 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in leveraging GANs for few-shot data augmentation
Mar 30, 2022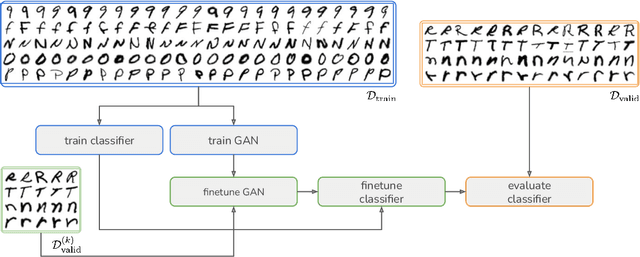
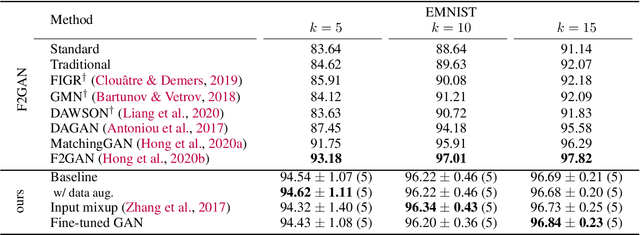
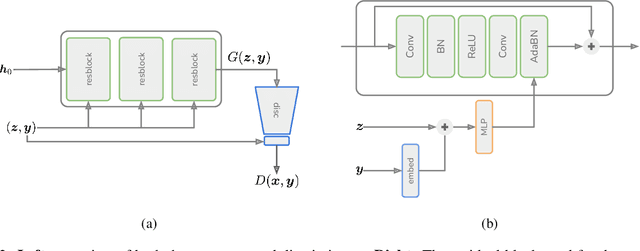

In this paper, we explore the use of GAN-based few-shot data augmentation as a method to improve few-shot classification performance. We perform an exploration into how a GAN can be fine-tuned for such a task (one of which is in a class-incremental manner), as well as a rigorous empirical investigation into how well these models can perform to improve few-shot classification. We identify issues related to the difficulty of training such generative models under a purely supervised regime with very few examples, as well as issues regarding the evaluation protocols of existing works. We also find that in this regime, classification accuracy is highly sensitive to how the classes of the dataset are randomly split. Therefore, we propose a semi-supervised fine-tuning approach as a more pragmatic way forward to address these problems.
Toward Foundation Models for Earth Monitoring: Proposal for a Climate Change Benchmark
Dec 01, 2021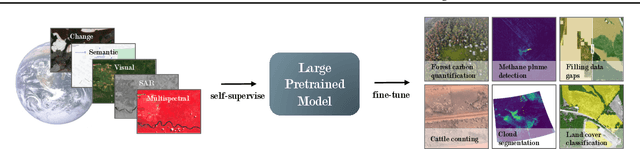
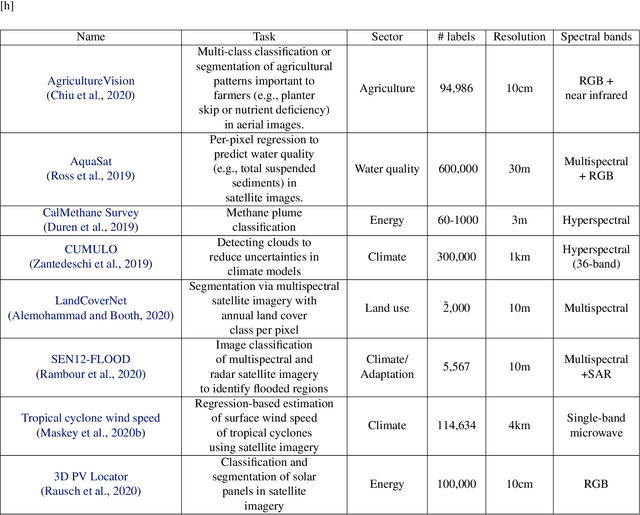
Recent progress in self-supervision shows that pre-training large neural networks on vast amounts of unsupervised data can lead to impressive increases in generalisation for downstream tasks. Such models, recently coined as foundation models, have been transformational to the field of natural language processing. While similar models have also been trained on large corpuses of images, they are not well suited for remote sensing data. To stimulate the development of foundation models for Earth monitoring, we propose to develop a new benchmark comprised of a variety of downstream tasks related to climate change. We believe that this can lead to substantial improvements in many existing applications and facilitate the development of new applications. This proposal is also a call for collaboration with the aim of developing a better evaluation process to mitigate potential downsides of foundation models for Earth monitoring.
Multi-label Iterated Learning for Image Classification with Label Ambiguity
Nov 23, 2021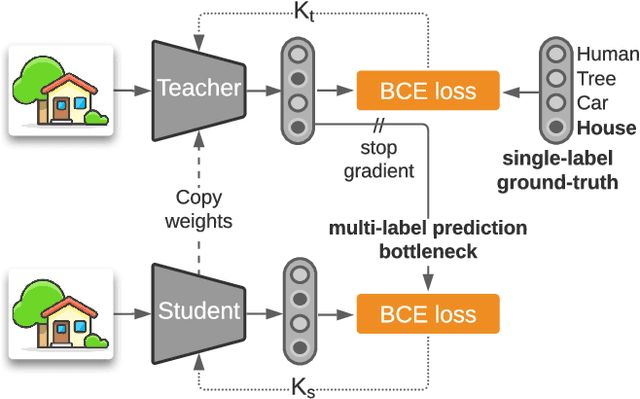
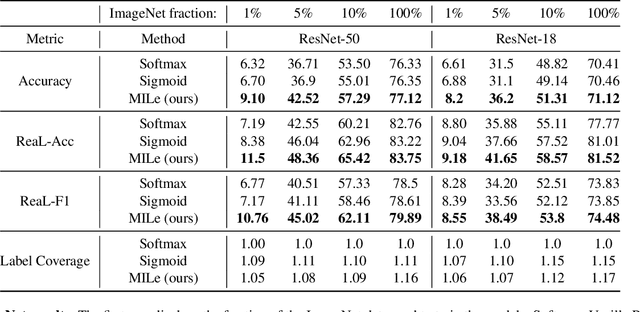

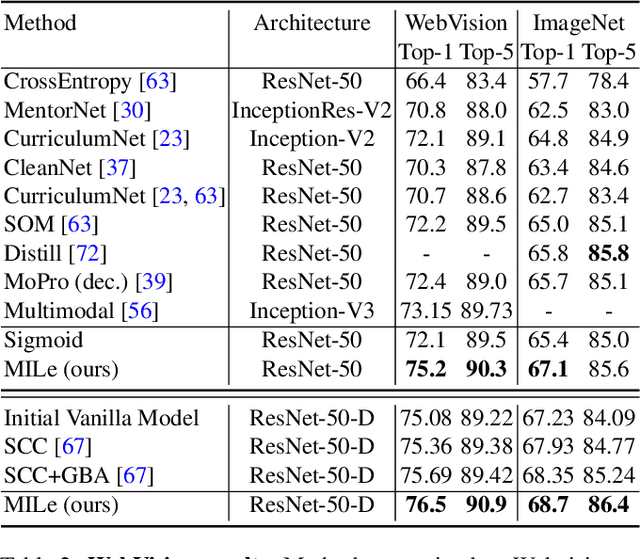
Transfer learning from large-scale pre-trained models has become essential for many computer vision tasks. Recent studies have shown that datasets like ImageNet are weakly labeled since images with multiple object classes present are assigned a single label. This ambiguity biases models towards a single prediction, which could result in the suppression of classes that tend to co-occur in the data. Inspired by language emergence literature, we propose multi-label iterated learning (MILe) to incorporate the inductive biases of multi-label learning from single labels using the framework of iterated learning. MILe is a simple yet effective procedure that builds a multi-label description of the image by propagating binary predictions through successive generations of teacher and student networks with a learning bottleneck. Experiments show that our approach exhibits systematic benefits on ImageNet accuracy as well as ReaL F1 score, which indicates that MILe deals better with label ambiguity than the standard training procedure, even when fine-tuning from self-supervised weights. We also show that MILe is effective reducing label noise, achieving state-of-the-art performance on real-world large-scale noisy data such as WebVision. Furthermore, MILe improves performance in class incremental settings such as IIRC and it is robust to distribution shifts. Code: https://github.com/rajeswar18/MILe
A Survey of Self-Supervised and Few-Shot Object Detection
Nov 08, 2021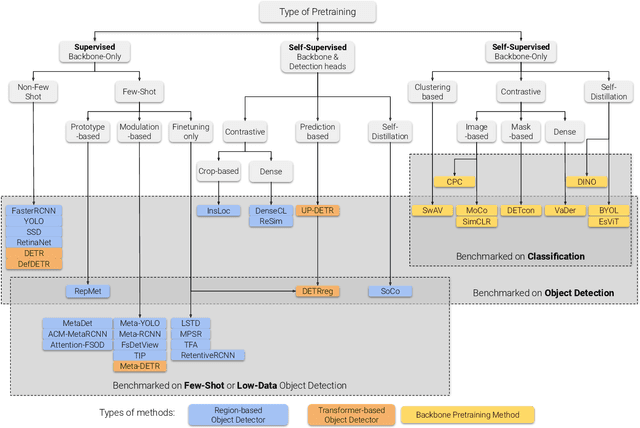

Labeling data is often expensive and time-consuming, especially for tasks such as object detection and instance segmentation, which require dense labeling of the image. While few-shot object detection is about training a model on novel (unseen) object classes with little data, it still requires prior training on many labeled examples of base (seen) classes. On the other hand, self-supervised methods aim at learning representations from unlabeled data which transfer well to downstream tasks such as object detection. Combining few-shot and self-supervised object detection is a promising research direction. In this survey, we review and characterize the most recent approaches on few-shot and self-supervised object detection. Then, we give our main takeaways and discuss future research directions. Project page at https://gabrielhuang.github.io/fsod-survey/
A Deep Learning Localization Method for Measuring Abdominal Muscle Dimensions in Ultrasound Images
Sep 30, 2021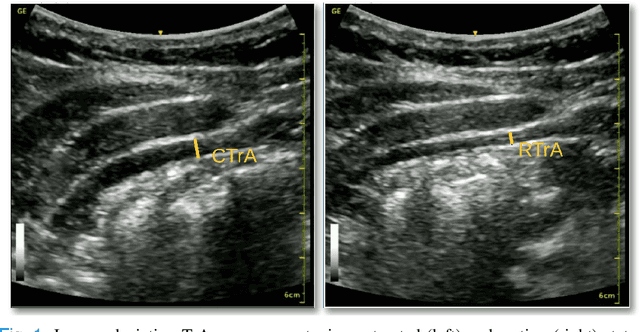
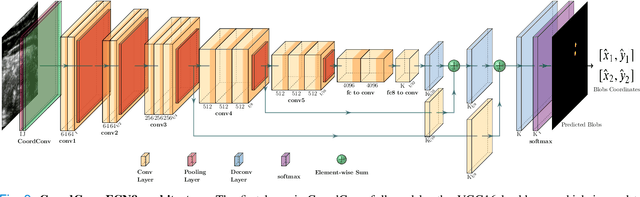
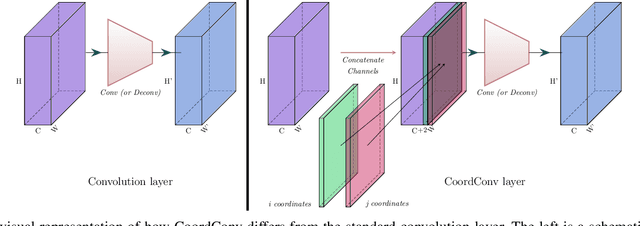

Health professionals extensively use Two- Dimensional (2D) Ultrasound (US) videos and images to visualize and measure internal organs for various purposes including evaluation of muscle architectural changes. US images can be used to measure abdominal muscles dimensions for the diagnosis and creation of customized treatment plans for patients with Low Back Pain (LBP), however, they are difficult to interpret. Due to high variability, skilled professionals with specialized training are required to take measurements to avoid low intra-observer reliability. This variability stems from the challenging nature of accurately finding the correct spatial location of measurement endpoints in abdominal US images. In this paper, we use a Deep Learning (DL) approach to automate the measurement of the abdominal muscle thickness in 2D US images. By treating the problem as a localization task, we develop a modified Fully Convolutional Network (FCN) architecture to generate blobs of coordinate locations of measurement endpoints, similar to what a human operator does. We demonstrate that using the TrA400 US image dataset, our network achieves a Mean Absolute Error (MAE) of 0.3125 on the test set, which almost matches the performance of skilled ultrasound technicians. Our approach can facilitate next steps for automating the process of measurements in 2D US images, while reducing inter-observer as well as intra-observer variability for more effective clinical outcomes.
SSR: Semi-supervised Soft Rasterizer for single-view 2D to 3D Reconstruction
Aug 21, 2021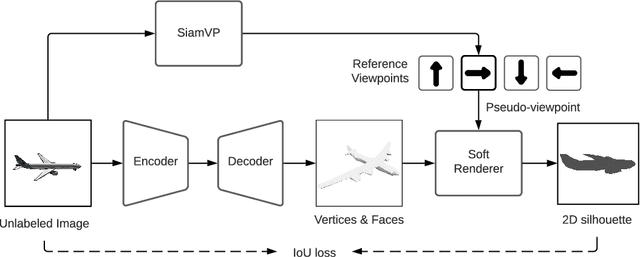
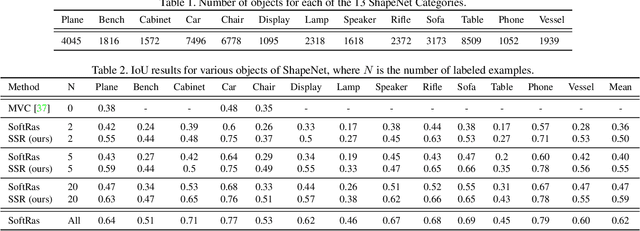
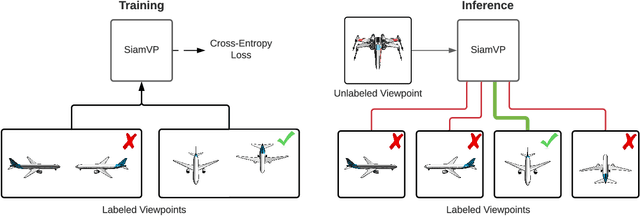
Recent work has made significant progress in learning object meshes with weak supervision. Soft Rasterization methods have achieved accurate 3D reconstruction from 2D images with viewpoint supervision only. In this work, we further reduce the labeling effort by allowing such 3D reconstruction methods leverage unlabeled images. In order to obtain the viewpoints for these unlabeled images, we propose to use a Siamese network that takes two images as input and outputs whether they correspond to the same viewpoint. During training, we minimize the cross entropy loss to maximize the probability of predicting whether a pair of images belong to the same viewpoint or not. To get the viewpoint of a new image, we compare it against different viewpoints obtained from the training samples and select the viewpoint with the highest matching probability. We finally label the unlabeled images with the most confident predicted viewpoint and train a deep network that has a differentiable rasterization layer. Our experiments show that even labeling only two objects yields significant improvement in IoU for ShapeNet when leveraging unlabeled examples. Code is available at https://github.com/IssamLaradji/SSR.
Touch-based Curiosity for Sparse-Reward Tasks
Apr 01, 2021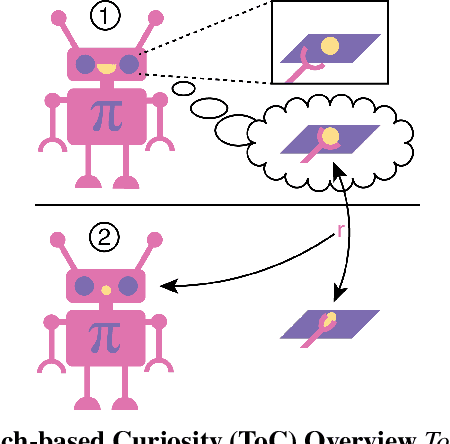
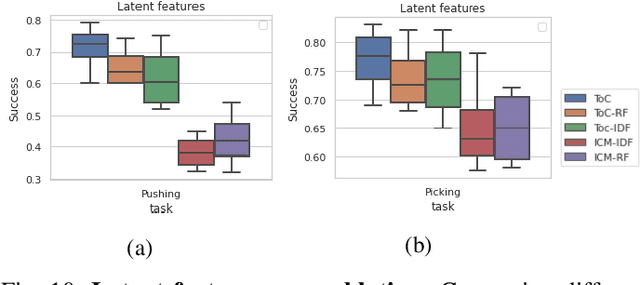
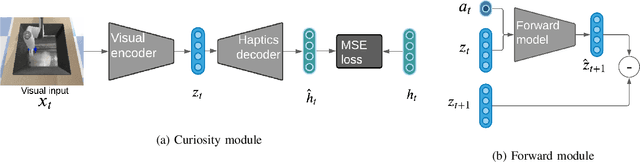
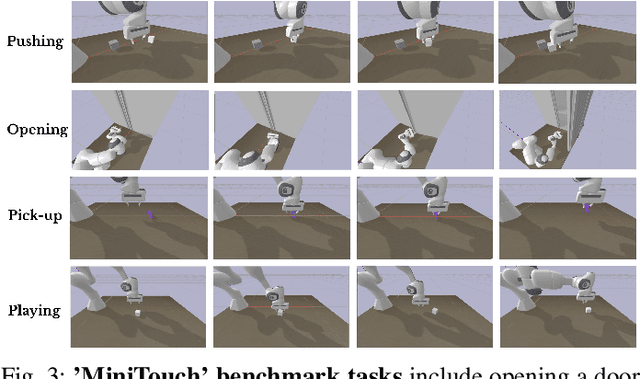
Robots in many real-world settings have access to force/torque sensors in their gripper and tactile sensing is often necessary in tasks that involve contact-rich motion. In this work, we leverage surprise from mismatches in touch feedback to guide exploration in hard sparse-reward reinforcement learning tasks. Our approach, Touch-based Curiosity (ToC), learns what visible objects interactions are supposed to "feel" like. We encourage exploration by rewarding interactions where the expectation and the experience don't match. In our proposed method, an initial task-independent exploration phase is followed by an on-task learning phase, in which the original interactions are relabeled with on-task rewards. We test our approach on a range of touch-intensive robot arm tasks (e.g. pushing objects, opening doors), which we also release as part of this work. Across multiple experiments in a simulated setting, we demonstrate that our method is able to learn these difficult tasks through sparse reward and curiosity alone. We compare our cross-modal approach to single-modality (touch- or vision-only) approaches as well as other curiosity-based methods and find that our method performs better and is more sample-efficient.
Seasonal Contrast: Unsupervised Pre-Training from Uncurated Remote Sensing Data
Mar 30, 2021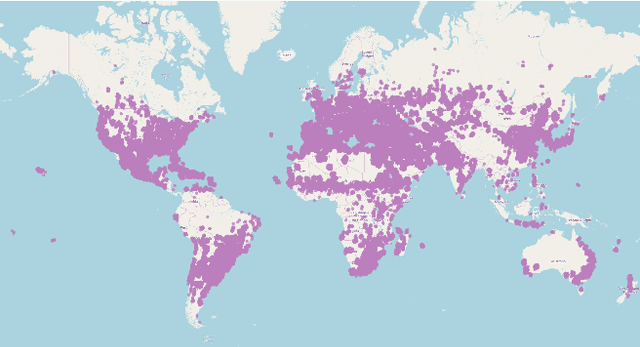
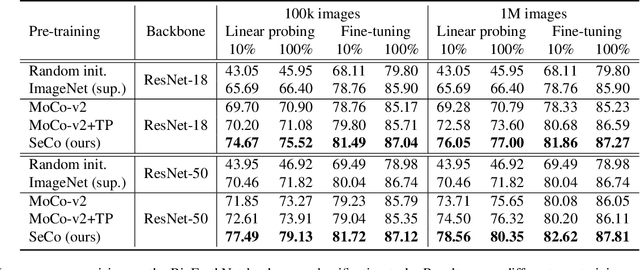
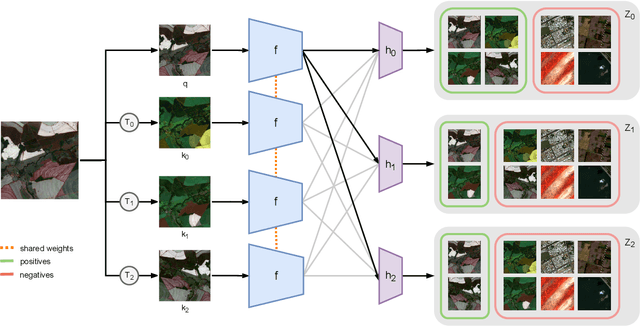

Remote sensing and automatic earth monitoring are key to solve global-scale challenges such as disaster prevention, land use monitoring, or tackling climate change. Although there exist vast amounts of remote sensing data, most of it remains unlabeled and thus inaccessible for supervised learning algorithms. Transfer learning approaches can reduce the data requirements of deep learning algorithms. However, most of these methods are pre-trained on ImageNet and their generalization to remote sensing imagery is not guaranteed due to the domain gap. In this work, we propose Seasonal Contrast (SeCo), an effective pipeline to leverage unlabeled data for in-domain pre-training of re-mote sensing representations. The SeCo pipeline is com-posed of two parts. First, a principled procedure to gather large-scale, unlabeled and uncurated remote sensing datasets containing images from multiple Earth locations at different timestamps. Second, a self-supervised algorithm that takes advantage of time and position invariance to learn transferable representations for re-mote sensing applications. We empirically show that models trained with SeCo achieve better performance than their ImageNet pre-trained counterparts and state-of-the-art self-supervised learning methods on multiple downstream tasks. The datasets and models in SeCo will be made public to facilitate transfer learning and enable rapid progress in re-mote sensing applications.
Beyond Trivial Counterfactual Explanations with Diverse Valuable Explanations
Mar 18, 2021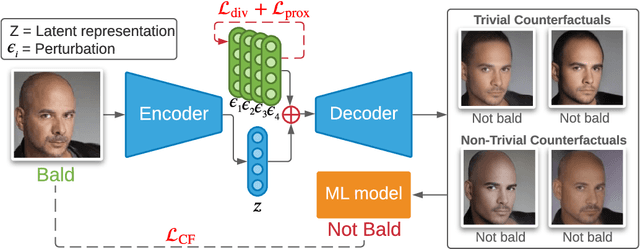
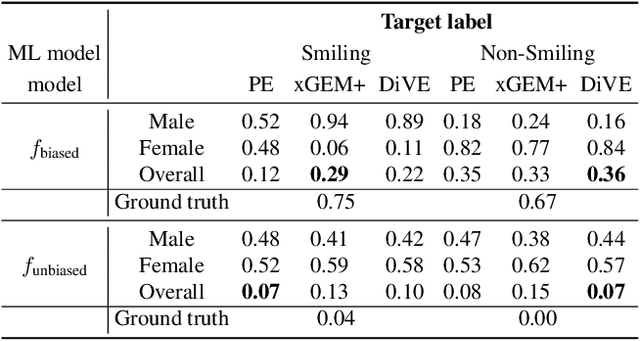

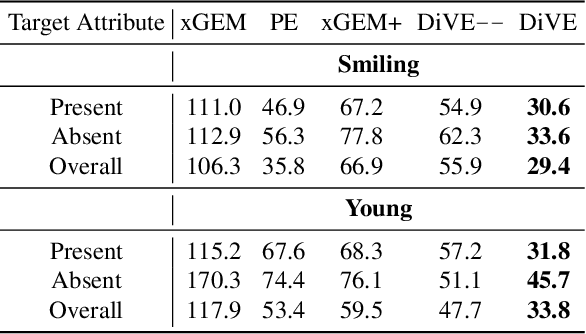
Explainability for machine learning models has gained considerable attention within our research community given the importance of deploying more reliable machine-learning systems. In computer vision applications, generative counterfactual methods indicate how to perturb a model's input to change its prediction, providing details about the model's decision-making. Current counterfactual methods make ambiguous interpretations as they combine multiple biases of the model and the data in a single counterfactual interpretation of the model's decision. Moreover, these methods tend to generate trivial counterfactuals about the model's decision, as they often suggest to exaggerate or remove the presence of the attribute being classified. For the machine learning practitioner, these types of counterfactuals offer little value, since they provide no new information about undesired model or data biases. In this work, we propose a counterfactual method that learns a perturbation in a disentangled latent space that is constrained using a diversity-enforcing loss to uncover multiple valuable explanations about the model's prediction. Further, we introduce a mechanism to prevent the model from producing trivial explanations. Experiments on CelebA and Synbols demonstrate that our model improves the success rate of producing high-quality valuable explanations when compared to previous state-of-the-art methods. We will publish the code.
Knowledge Hypergraph Embedding Meets Relational Algebra
Feb 18, 2021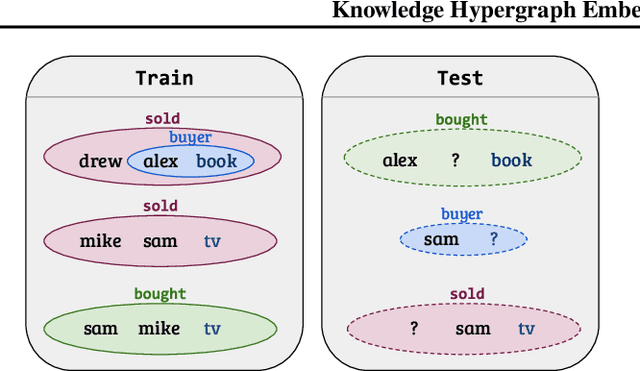
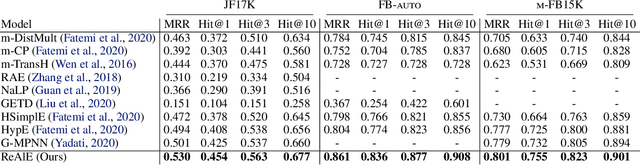
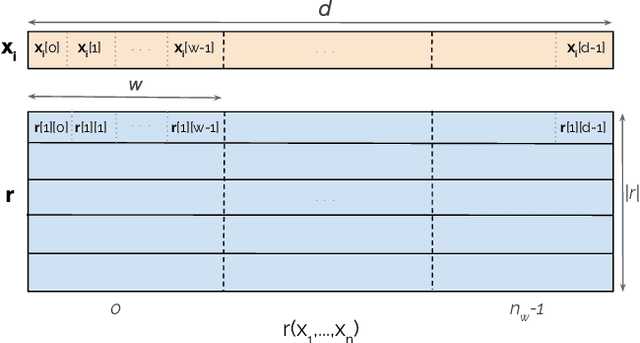

Embedding-based methods for reasoning in knowledge hypergraphs learn a representation for each entity and relation. Current methods do not capture the procedural rules underlying the relations in the graph. We propose a simple embedding-based model called ReAlE that performs link prediction in knowledge hypergraphs (generalized knowledge graphs) and can represent high-level abstractions in terms of relational algebra operations. We show theoretically that ReAlE is fully expressive and provide proofs and empirical evidence that it can represent a large subset of the primitive relational algebra operations, namely renaming, projection, set union, selection, and set difference. We also verify experimentally that ReAlE outperforms state-of-the-art models in knowledge hypergraph completion, and in representing each of these primitive relational algebra operations. For the latter experiment, we generate a synthetic knowledge hypergraph, for which we design an algorithm based on the Erdos-R'enyi model for generating random graphs.