that the Karush-Kuhn-Tucker (KKT) optimality conditions for the NOTEARS formulation cannot be satisfied except in a trivial case, which explains a behavior of the associated algorithm. We then derive the KKT conditions for an equivalent reformulation, show that they are indeed necessary, and relate them to explicit constraints that certain edges be absent from the graph. If the score function is convex, these KKT conditions are also sufficient for local minimality despite the non-convexity of the constraint. Informed by the KKT conditions, a local search post-processing algorithm is proposed and shown to substantially and universally improve the structural Hamming distance of all tested algorithms, typically by a factor of 2 or more. Some combinations with local search are both more accurate and more efficient than the original NOTEARS.
Deciding Fast and Slow: The Role of Cognitive Biases in AI-assisted Decision-making
Oct 15, 2020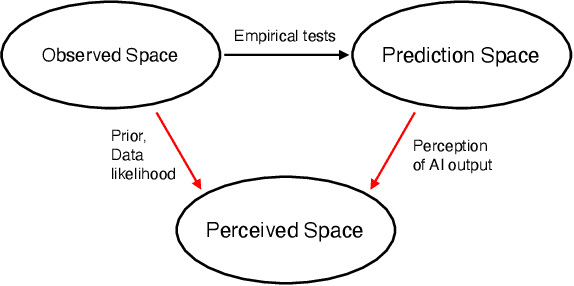
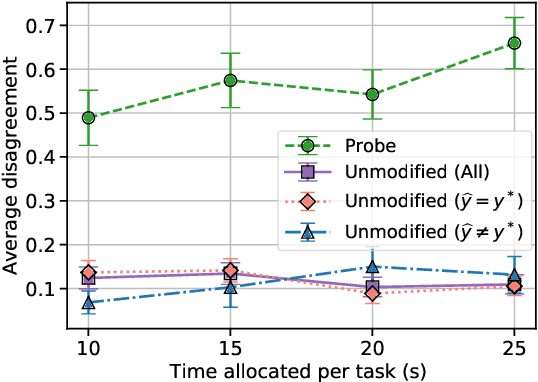
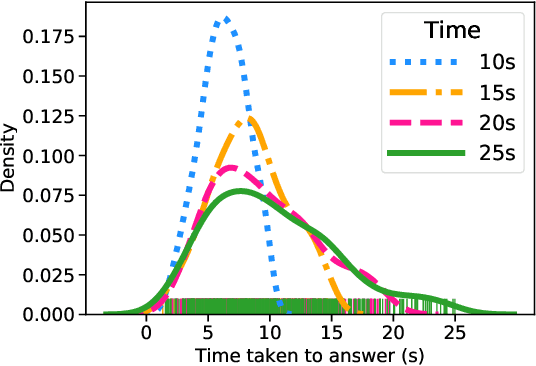
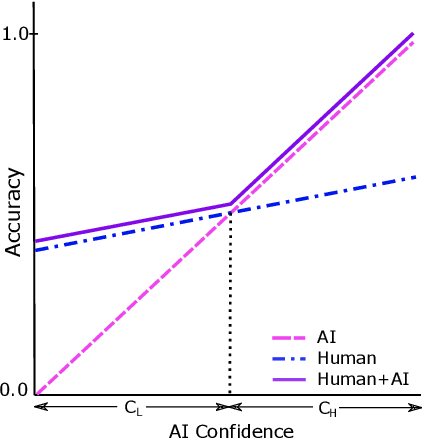
Several strands of research have aimed to bridge the gap between artificial intelligence (AI) and human decision-makers in AI-assisted decision-making, where humans are the consumers of AI model predictions and the ultimate decision-makers in high-stakes applications. However, people's perception and understanding is often distorted by their cognitive biases, like confirmation bias, anchoring bias, availability bias, to name a few. In this work, we use knowledge from the field of cognitive science to account for cognitive biases in the human-AI collaborative decision-making system and mitigate their negative effects. To this end, we mathematically model cognitive biases and provide a general framework through which researchers and practitioners can understand the interplay between cognitive biases and human-AI accuracy. We then focus on anchoring bias, a bias commonly witnessed in human-AI partnerships. We devise a cognitive science-driven, time-based approach to de-anchoring. A user experiment shows the effectiveness of this approach in human-AI collaborative decision-making. Using the results from this first experiment, we design a time allocation strategy for a resource constrained setting so as to achieve optimal human-AI collaboration under some assumptions. A second user study shows that our time allocation strategy can effectively debias the human when the AI model has low confidence and is incorrect.
Consumer-Driven Explanations for Machine Learning Decisions: An Empirical Study of Robustness
Jan 13, 2020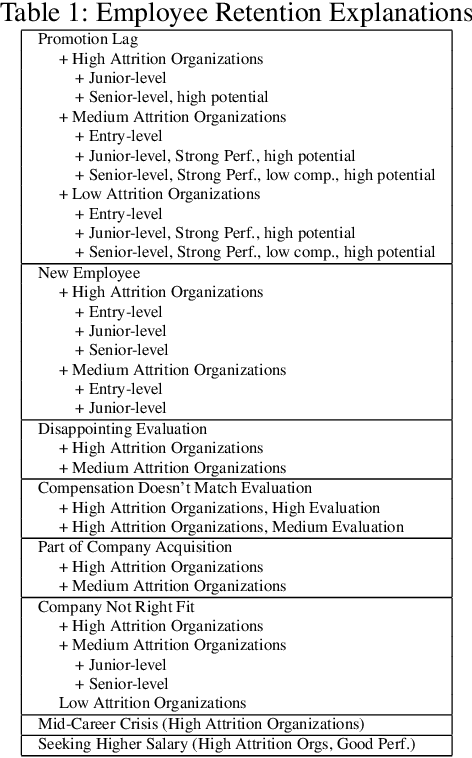

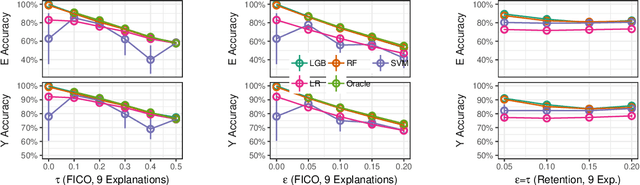

Many proposed methods for explaining machine learning predictions are in fact challenging to understand for nontechnical consumers. This paper builds upon an alternative consumer-driven approach called TED that asks for explanations to be provided in training data, along with target labels. Using semi-synthetic data from credit approval and employee retention applications, experiments are conducted to investigate some practical considerations with TED, including its performance with different classification algorithms, varying numbers of explanations, and variability in explanations. A new algorithm is proposed to handle the case where some training examples do not have explanations. Our results show that TED is robust to increasing numbers of explanations, noisy explanations, and large fractions of missing explanations, thus making advances toward its practical deployment.
An Information-Theoretic Perspective on the Relationship Between Fairness and Accuracy
Oct 17, 2019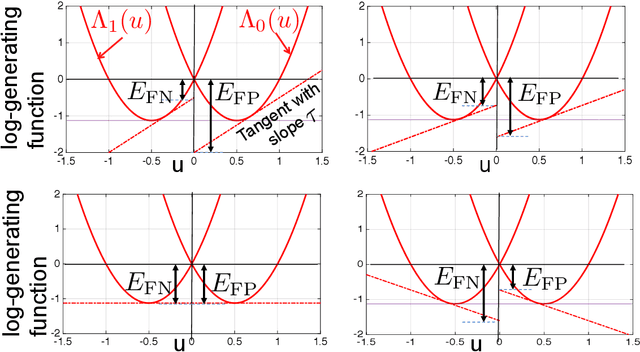
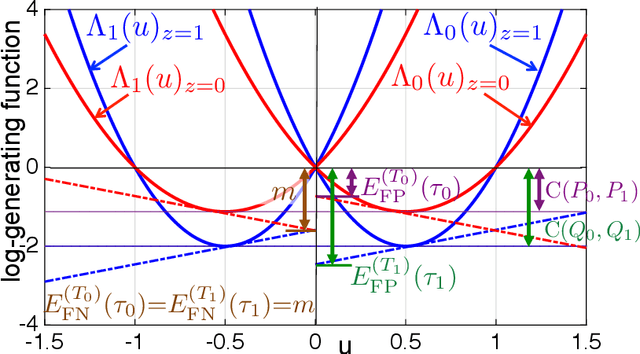
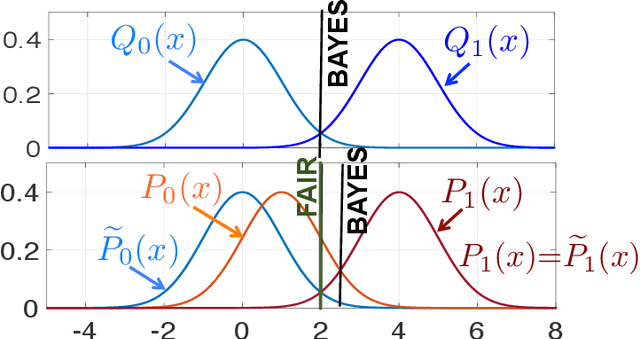
Our goal is to understand the so-called trade-off between fairness and accuracy. In this work, using a tool from information theory called Chernoff information, we derive fundamental limits on this relationship that explain why the accuracy on a given dataset often decreases as fairness increases. Novel to this work, we examine the problem of fair classification through the lens of a mismatched hypothesis testing problem, i.e., where we are trying to find a classifier that distinguishes between two "ideal" distributions but instead we are given two mismatched distributions that are biased. Based on this perspective, we contend that measuring accuracy with respect to the given (possibly biased) dataset is a problematic measure of performance. Instead one should also consider accuracy with respect to an ideal dataset that is unbiased. We formulate an optimization to find such ideal distributions and show that the optimization is feasible. Lastly, when the Chernoff information for one group is strictly less than another in the given dataset, we derive the information-theoretic criterion under which collection of more features can actually improve the Chernoff information and achieve fairness without compromising accuracy on the available data.
One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques
Sep 14, 2019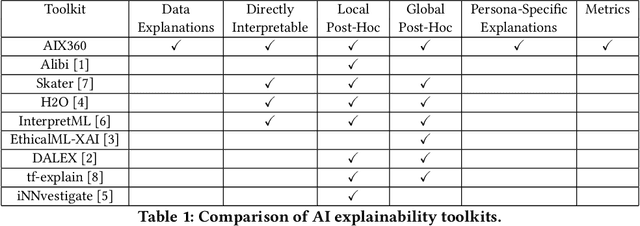
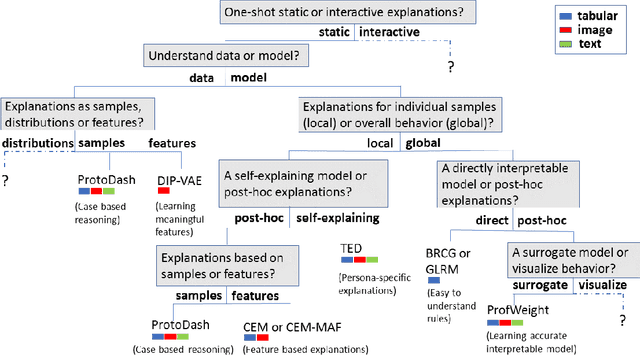
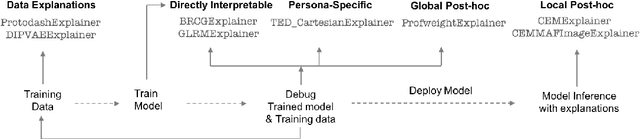
As artificial intelligence and machine learning algorithms make further inroads into society, calls are increasing from multiple stakeholders for these algorithms to explain their outputs. At the same time, these stakeholders, whether they be affected citizens, government regulators, domain experts, or system developers, present different requirements for explanations. Toward addressing these needs, we introduce AI Explainability 360 (http://aix360.mybluemix.net/), an open-source software toolkit featuring eight diverse and state-of-the-art explainability methods and two evaluation metrics. Equally important, we provide a taxonomy to help entities requiring explanations to navigate the space of explanation methods, not only those in the toolkit but also in the broader literature on explainability. For data scientists and other users of the toolkit, we have implemented an extensible software architecture that organizes methods according to their place in the AI modeling pipeline. We also discuss enhancements to bring research innovations closer to consumers of explanations, ranging from simplified, more accessible versions of algorithms, to tutorials and an interactive web demo to introduce AI explainability to different audiences and application domains. Together, our toolkit and taxonomy can help identify gaps where more explainability methods are needed and provide a platform to incorporate them as they are developed.
Characterization of Overlap in Observational Studies
Jul 09, 2019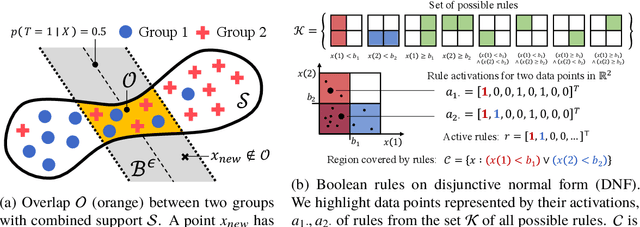
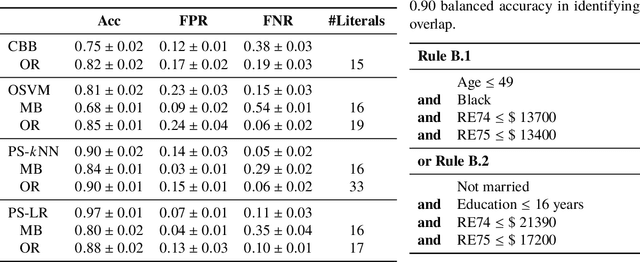
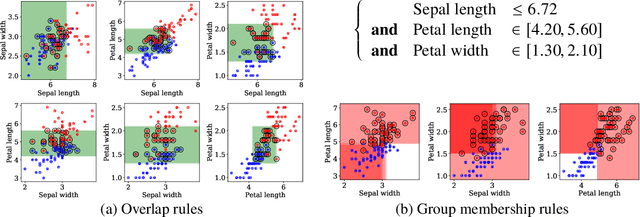

Overlap between treatment groups is required for nonparametric estimation of causal effects. If a subgroup of subjects always receives (or never receives) a given intervention, we cannot estimate the effect of intervention changes on that subgroup without further assumptions. When overlap does not hold globally, characterizing local regions of overlap can inform the relevance of any causal conclusions for new subjects, and can help guide additional data collection. To have impact, these descriptions must be interpretable for downstream users who are not machine learning experts, such as clinicians. We formalize overlap estimation as a problem of finding minimum volume sets and give a method to solve it by reduction to binary classification with Boolean rules. We also generalize our method to estimate overlap in off-policy policy evaluation. Using data from real-world applications, we demonstrate that these rules have comparable accuracy to black-box estimators while maintaining a simple description. In one case study, we perform a user study with clinicians to evaluate rules learned to describe treatment group overlap in post-surgical opioid prescriptions. In another, we estimate overlap in policy evaluation of antibiotic prescription for urinary tract infections.
Teaching AI to Explain its Decisions Using Embeddings and Multi-Task Learning
Jun 05, 2019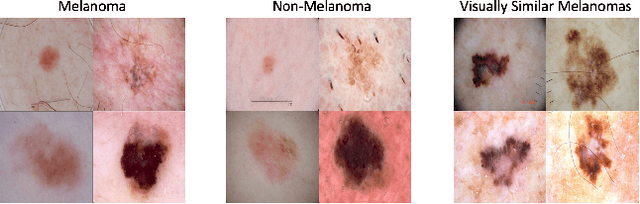
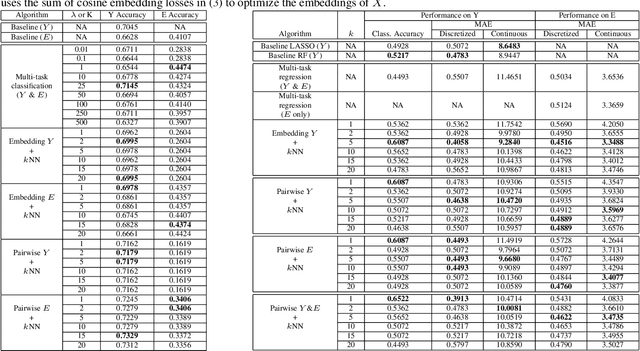
Using machine learning in high-stakes applications often requires predictions to be accompanied by explanations comprehensible to the domain user, who has ultimate responsibility for decisions and outcomes. Recently, a new framework for providing explanations, called TED, has been proposed to provide meaningful explanations for predictions. This framework augments training data to include explanations elicited from domain users, in addition to features and labels. This approach ensures that explanations for predictions are tailored to the complexity expectations and domain knowledge of the consumer. In this paper, we build on this foundational work, by exploring more sophisticated instantiations of the TED framework and empirically evaluate their effectiveness in two diverse domains, chemical odor and skin cancer prediction. Results demonstrate that meaningful explanations can be reliably taught to machine learning algorithms, and in some cases, improving modeling accuracy.
Generalized Linear Rule Models
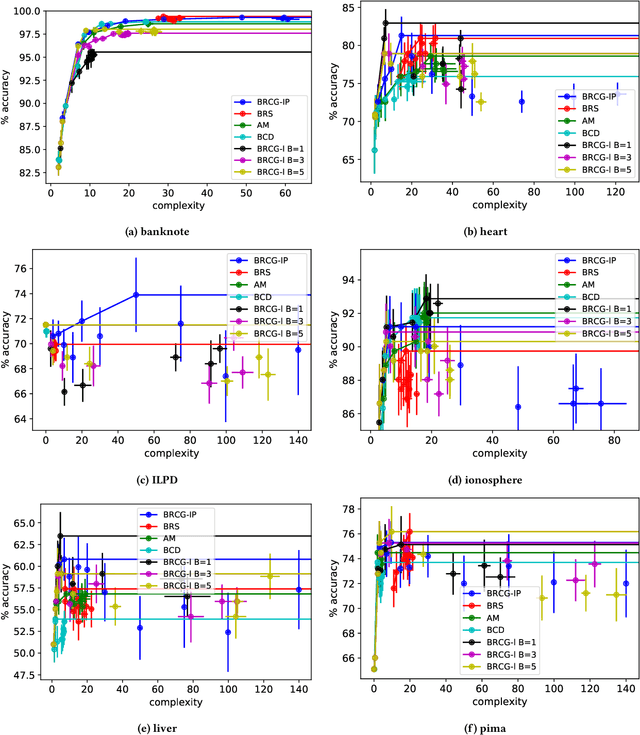
Jun 05, 2019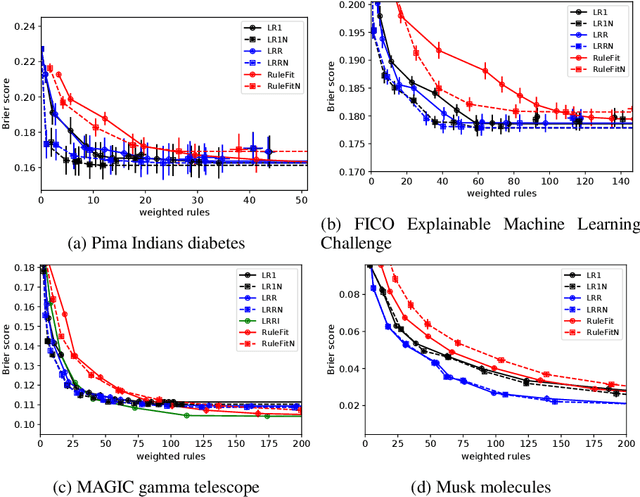
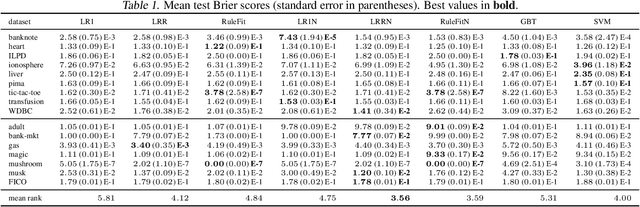
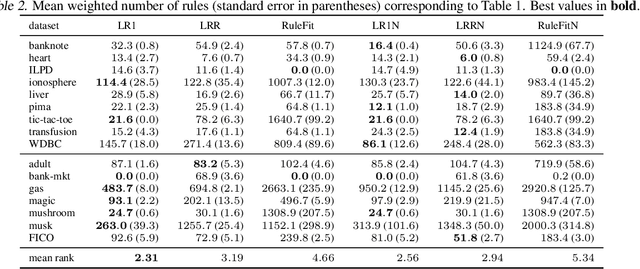
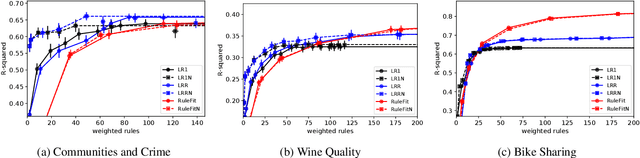
This paper considers generalized linear models using rule-based features, also referred to as rule ensembles, for regression and probabilistic classification. Rules facilitate model interpretation while also capturing nonlinear dependences and interactions. Our problem formulation accordingly trades off rule set complexity and prediction accuracy. Column generation is used to optimize over an exponentially large space of rules without pre-generating a large subset of candidates or greedily boosting rules one by one. The column generation subproblem is solved using either integer programming or a heuristic optimizing the same objective. In experiments involving logistic and linear regression, the proposed methods obtain better accuracy-complexity trade-offs than existing rule ensemble algorithms. At one end of the trade-off, the methods are competitive with less interpretable benchmark models.