 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvalanche: an End-to-End Library for Continual Learning
Apr 01, 2021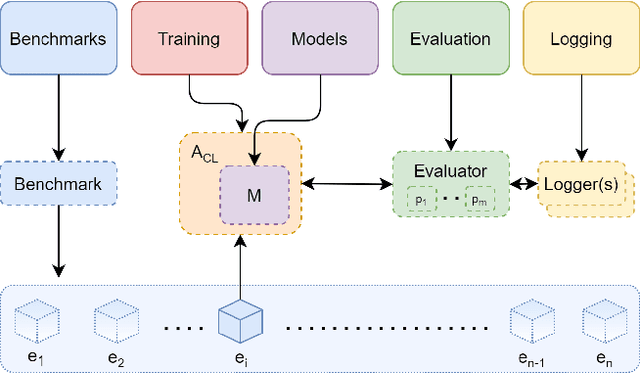


Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
CVPR 2020 Continual Learning in Computer Vision Competition: Approaches, Results, Current Challenges and Future Directions
Sep 14, 2020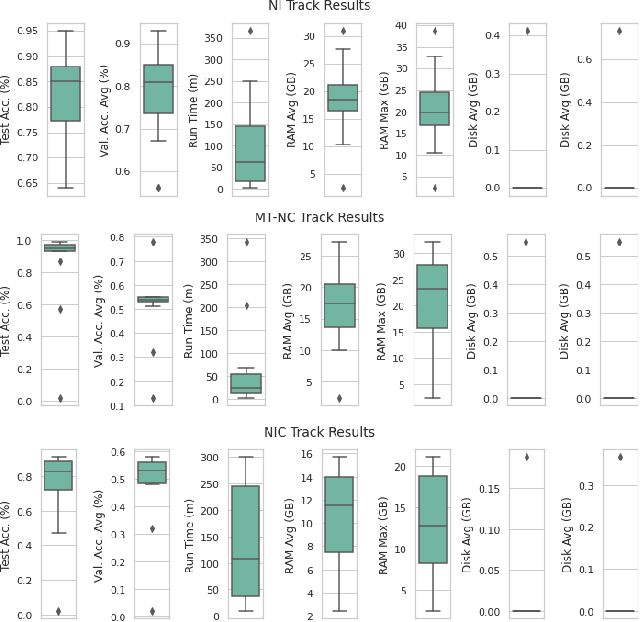
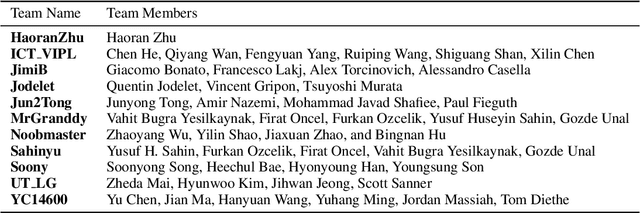

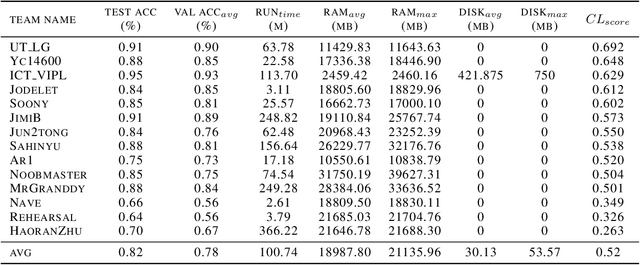
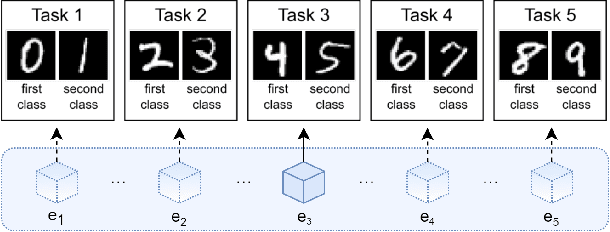
In the last few years, we have witnessed a renewed and fast-growing interest in continual learning with deep neural networks with the shared objective of making current AI systems more adaptive, efficient and autonomous. However, despite the significant and undoubted progress of the field in addressing the issue of catastrophic forgetting, benchmarking different continual learning approaches is a difficult task by itself. In fact, given the proliferation of different settings, training and evaluation protocols, metrics and nomenclature, it is often tricky to properly characterize a continual learning algorithm, relate it to other solutions and gauge its real-world applicability. The first Continual Learning in Computer Vision challenge held at CVPR in 2020 has been one of the first opportunities to evaluate different continual learning algorithms on a common hardware with a large set of shared evaluation metrics and 3 different settings based on the realistic CORe50 video benchmark. In this paper, we report the main results of the competition, which counted more than 79 teams registered, 11 finalists and 2300$ in prizes. We also summarize the winning approaches, current challenges and future research directions.
Morphing Attack Detection -- Database, Evaluation Platform and Benchmarking
Jun 16, 2020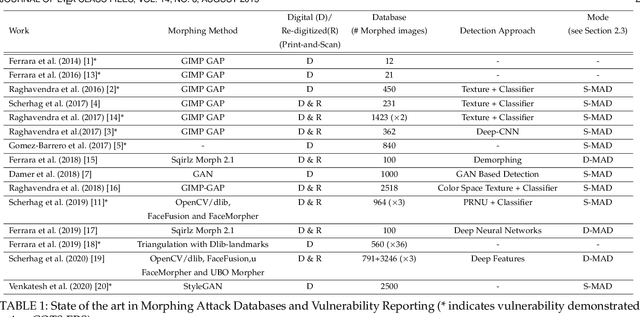
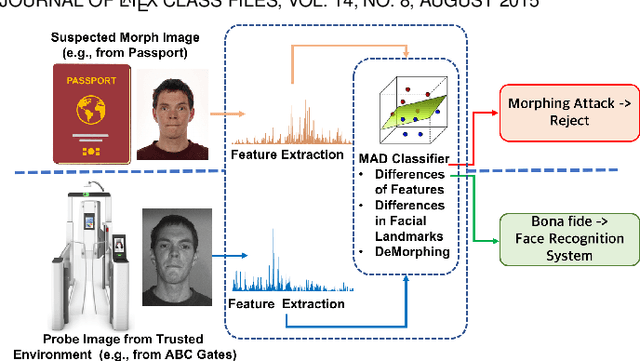
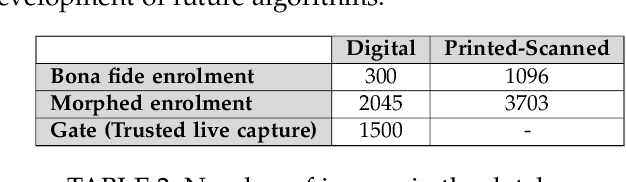

Morphing attacks have posed a severe threat to Face Recognition System (FRS). Despite the number of advancements reported in recent works, we note serious open issues that are not addressed. Morphing Attack Detection (MAD) algorithms often are prone to generalization challenges as they are database dependent. The existing databases, mostly of semi-public nature, lack in diversity in terms of ethnicity, various morphing process and post-processing pipelines. Further, they do not reflect a realistic operational scenario for Automated Border Control (ABC) and do not provide a basis to test MAD on unseen data, in order to benchmark the robustness of algorithms. In this work, we present a new sequestered dataset for facilitating the advancements of MAD where the algorithms can be tested on unseen data in an effort to better generalize. The newly constructed dataset consists of facial images from 150 subjects from various ethnicities, age-groups and both genders. In order to challenge the existing MAD algorithms, the morphed images are with careful subject pre-selection created from the subjects, and further post-processed to remove the morphing artifacts. The images are also printed and scanned to remove all digital cues and to simulate a realistic challenge for MAD algorithms. Further, we present a new online evaluation platform to test algorithms on sequestered data. With the platform we can benchmark the morph detection performance and study the generalization ability. This work also presents a detailed analysis on various subsets of sequestered data and outlines open challenges for future directions in MAD research.
IROS 2019 Lifelong Robotic Vision Challenge -- Lifelong Object Recognition Report
Apr 26, 2020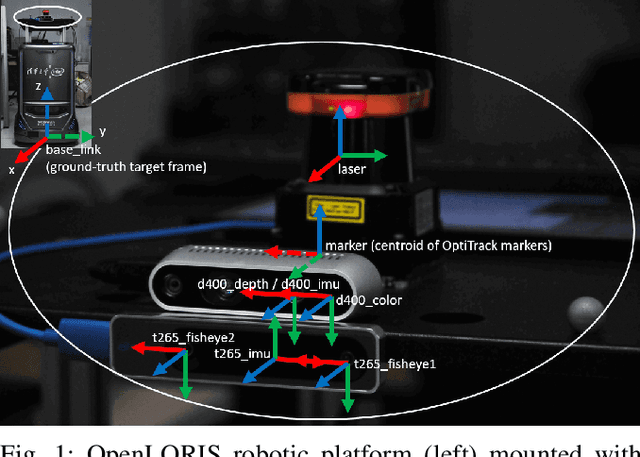


This report summarizes IROS 2019-Lifelong Robotic Vision Competition (Lifelong Object Recognition Challenge) with methods and results from the top $8$ finalists (out of over~$150$ teams). The competition dataset (L)ifel(O)ng (R)obotic V(IS)ion (OpenLORIS) - Object Recognition (OpenLORIS-object) is designed for driving lifelong/continual learning research and application in robotic vision domain, with everyday objects in home, office, campus, and mall scenarios. The dataset explicitly quantifies the variants of illumination, object occlusion, object size, camera-object distance/angles, and clutter information. Rules are designed to quantify the learning capability of the robotic vision system when faced with the objects appearing in the dynamic environments in the contest. Individual reports, dataset information, rules, and released source code can be found at the project homepage: "https://lifelong-robotic-vision.github.io/competition/".
Latent Replay for Real-Time Continual Learning
Dec 02, 2019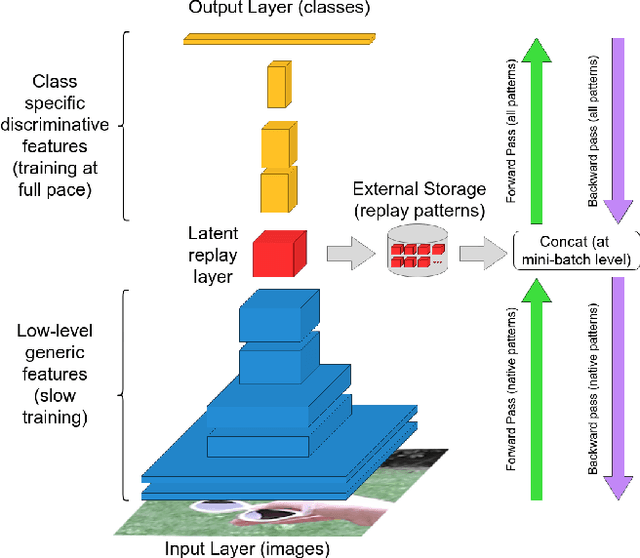
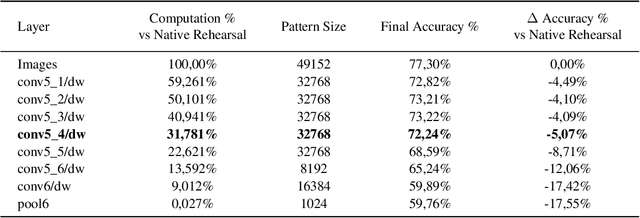
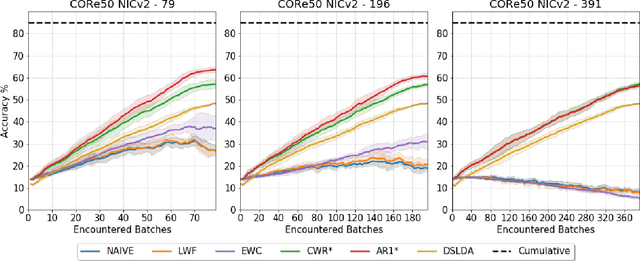
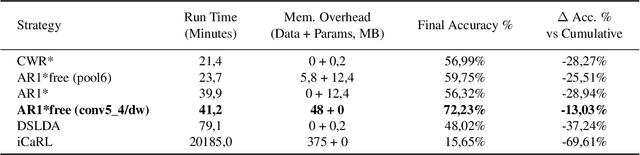
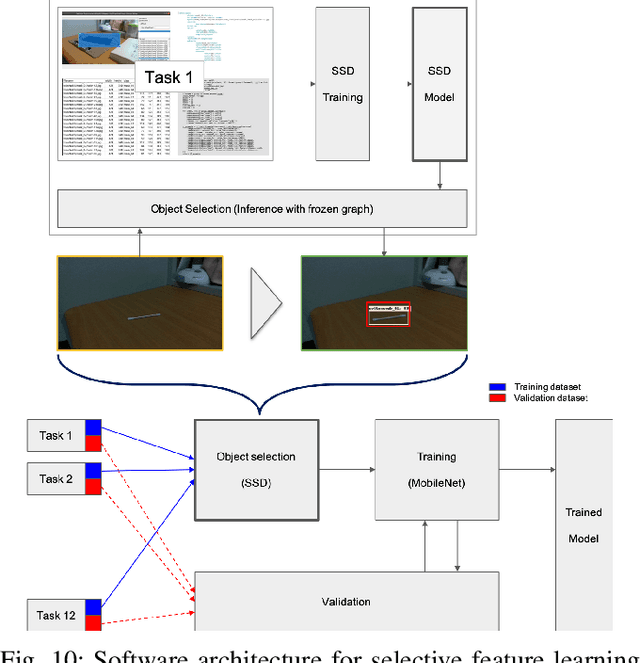
Training deep networks on light computational devices is nowadays very challenging. Continual learning techniques, where complex models are incrementally trained on small batches of new data, can make the learning problem tractable even for CPU-only edge devices. However, a number of practical problems need to be solved: catastrophic forgetting before anything else. In this paper we introduce an original technique named ``Latent Replay'' where, instead of storing a portion of past data in the input space, we store activations volumes at some intermediate layer. This can significantly reduce the computation and storage required by native rehearsal. To keep the representation stable and the stored activations valid we propose to slow-down learning at all the layers below the latent replay one, leaving the layers above free to learn at full pace. In our experiments we show that Latent Replay, combined with existing continual learning techniques, achieves state-of-the-art accuracy on a difficult benchmark such as CORe50 NICv2 with nearly 400 small and highly non-i.i.d. batches. Finally, we demonstrate the feasibility of nearly real-time continual learning on the edge through the porting of the proposed technique on a smartphone device.
Fine-Grained Continual Learning
Jul 08, 2019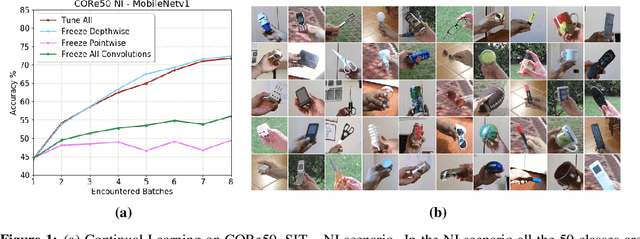
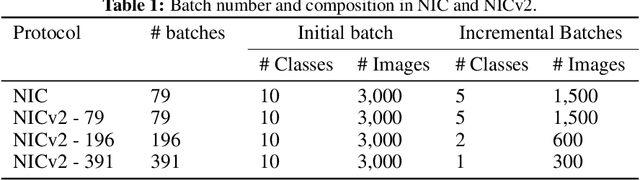
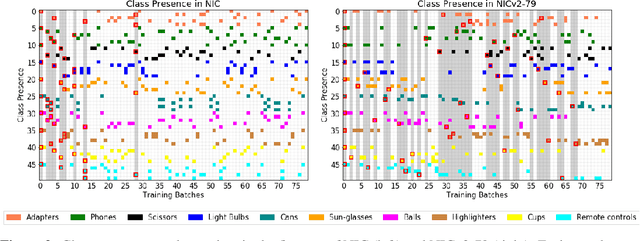

Robotic vision is a field where continual learning can play a significant role. An embodied agent operating in a complex environment subject to frequent and unpredictable changes is required to learn and adapt continuously. In the context of object recognition, for example, a robot should be able to learn (without forgetting) objects of never seen classes as well as improving its recognition capabilities as new instances of already known classes are discovered. Ideally, continual learning should be triggered by the availability of short videos of single objects and performed online on onboard hardware. In this paper, we introduce a novel fine-grained continual learning protocol based on the CORe50 benchmark and propose two continual learning techniques that can learn effectively even in the challenging case of nearly 400 small non-i.i.d. incremental batches.
Continual Learning for Robotics
Jun 29, 2019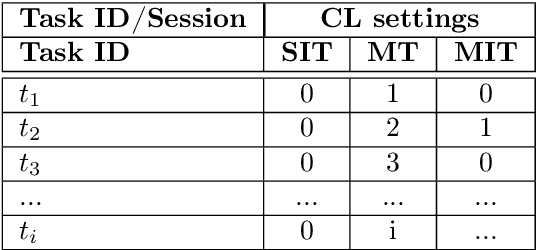

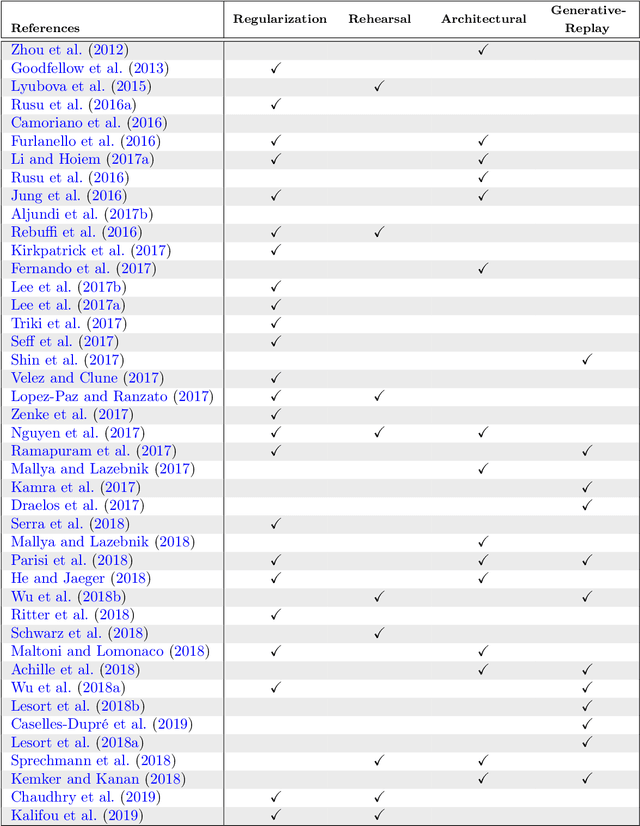

Continual learning (CL) is a particular machine learning paradigm where the data distribution and learning objective changes through time, or where all the training data and objective criteria are never available at once. The evolution of the learning process is modeled by a sequence of learning experiences where the goal is to be able to learn new skills all along the sequence without forgetting what has been previously learned. Continual learning also aims at the same time at optimizing the memory, the computation power and the speed during the learning process. An important challenge for machine learning is not necessarily finding solutions that work in the real world but rather finding stable algorithms that can learn in real world. Hence, the ideal approach would be tackling the real world in a embodied platform: an autonomous agent. Continual learning would then be effective in an autonomous agent or robot, which would learn autonomously through time about the external world, and incrementally develop a set of complex skills and knowledge. Robotic agents have to learn to adapt and interact with their environment using a continuous stream of observations. Some recent approaches aim at tackling continual learning for robotics, but most recent papers on continual learning only experiment approaches in simulation or with static datasets. Unfortunately, the evaluation of those algorithms does not provide insights on whether their solutions may help continual learning in the context of robotics. This paper aims at reviewing the existing state of the art of continual learning, summarizing existing benchmarks and metrics, and proposing a framework for presenting and evaluating both robotics and non robotics approaches in a way that makes transfer between both fields easier.
Continual Reinforcement Learning in 3D Non-stationary Environments
May 24, 2019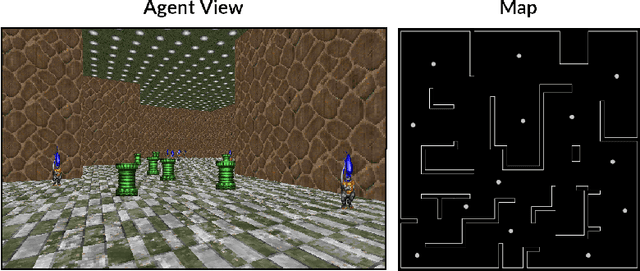
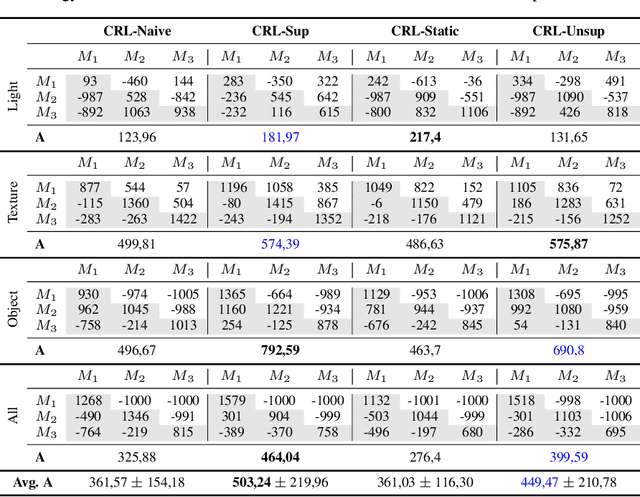

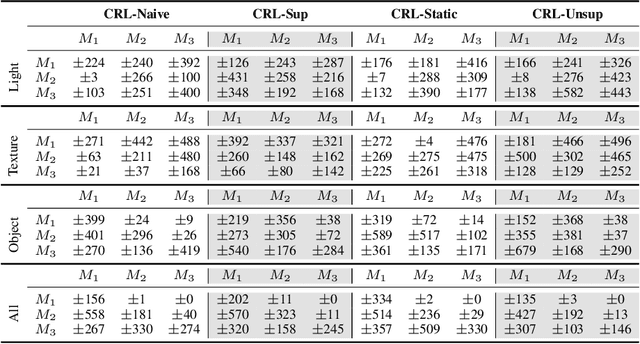
High-dimensional always-changing environments constitute a hard challenge for current reinforcement learning techniques. Artificial agents, nowadays, are often trained off-line in very static and controlled conditions in simulation such that training observations can be thought as sampled i.i.d. from the entire observations space. However, in real world settings, the environment is often non-stationary and subject to unpredictable, frequent changes. In this paper we propose and openly release CRLMaze, a new benchmark for learning continually through reinforcement in a complex 3D non-stationary task based on ViZDoom and subject to several environmental changes. Then, we introduce an end-to-end model-free continual reinforcement learning strategy showing competitive results with respect to four different baselines and not requiring any access to additional supervised signals, previously encountered environmental conditions or observations.
Face morphing detection in the presence of printing/scanning and heterogeneous image sources
Jan 25, 2019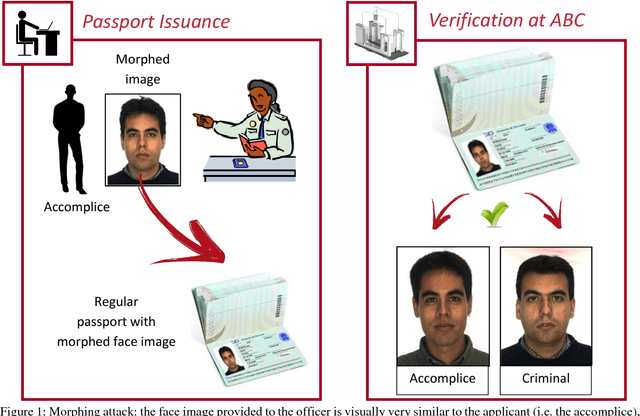

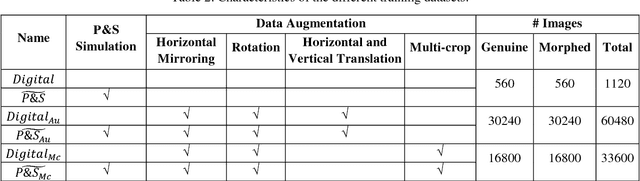

Face morphing represents nowadays a big security threat in the context of electronic identity documents as well as an interesting challenge for researchers in the field of face recognition. Despite of the good performance obtained by state-of-the-art approaches on digital images, no satisfactory solutions have been identified so far to deal with cross-database testing and printed-scanned images (typically used in many countries for document issuing). In this work, novel approaches are proposed to train Deep Neural Networks for morphing detection: in particular generation of simulated printed-scanned images together with other data augmentation strategies and pre-training on large face recognition datasets, allowed to reach state-of-the-art accuracy on challenging datasets from heterogeneous image sources.
Don't forget, there is more than forgetting: new metrics for Continual Learning
Oct 31, 2018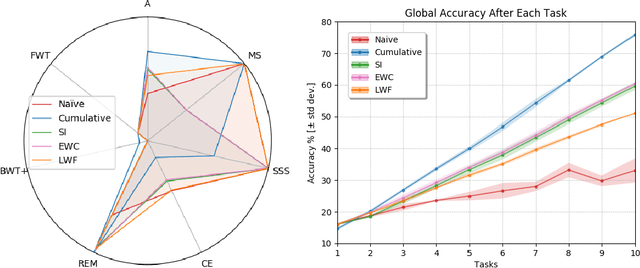
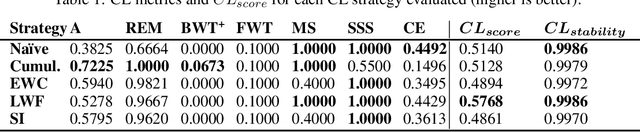
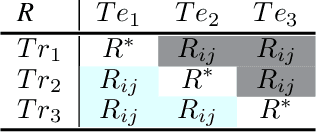
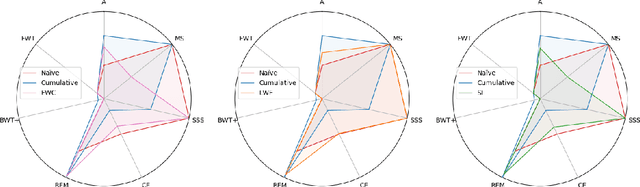
Continual learning consists of algorithms that learn from a stream of data/tasks continuously and adaptively thought time, enabling the incremental development of ever more complex knowledge and skills. The lack of consensus in evaluating continual learning algorithms and the almost exclusive focus on forgetting motivate us to propose a more comprehensive set of implementation independent metrics accounting for several factors we believe have practical implications worth considering in the deployment of real AI systems that learn continually: accuracy or performance over time, backward and forward knowledge transfer, memory overhead as well as computational efficiency. Drawing inspiration from the standard Multi-Attribute Value Theory (MAVT) we further propose to fuse these metrics into a single score for ranking purposes and we evaluate our proposal with five continual learning strategies on the iCIFAR-100 continual learning benchmark.