 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaLLM: Investigating the Ability of GPT-3.5 to Express Personality Traits and Gender Differences
May 04, 2023



Despite the many use cases for large language models (LLMs) in the design of chatbots in various industries and the research showing the importance of personalizing chatbots to cater to different personality traits, little work has been done to evaluate whether the behaviors of personalized LLMs can reflect certain personality traits accurately and consistently. We consider studying the behavior of LLM-based simulated agents which refer to as LLM personas and present a case study with GPT-3.5 (text-davinci-003) to investigate whether LLMs can generate content with consistent, personalized traits when assigned Big Five personality types and gender roles. We created 320 LLM personas (5 females and 5 males for each of the 32 Big Five personality types) and prompted them to complete the classic 44-item Big Five Inventory (BFI) and then write an 800-word story about their childhood. Results showed that LLM personas' self-reported BFI scores are consistent with their assigned personality types, with large effect sizes found on all five traits. Moreover, significant correlations were found between assigned personality types and some Linguistic Inquiry and Word Count (LIWC) psycholinguistic features of their writings. For instance, extroversion is associated with pro-social and active words, and neuroticism is associated with words related to negative emotions and mental health. Besides, we only found significant differences in using technological and cultural words in writing between LLM-generated female and male personas. This work provides a first step for further research on personalized LLMs and their applications in Human-AI conversation.
Language Models Trained on Media Diets Can Predict Public Opinion
Mar 28, 2023



Public opinion reflects and shapes societal behavior, but the traditional survey-based tools to measure it are limited. We introduce a novel approach to probe media diet models -- language models adapted to online news, TV broadcast, or radio show content -- that can emulate the opinions of subpopulations that have consumed a set of media. To validate this method, we use as ground truth the opinions expressed in U.S. nationally representative surveys on COVID-19 and consumer confidence. Our studies indicate that this approach is (1) predictive of human judgements found in survey response distributions and robust to phrasing and channels of media exposure, (2) more accurate at modeling people who follow media more closely, and (3) aligned with literature on which types of opinions are affected by media consumption. Probing language models provides a powerful new method for investigating media effects, has practical applications in supplementing polls and forecasting public opinion, and suggests a need for further study of the surprising fidelity with which neural language models can predict human responses.
Redrawing attendance boundaries to promote racial and ethnic diversity in elementary schools
Mar 14, 2023Most US school districts draw "attendance boundaries" to define catchment areas that assign students to schools near their homes, often recapitulating neighborhood demographic segregation in schools. Focusing on elementary schools, we ask: how much might we reduce school segregation by redrawing attendance boundaries? Combining parent preference data with methods from combinatorial optimization, we simulate alternative boundaries for 98 US school districts serving over 3 million elementary-aged students, minimizing White/non-White segregation while mitigating changes to travel times and school sizes. Across districts, we observe a median 14% relative decrease in segregation, which we estimate would require approximately 20\% of students to switch schools and, surprisingly, a slight reduction in travel times. We release a public dashboard depicting these alternative boundaries (https://www.schooldiversity.org/) and invite both school boards and their constituents to evaluate their viability. Our results show the possibility of greater integration without significant disruptions for families.
M-SENSE: Modeling Narrative Structure in Short Personal Narratives Using Protagonist's Mental Representations
Feb 18, 2023Narrative is a ubiquitous component of human communication. Understanding its structure plays a critical role in a wide variety of applications, ranging from simple comparative analyses to enhanced narrative retrieval, comprehension, or reasoning capabilities. Prior research in narratology has highlighted the importance of studying the links between cognitive and linguistic aspects of narratives for effective comprehension. This interdependence is related to the textual semantics and mental language in narratives, referring to characters' motivations, feelings or emotions, and beliefs. However, this interdependence is hardly explored for modeling narratives. In this work, we propose the task of automatically detecting prominent elements of the narrative structure by analyzing the role of characters' inferred mental state along with linguistic information at the syntactic and semantic levels. We introduce a STORIES dataset of short personal narratives containing manual annotations of key elements of narrative structure, specifically climax and resolution. To this end, we implement a computational model that leverages the protagonist's mental state information obtained from a pre-trained model trained on social commonsense knowledge and integrates their representations with contextual semantic embed-dings using a multi-feature fusion approach. Evaluating against prior zero-shot and supervised baselines, we find that our model is able to achieve significant improvements in the task of identifying climax and resolution.
CommunityLM: Probing Partisan Worldviews from Language Models
Sep 15, 2022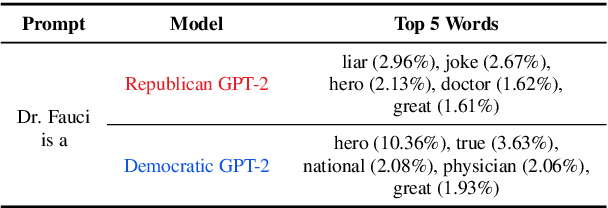
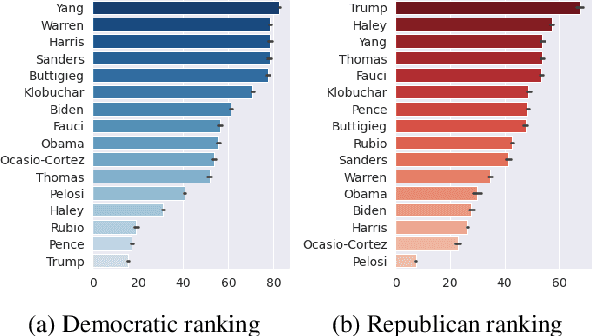
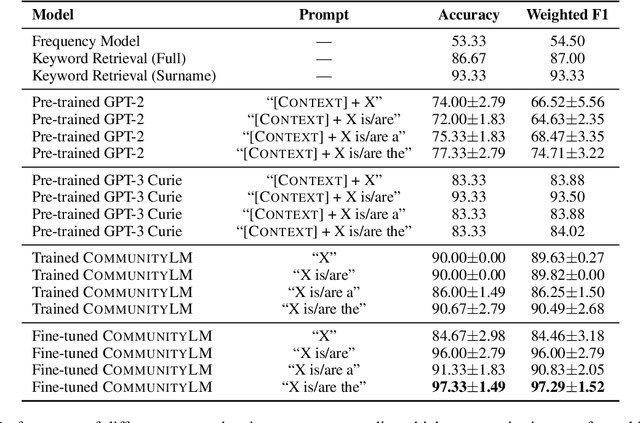
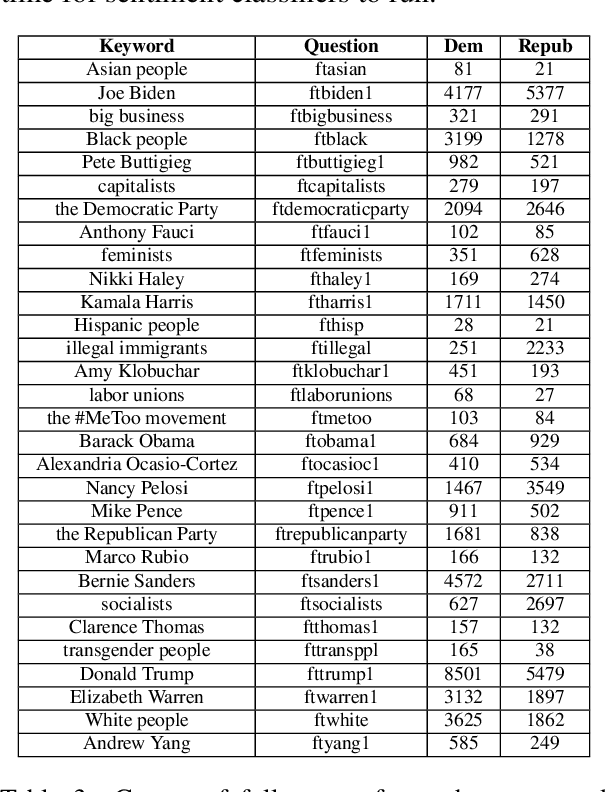
As political attitudes have diverged ideologically in the United States, political speech has diverged lingusitically. The ever-widening polarization between the US political parties is accelerated by an erosion of mutual understanding between them. We aim to make these communities more comprehensible to each other with a framework that probes community-specific responses to the same survey questions using community language models CommunityLM. In our framework we identify committed partisan members for each community on Twitter and fine-tune LMs on the tweets authored by them. We then assess the worldviews of the two groups using prompt-based probing of their corresponding LMs, with prompts that elicit opinions about public figures and groups surveyed by the American National Election Studies (ANES) 2020 Exploratory Testing Survey. We compare the responses generated by the LMs to the ANES survey results, and find a level of alignment that greatly exceeds several baseline methods. Our work aims to show that we can use community LMs to query the worldview of any group of people given a sufficiently large sample of their social media discussions or media diet.
End-to-End Zero-Shot Voice Style Transfer with Location-Variable Convolutions
May 19, 2022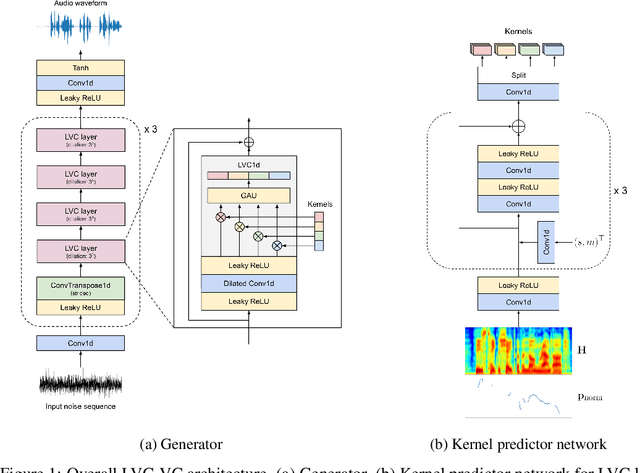
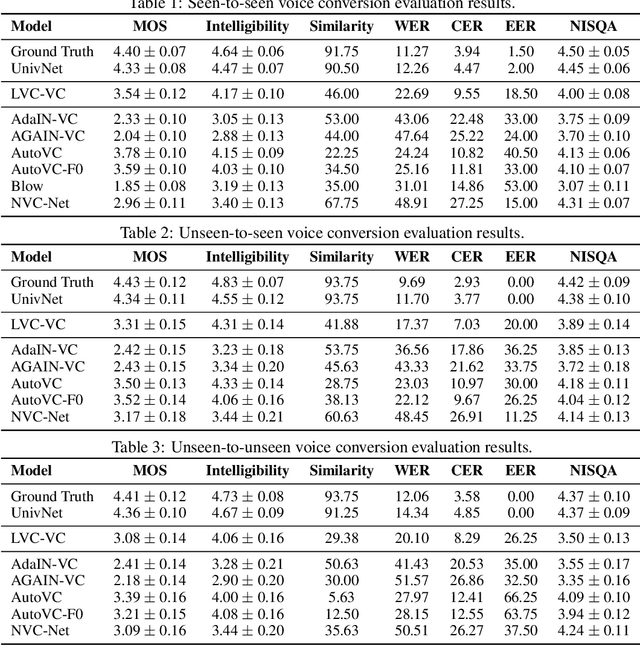

Zero-shot voice conversion is becoming an increasingly popular research direction, as it promises the ability to transform speech to match the voice style of any speaker. However, little work has been done on end-to-end methods for this task, which are appealing because they remove the need for a separate vocoder to generate audio from intermediate features. In this work, we propose Location-Variable Convolution-based Voice Conversion (LVC-VC), a model for performing end-to-end zero-shot voice conversion that is based on a neural vocoder. LVC-VC utilizes carefully designed input features that have disentangled content and speaker style information, and the vocoder-like architecture learns to combine them to simultaneously perform voice conversion while synthesizing audio. To the best of our knowledge, LVC-VC is one of the first models to be proposed that can perform zero-shot voice conversion in an end-to-end manner, and it is the first to do so using a vocoder-like neural framework. Experiments show that our model achieves competitive or better voice style transfer performance compared to several baselines while maintaining the intelligibility of transformed speech much better.
Annotating the Tweebank Corpus on Named Entity Recognition and Building NLP Models for Social Media Analysis
Jan 18, 2022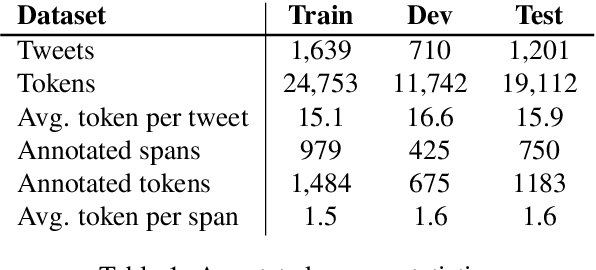
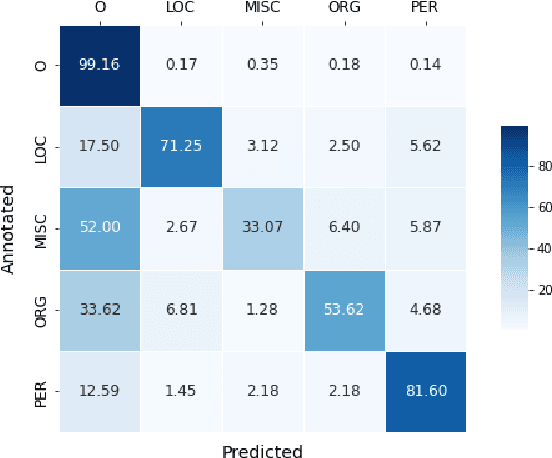
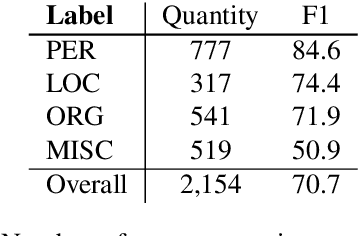

Social media data such as Twitter messages ("tweets") pose a particular challenge to NLP systems because of their short, noisy, and colloquial nature. Tasks such as Named Entity Recognition (NER) and syntactic parsing require highly domain-matched training data for good performance. While there are some publicly available annotated datasets of tweets, they are all purpose-built for solving one task at a time. As yet there is no complete training corpus for both syntactic analysis (e.g., part of speech tagging, dependency parsing) and NER of tweets. In this study, we aim to create Tweebank-NER, an NER corpus based on Tweebank V2 (TB2), and we use these datasets to train state-of-the-art NLP models. We first annotate named entities in TB2 using Amazon Mechanical Turk and measure the quality of our annotations. We train a Stanza NER model on the new benchmark, achieving competitive performance against other non-transformer NER systems. Finally, we train other Twitter NLP models (a tokenizer, lemmatizer, part of speech tagger, and dependency parser) on TB2 based on Stanza, and achieve state-of-the-art or competitive performance on these tasks. We release the dataset and make the models available to use in an "off-the-shelf" manner for future Tweet NLP research. Our source code, data, and pre-trained models are available at: \url{https://github.com/social-machines/TweebankNLP}.
Topic Detection and Tracking with Time-Aware Document Embeddings
Dec 12, 2021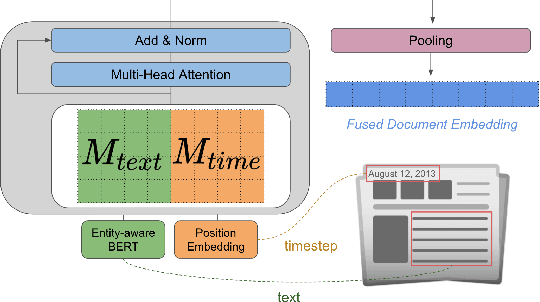

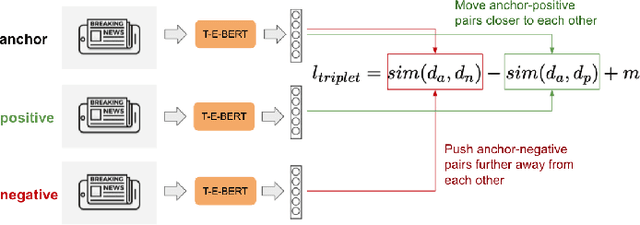
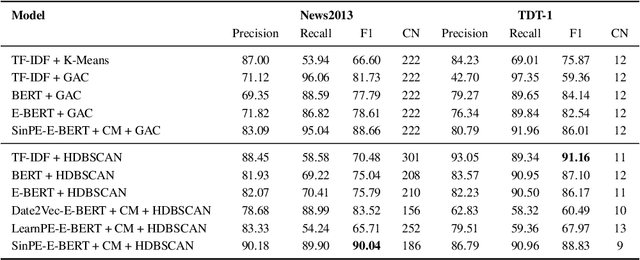
The time at which a message is communicated is a vital piece of metadata in many real-world natural language processing tasks such as Topic Detection and Tracking (TDT). TDT systems aim to cluster a corpus of news articles by event, and in that context, stories that describe the same event are likely to have been written at around the same time. Prior work on time modeling for TDT takes this into account, but does not well capture how time interacts with the semantic nature of the event. For example, stories about a tropical storm are likely to be written within a short time interval, while stories about a movie release may appear over weeks or months. In our work, we design a neural method that fuses temporal and textual information into a single representation of news documents for event detection. We fine-tune these time-aware document embeddings with a triplet loss architecture, integrate the model into downstream TDT systems, and evaluate the systems on two benchmark TDT data sets in English. In the retrospective setting, we apply clustering algorithms to the time-aware embeddings and show substantial improvements over baselines on the News2013 data set. In the online streaming setting, we add our document encoder to an existing state-of-the-art TDT pipeline and demonstrate that it can benefit the overall performance. We conduct ablation studies on the time representation and fusion algorithm strategies, showing that our proposed model outperforms alternative strategies. Finally, we probe the model to examine how it handles recurring events more effectively than previous TDT systems.
Interpretable Multi-Modal Hate Speech Detection
Mar 02, 2021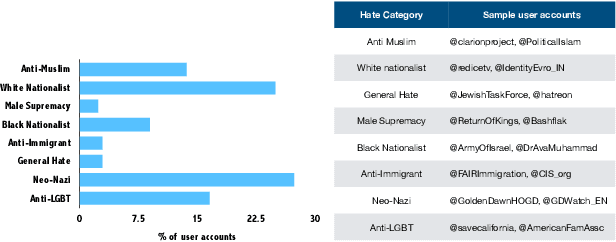

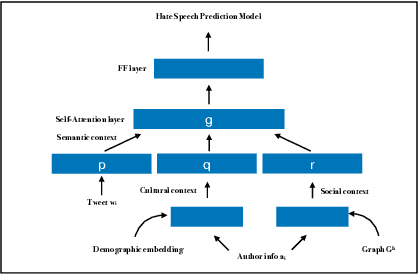
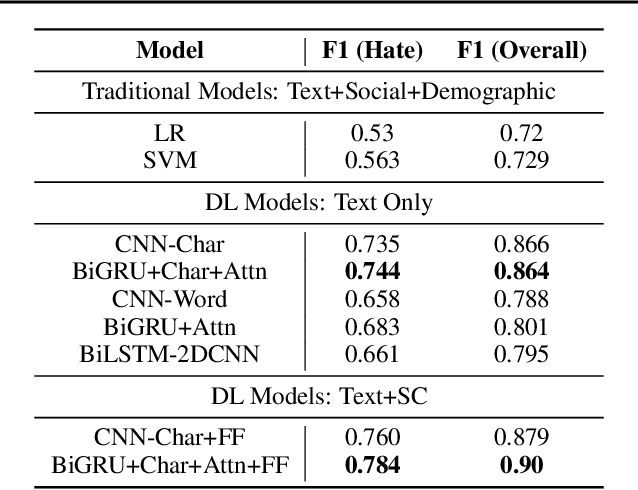
With growing role of social media in shaping public opinions and beliefs across the world, there has been an increased attention to identify and counter the problem of hate speech on social media. Hate speech on online spaces has serious manifestations, including social polarization and hate crimes. While prior works have proposed automated techniques to detect hate speech online, these techniques primarily fail to look beyond the textual content. Moreover, few attempts have been made to focus on the aspects of interpretability of such models given the social and legal implications of incorrect predictions. In this work, we propose a deep neural multi-modal model that can: (a) detect hate speech by effectively capturing the semantics of the text along with socio-cultural context in which a particular hate expression is made, and (b) provide interpretable insights into decisions of our model. By performing a thorough evaluation of different modeling techniques, we demonstrate that our model is able to outperform the existing state-of-the-art hate speech classification approaches. Finally, we show the importance of social and cultural context features towards unearthing clusters associated with different categories of hate.
* 5 pages, Accepted at the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, United States, 2019
Video SemNet: Memory-Augmented Video Semantic Network
Nov 22, 2020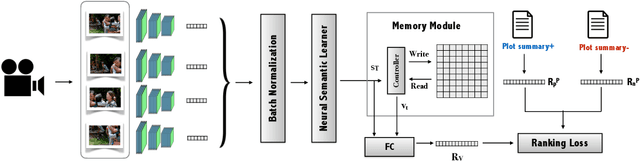
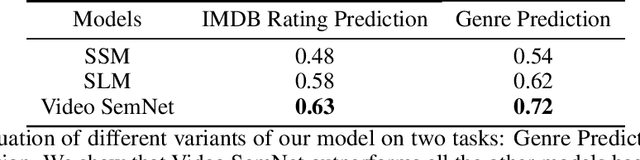
Stories are a very compelling medium to convey ideas, experiences, social and cultural values. Narrative is a specific manifestation of the story that turns it into knowledge for the audience. In this paper, we propose a machine learning approach to capture the narrative elements in movies by bridging the gap between the low-level data representations and semantic aspects of the visual medium. We present a Memory-Augmented Video Semantic Network, called Video SemNet, to encode the semantic descriptors and learn an embedding for the video. The model employs two main components: (i) a neural semantic learner that learns latent embeddings of semantic descriptors and (ii) a memory module that retains and memorizes specific semantic patterns from the video. We evaluate the video representations obtained from variants of our model on two tasks: (a) genre prediction and (b) IMDB Rating prediction. We demonstrate that our model is able to predict genres and IMDB ratings with a weighted F-1 score of 0.72 and 0.63 respectively. The results are indicative of the representational power of our model and the ability of such representations to measure audience engagement.