 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Scattering on Measure Spaces
Aug 17, 2022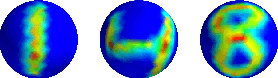
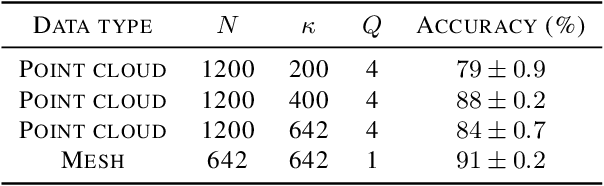
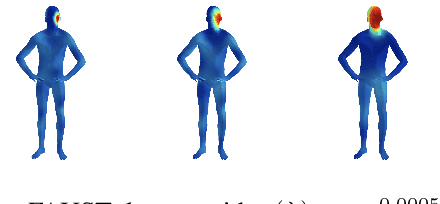

The scattering transform is a multilayered, wavelet-based transform initially introduced as a model of convolutional neural networks (CNNs) that has played a foundational role in our understanding of these networks' stability and invariance properties. Subsequently, there has been widespread interest in extending the success of CNNs to data sets with non-Euclidean structure, such as graphs and manifolds, leading to the emerging field of geometric deep learning. In order to improve our understanding of the architectures used in this new field, several papers have proposed generalizations of the scattering transform for non-Euclidean data structures such as undirected graphs and compact Riemannian manifolds without boundary. In this paper, we introduce a general, unified model for geometric scattering on measure spaces. Our proposed framework includes previous work on geometric scattering as special cases but also applies to more general settings such as directed graphs, signed graphs, and manifolds with boundary. We propose a new criterion that identifies to which groups a useful representation should be invariant and show that this criterion is sufficient to guarantee that the scattering transform has desirable stability and invariance properties. Additionally, we consider finite measure spaces that are obtained from randomly sampling an unknown manifold. We propose two methods for constructing a data-driven graph on which the associated graph scattering transform approximates the scattering transform on the underlying manifold. Moreover, we use a diffusion-maps based approach to prove quantitative estimates on the rate of convergence of one of these approximations as the number of sample points tends to infinity. Lastly, we showcase the utility of our method on spherical images, directed graphs, and on high-dimensional single-cell data.
SP2: A Second Order Stochastic Polyak Method
Jul 17, 2022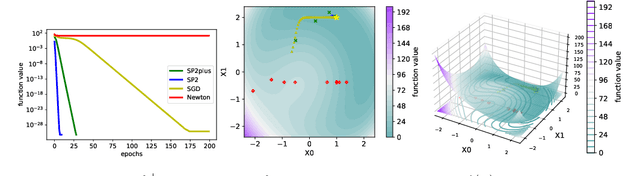
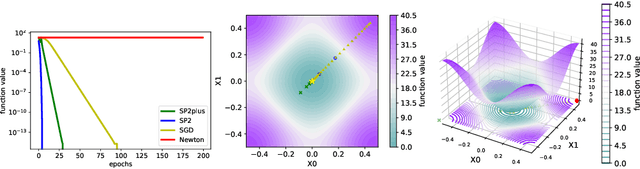
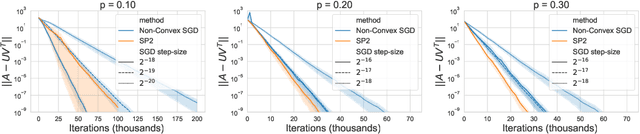
Recently the "SP" (Stochastic Polyak step size) method has emerged as a competitive adaptive method for setting the step sizes of SGD. SP can be interpreted as a method specialized to interpolated models, since it solves the interpolation equations. SP solves these equation by using local linearizations of the model. We take a step further and develop a method for solving the interpolation equations that uses the local second-order approximation of the model. Our resulting method SP2 uses Hessian-vector products to speed-up the convergence of SP. Furthermore, and rather uniquely among second-order methods, the design of SP2 in no way relies on positive definite Hessian matrices or convexity of the objective function. We show SP2 is very competitive on matrix completion, non-convex test problems and logistic regression. We also provide a convergence theory on sums-of-quadratics.
The Manifold Scattering Transform for High-Dimensional Point Cloud Data
Jun 21, 2022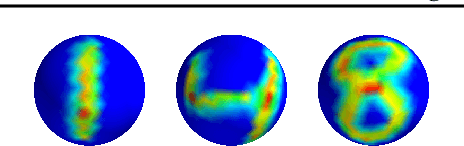
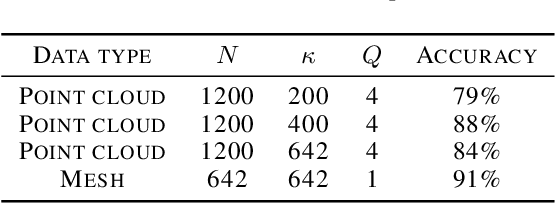


The manifold scattering transform is a deep feature extractor for data defined on a Riemannian manifold. It is one of the first examples of extending convolutional neural network-like operators to general manifolds. The initial work on this model focused primarily on its theoretical stability and invariance properties but did not provide methods for its numerical implementation except in the case of two-dimensional surfaces with predefined meshes. In this work, we present practical schemes, based on the theory of diffusion maps, for implementing the manifold scattering transform to datasets arising in naturalistic systems, such as single cell genetics, where the data is a high-dimensional point cloud modeled as lying on a low-dimensional manifold. We show that our methods are effective for signal classification and manifold classification tasks.
Semi-supervised Nonnegative Matrix Factorization for Document Classification
Feb 28, 2022

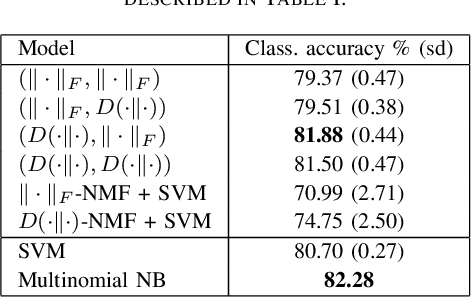

We propose new semi-supervised nonnegative matrix factorization (SSNMF) models for document classification and provide motivation for these models as maximum likelihood estimators. The proposed SSNMF models simultaneously provide both a topic model and a model for classification, thereby offering highly interpretable classification results. We derive training methods using multiplicative updates for each new model, and demonstrate the application of these models to single-label and multi-label document classification, although the models are flexible to other supervised learning tasks such as regression. We illustrate the promise of these models and training methods on document classification datasets (e.g., 20 Newsgroups, Reuters).
Guided Semi-Supervised Non-negative Matrix Factorization on Legal Documents
Jan 31, 2022



Classification and topic modeling are popular techniques in machine learning that extract information from large-scale datasets. By incorporating a priori information such as labels or important features, methods have been developed to perform classification and topic modeling tasks; however, most methods that can perform both do not allow for guidance of the topics or features. In this paper, we propose a method, namely Guided Semi-Supervised Non-negative Matrix Factorization (GSSNMF), that performs both classification and topic modeling by incorporating supervision from both pre-assigned document class labels and user-designed seed words. We test the performance of this method through its application to legal documents provided by the California Innocence Project, a nonprofit that works to free innocent convicted persons and reform the justice system. The results show that our proposed method improves both classification accuracy and topic coherence in comparison to past methods like Semi-Supervised Non-negative Matrix Factorization (SSNMF) and Guided Non-negative Matrix Factorization (Guided NMF).
On audio enhancement via online non-negative matrix factorization
Oct 07, 2021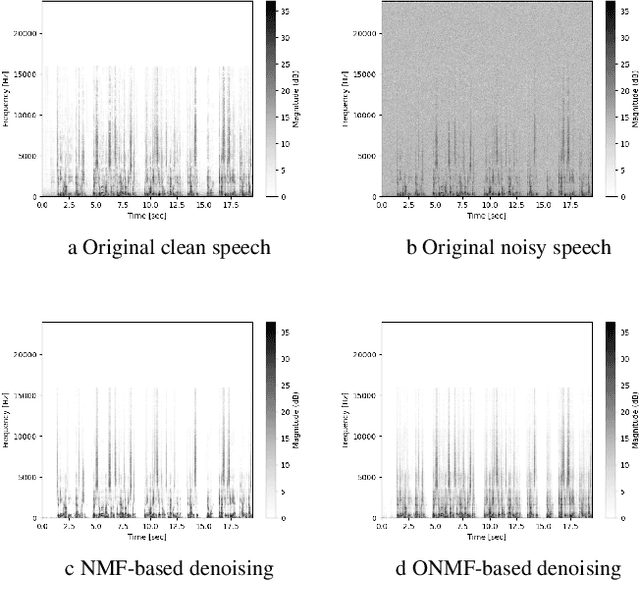
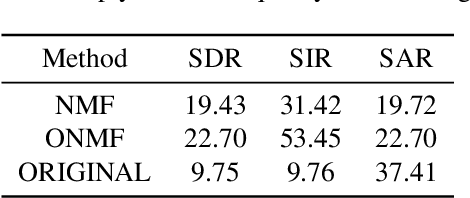
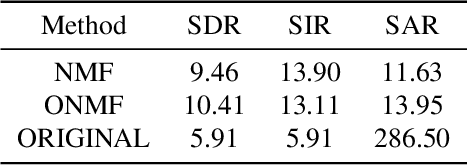

We propose a method for noise reduction, the task of producing a clean audio signal from a recording corrupted by additive noise. Many common approaches to this problem are based upon applying non-negative matrix factorization to spectrogram measurements. These methods use a noiseless recording, which is believed to be similar in structure to the signal of interest, and a pure-noise recording to learn dictionaries for the true signal and the noise. One may then construct an approximation of the true signal by projecting the corrupted recording on to the clean dictionary. In this work, we build upon these methods by proposing the use of \emph{online} non-negative matrix factorization for this problem. This method is more memory efficient than traditional non-negative matrix factorization and also has potential applications to real-time denoising.
A Generalized Hierarchical Nonnegative Tensor Decomposition
Sep 30, 2021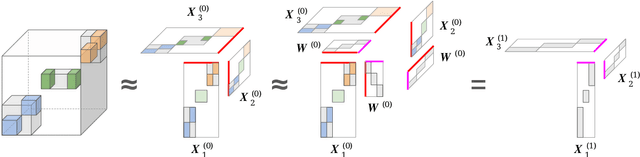
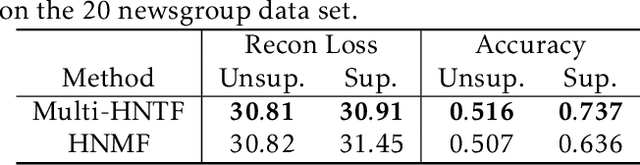
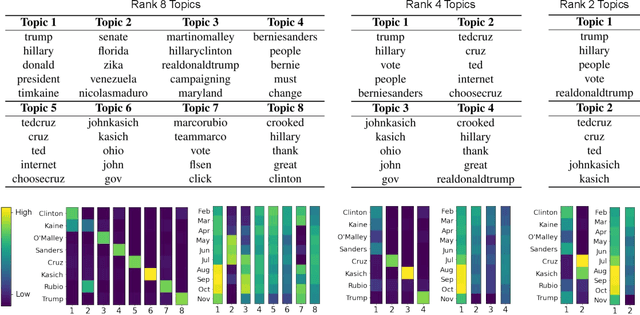
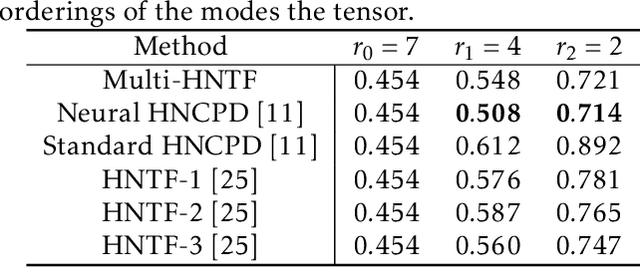
Nonnegative matrix factorization (NMF) has found many applications including topic modeling and document analysis. Hierarchical NMF (HNMF) variants are able to learn topics at various levels of granularity and illustrate their hierarchical relationship. Recently, nonnegative tensor factorization (NTF) methods have been applied in a similar fashion in order to handle data sets with complex, multi-modal structure. Hierarchical NTF (HNTF) methods have been proposed, however these methods do not naturally generalize their matrix-based counterparts. Here, we propose a new HNTF model which directly generalizes a HNMF model special case, and provide a supervised extension. We also provide a multiplicative updates training method for this model. Our experimental results show that this model more naturally illuminates the topic hierarchy than previous HNMF and HNTF methods.
Fast Robust Tensor Principal Component Analysis via Fiber CUR Decomposition
Aug 23, 2021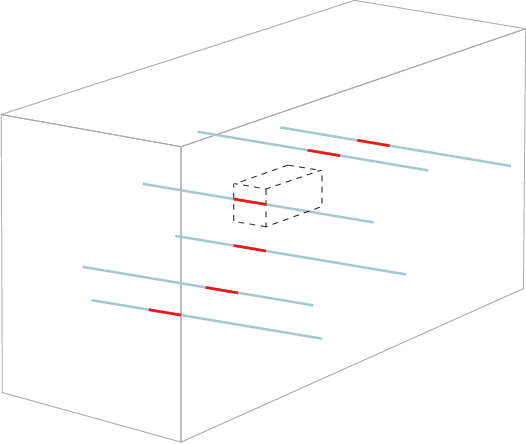
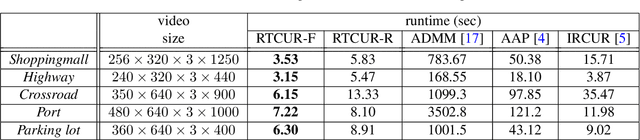
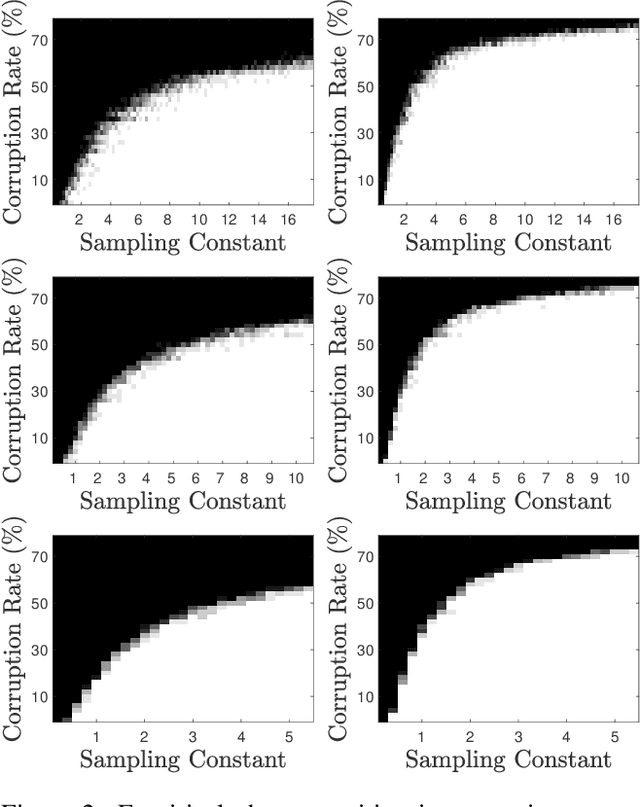
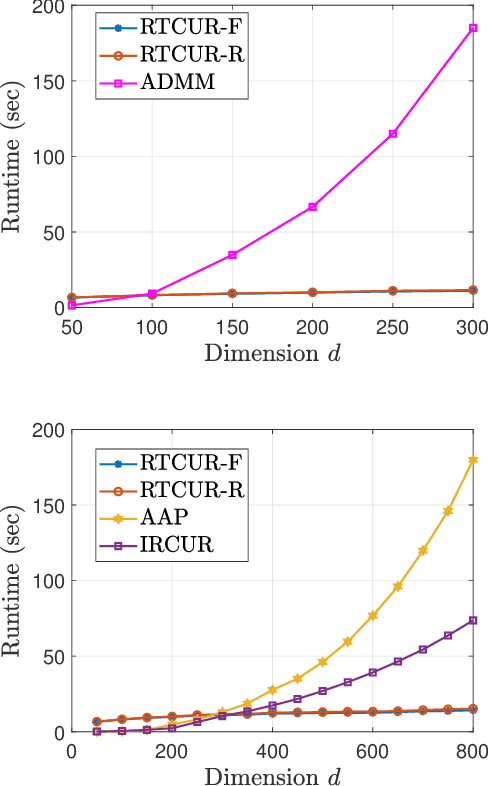
We study the problem of tensor robust principal component analysis (TRPCA), which aims to separate an underlying low-multilinear-rank tensor and a sparse outlier tensor from their sum. In this work, we propose a fast non-convex algorithm, coined Robust Tensor CUR (RTCUR), for large-scale TRPCA problems. RTCUR considers a framework of alternating projections and utilizes the recently developed tensor Fiber CUR decomposition to dramatically lower the computational complexity. The performance advantage of RTCUR is empirically verified against the state-of-the-arts on the synthetic datasets and is further demonstrated on the real-world application such as color video background subtraction.
Analysis of Legal Documents via Non-negative Matrix Factorization Methods
Apr 28, 2021The California Innocence Project (CIP), a clinical law school program aiming to free wrongfully convicted prisoners, evaluates thousands of mails containing new requests for assistance and corresponding case files. Processing and interpreting this large amount of information presents a significant challenge for CIP officials, which can be successfully aided by topic modeling techniques.In this paper, we apply Non-negative Matrix Factorization (NMF) method and implement various offshoots of it to the important and previously unstudied data set compiled by CIP. We identify underlying topics of existing case files and classify request files by crime type and case status (decision type). The results uncover the semantic structure of current case files and can provide CIP officials with a general understanding of newly received case files before further examinations. We also provide an exposition of popular variants of NMF with their experimental results and discuss the benefits and drawbacks of each variant through the real-world application.
Mode-wise Tensor Decompositions: Multi-dimensional Generalizations of CUR Decompositions
Mar 19, 2021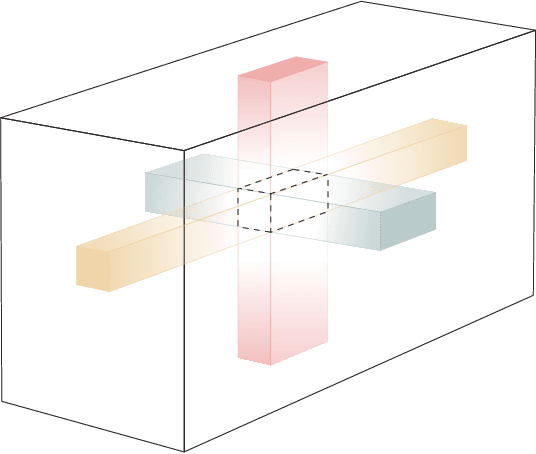
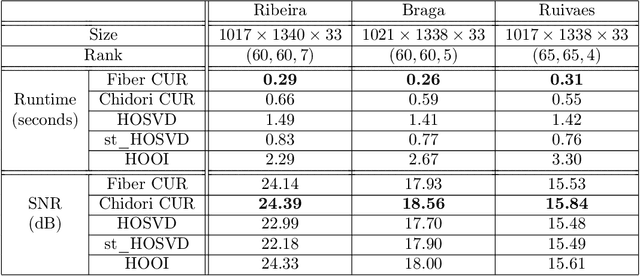
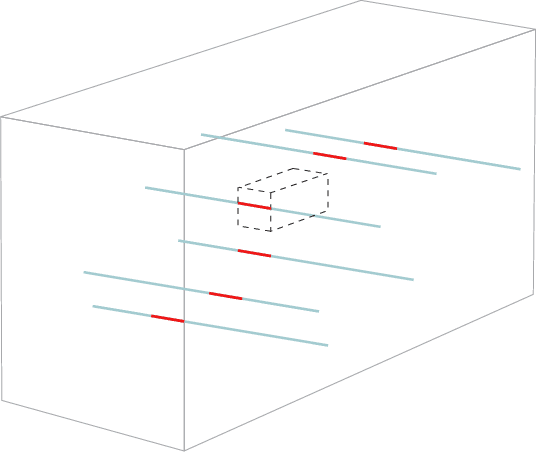
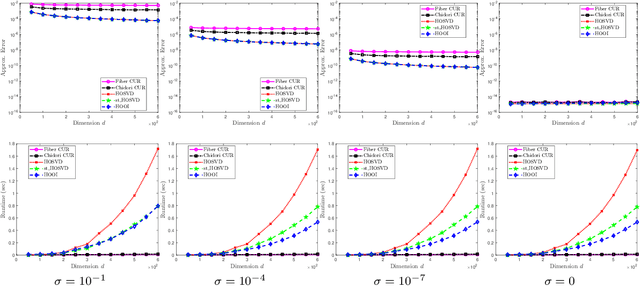
Low rank tensor approximation is a fundamental tool in modern machine learning and data science. In this paper, we study the characterization, perturbation analysis, and an efficient sampling strategy for two primary tensor CUR approximations, namely Chidori and Fiber CUR. We characterize exact tensor CUR decompositions for low multilinear rank tensors. We also present theoretical error bound of the tensor CUR approximations when (adversarial or Gaussian) noise appears. Moreover, we show that low cost uniform sampling is sufficient for tensor CUR approximations if the tensor has an incoherent structure. Empirical performance evaluations, with both synthetic and real-world datasets, establish the advantage of the tensor CUR approximations over other state-of-the-art low multilinear rank tensor approximations.