 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaicLeaks:Privacy Risks in Querying-in-the-Open for Deep Research Agents
May 29, 2026Deep research agents increasingly combine private local documents with external tools like web retrieval, creating a privacy risk: an agent's external queries may leak sensitive information from its local context. This risk is amplified by the mosaic effect, where individual queries may appear harmless but become revealing in aggregate. We introduce MosaicLeaks, a benchmark of 1,001 multi-hop deep research tasks that chain private enterprise documents and a public web corpus, forcing agents to make external queries that depend on local information. We evaluate leakage with an adversary LLM that observes only the agent's external queries and attempts to infer private information at three levels: the agent's research intent, answers to specific private questions and verifiable claims about the enterprise documents. We find that models across families and sizes frequently leak at all three levels, that zero-shot privacy prompting reduces but does not eliminate leakage and that reinforcement learning for task performance alone worsens leakage. To address this, we propose Privacy-Aware Deep Research (PA-DR), an RL framework that combines situational rewards for task success with a learned privacy classifier to provide dense credit assignment over both per-query and mosaic-level leakage. Training Qwen3-4B-Instruct with PA-DR improves accuracy from 48.7% to 58.7% and reduces answer and full-information leakage from 34.0% to 9.9%.
Super Apriel: One Checkpoint, Many Speeds
Apr 21, 2026We release Super Apriel, a 15B-parameter supernet in which every decoder layer provides four trained mixer choices -- Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). A placement selects one mixer per layer; placements can be switched between requests at serving time without reloading weights, enabling multiple speed presets from a single checkpoint. The shared checkpoint also enables speculative decoding without a separate draft model. The all-FA preset matches the Apriel 1.6 teacher on all reported benchmarks; recommended hybrid presets span $2.9\times$ to $10.7\times$ decode throughput at 96% to 77% quality retention, with throughput advantages that compound at longer context lengths. With four mixer types across 48 layers, the configuration space is vast. A surrogate that predicts placement quality from the per-layer mixer assignment makes the speed-quality landscape tractable and identifies the best tradeoffs at each speed level. We investigate whether the best configurations at each speed level can be identified early in training or only after convergence. Rankings stabilize quickly at 0.5B scale, but the most efficient configurations exhibit higher instability at 15B, cautioning against extrapolation from smaller models. Super Apriel is trained by stochastic distillation from a frozen Apriel 1.6 teacher, followed by supervised fine-tuning. We release the supernet weights, Fast-LLM training code, vLLM serving code, and a placement optimization toolkit.
Apriel-1.5-OpenReasoner: RL Post-Training for General-Purpose and Efficient Reasoning
Apr 03, 2026Building general-purpose reasoning models using reinforcement learning with verifiable rewards (RLVR) across diverse domains has been widely adopted by frontier open-weight models. However, their training recipes and domain mixtures are often not disclosed. Joint optimization across domains poses significant challenges: domains vary widely in rollout length, problem difficulty and sample efficiency. Further, models with long chain-of-thought traces increase inference cost and latency, making efficiency critical for practical deployment. We present Apriel-1.5-OpenReasoner, trained with a fully reproducible multi-domain RL post-training recipe on Apriel-Base, a 15B-parameter open-weight LLM, across five domains using public datasets: mathematics, code generation, instruction following, logical puzzles and function calling. We introduce an adaptive domain sampling mechanism that preserves target domain ratios despite heterogeneous rollout dynamics, and a difficulty-aware extension of the standard length penalty that, with no additional training overhead, encourages longer reasoning for difficult problems and shorter traces for easy ones. Trained with a strict 16K-token output budget, Apriel-1.5-OpenReasoner generalizes to 32K tokens at inference and improves over Apriel-Base on AIME 2025, GPQA, MMLU-Pro, and LiveCodeBench while producing 30-50% shorter reasoning traces. It matches strong open-weight models of similar size at lower token cost, thereby pushing the Pareto frontier of accuracy versus token budget.
Apriel-Reasoner: RL Post-Training for General-Purpose and Efficient Reasoning
Apr 02, 2026Building general-purpose reasoning models using reinforcement learning with verifiable rewards (RLVR) across diverse domains has been widely adopted by frontier open-weight models. However, their training recipes and domain mixtures are often not disclosed. Joint optimization across domains poses significant challenges: domains vary widely in rollout length, problem difficulty and sample efficiency. Further, models with long chain-of-thought traces increase inference cost and latency, making efficiency critical for practical deployment. We present Apriel-Reasoner, trained with a fully reproducible multi-domain RL post-training recipe on Apriel-Base, a 15B-parameter open-weight LLM, across five domains using public datasets: mathematics, code generation, instruction following, logical puzzles and function calling. We introduce an adaptive domain sampling mechanism that preserves target domain ratios despite heterogeneous rollout dynamics, and a difficulty-aware extension of the standard length penalty that, with no additional training overhead, encourages longer reasoning for difficult problems and shorter traces for easy ones. Trained with a strict 16K-token output budget, Apriel-Reasoner generalizes to 32K tokens at inference and improves over Apriel-Base on AIME 2025, GPQA, MMLU-Pro, and LiveCodeBench while producing 30-50% shorter reasoning traces. It matches strong open-weight models of similar size at lower token cost, thereby pushing the Pareto frontier of accuracy versus token budget.
TapeAgents: a Holistic Framework for Agent Development and Optimization
Dec 11, 2024



We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session's resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent's actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent's LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents's advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text -- a unique combination of features absent in previous work.
LOOC: Localize Overlapping Objects with Count Supervision
Jul 03, 2020
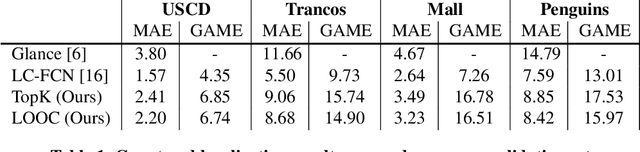
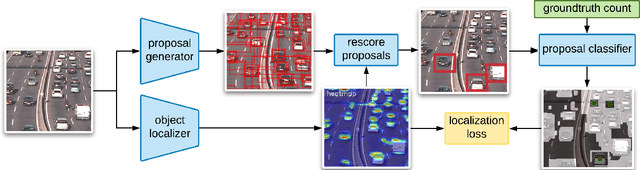

Acquiring count annotations generally requires less human effort than point-level and bounding box annotations. Thus, we propose the novel problem setup of localizing objects in dense scenes under this weaker supervision. We propose LOOC, a method to Localize Overlapping Objects with Count supervision. We train LOOC by alternating between two stages. In the first stage, LOOC learns to generate pseudo point-level annotations in a semi-supervised manner. In the second stage, LOOC uses a fully-supervised localization method that trains on these pseudo labels. The localization method is used to progressively improve the quality of the pseudo labels. We conducted experiments on popular counting datasets. For localization, LOOC achieves a strong new baseline in the novel problem setup where only count supervision is available. For counting, LOOC outperforms current state-of-the-art methods that only use count as their supervision. Code is available at: https://github.com/ElementAI/looc.
Objects of violence: synthetic data for practical ML in human rights investigations
Apr 01, 2020
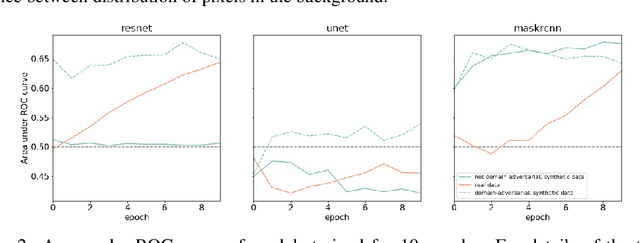


We introduce a machine learning workflow to search for, identify, and meaningfully triage videos and images of munitions, weapons, and military equipment, even when limited training data exists for the object of interest. This workflow is designed to expedite the work of OSINT ("open source intelligence") researchers in human rights investigations. It consists of three components: automatic rendering and annotating of synthetic datasets that make up for a lack of training data; training image classifiers from combined sets of photographic and synthetic data; and mtriage, an open source software that orchestrates these classifiers' deployment to triage public domain media, and visualise predictions in a web interface. We show that synthetic data helps to train classifiers more effectively, and that certain approaches yield better results for different architectures. We then demonstrate our workflow in two real-world human rights investigations: the use of the Triple-Chaser tear gas grenade against civilians, and the verification of allegations of military presence in Ukraine in 2014.