 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustly Extracting Medical Knowledge from EHRs: A Case Study of Learning a Health Knowledge Graph
Oct 02, 2019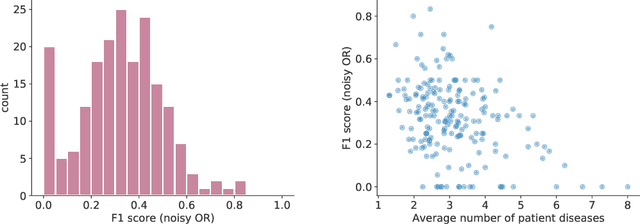
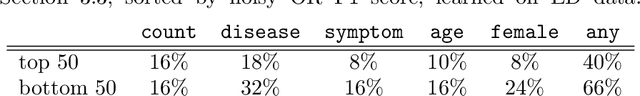
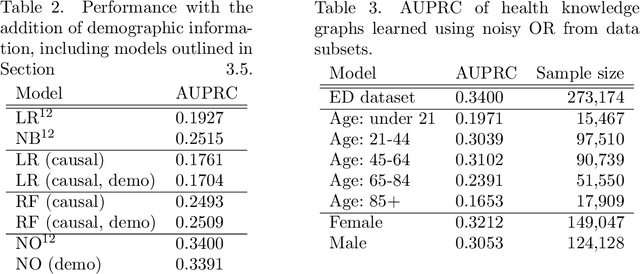
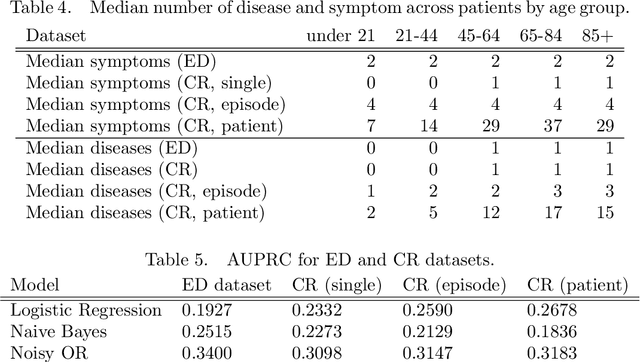
Increasingly large electronic health records (EHRs) provide an opportunity to algorithmically learn medical knowledge. In one prominent example, a causal health knowledge graph could learn relationships between diseases and symptoms and then serve as a diagnostic tool to be refined with additional clinical input. Prior research has demonstrated the ability to construct such a graph from over 270,000 emergency department patient visits. In this work, we describe methods to evaluate a health knowledge graph for robustness. Moving beyond precision and recall, we analyze for which diseases and for which patients the graph is most accurate. We identify sample size and unmeasured confounders as major sources of error in the health knowledge graph. We introduce a method to leverage non-linear functions in building the causal graph to better understand existing model assumptions. Finally, to assess model generalizability, we extend to a larger set of complete patient visits within a hospital system. We conclude with a discussion on how to robustly extract medical knowledge from EHRs.
Characterization of Overlap in Observational Studies
Jul 09, 2019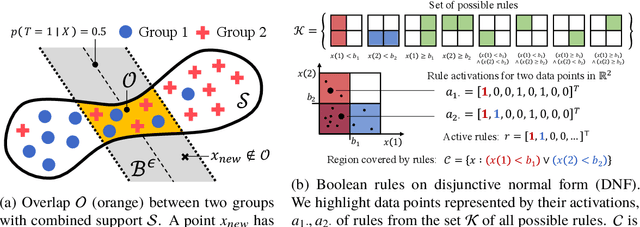
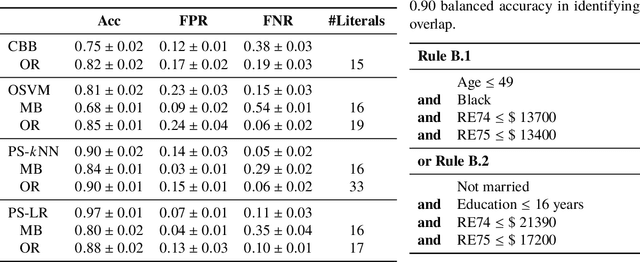
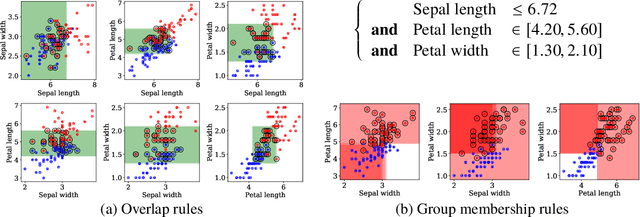

Overlap between treatment groups is required for nonparametric estimation of causal effects. If a subgroup of subjects always receives (or never receives) a given intervention, we cannot estimate the effect of intervention changes on that subgroup without further assumptions. When overlap does not hold globally, characterizing local regions of overlap can inform the relevance of any causal conclusions for new subjects, and can help guide additional data collection. To have impact, these descriptions must be interpretable for downstream users who are not machine learning experts, such as clinicians. We formalize overlap estimation as a problem of finding minimum volume sets and give a method to solve it by reduction to binary classification with Boolean rules. We also generalize our method to estimate overlap in off-policy policy evaluation. Using data from real-world applications, we demonstrate that these rules have comparable accuracy to black-box estimators while maintaining a simple description. In one case study, we perform a user study with clinicians to evaluate rules learned to describe treatment group overlap in post-surgical opioid prescriptions. In another, we estimate overlap in policy evaluation of antibiotic prescription for urinary tract infections.
Benefits of Overparameterization in Single-Layer Latent Variable Generative Models
Jun 28, 2019
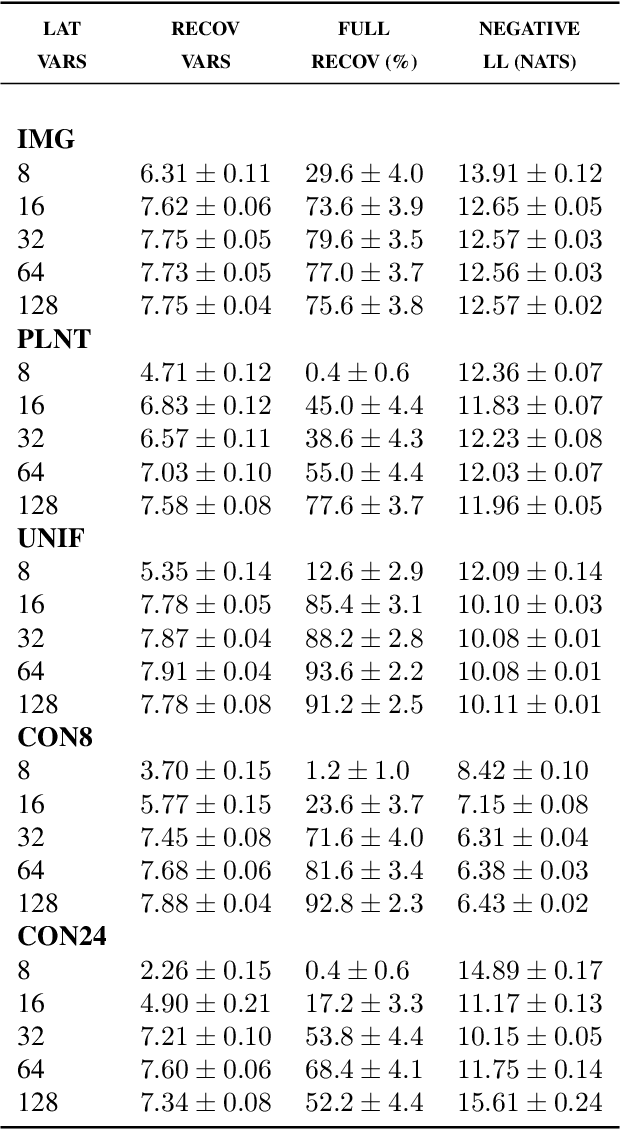
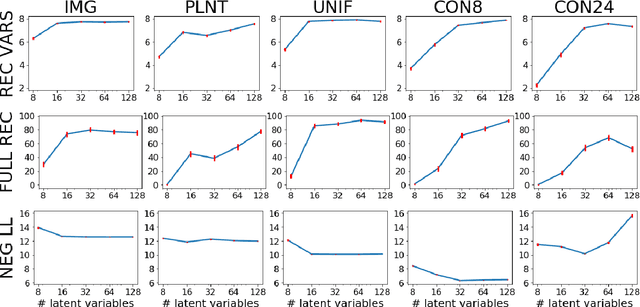
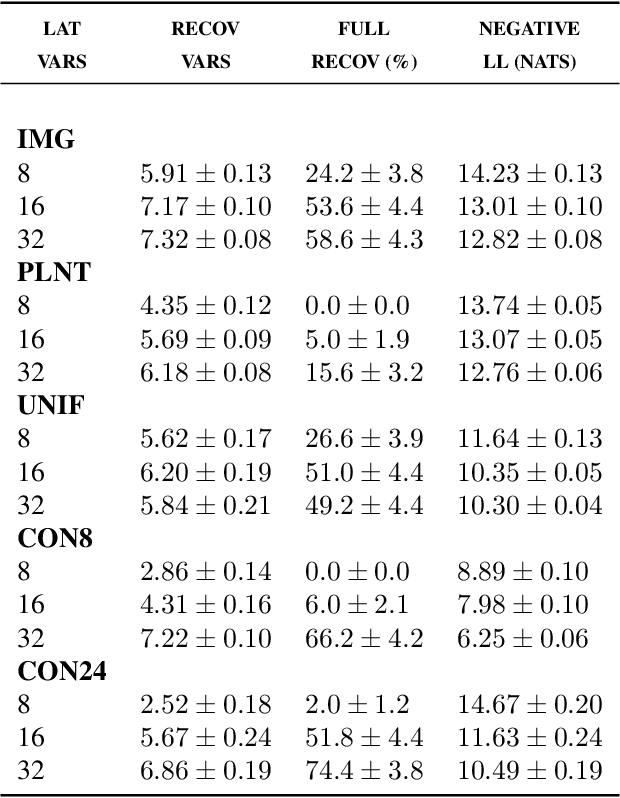
One of the most surprising and exciting discoveries in supervising learning was the benefit of overparametrization (i.e. training a very large model) to improving the optimization landscape of a problem, with minimal effect on statistical performance (i.e. generalization). In contrast, unsupervised settings have been under-explored, despite the fact that it has been observed that overparameterization can be helpful as early as Dasgupta & Schulman (2007). In this paper, we perform an exhaustive study of different aspects of overparameterization in unsupervised learning via synthetic and semi-synthetic experiments. We discuss benefits to different metrics of success (held-out log-likelihood, recovering the parameters of the ground-truth model), sensitivity to variations of the training algorithm, and behavior as the amount of overparameterization increases. We find that, when learning using methods such as variational inference, larger models can significantly increase the number of ground truth latent variables recovered.
Counterfactual Off-Policy Evaluation with Gumbel-Max Structural Causal Models
May 17, 2019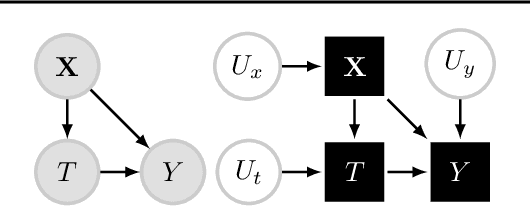
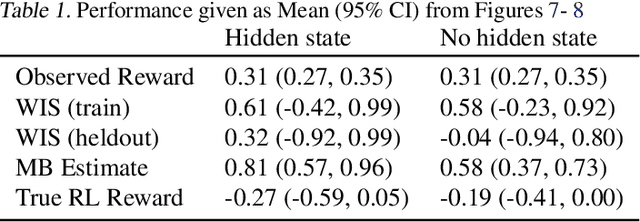
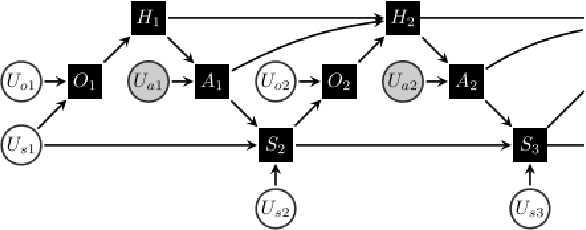
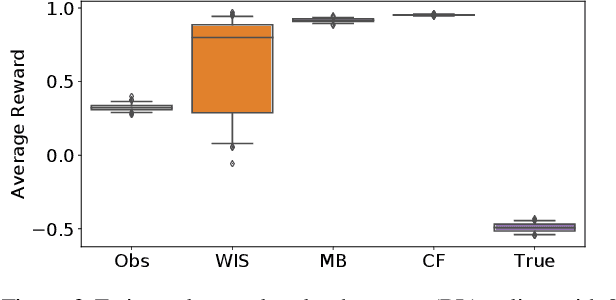
We introduce an off-policy evaluation procedure for highlighting episodes where applying a reinforcement learned (RL) policy is likely to have produced a substantially different outcome than the observed policy. In particular, we introduce a class of structural causal models (SCMs) for generating counterfactual trajectories in finite partially observable Markov Decision Processes (POMDPs). We see this as a useful procedure for off-policy "debugging" in high-risk settings (e.g., healthcare); by decomposing the expected difference in reward between the RL and observed policy into specific episodes, we can identify episodes where the counterfactual difference in reward is most dramatic. This in turn can be used to facilitate review of specific episodes by domain experts. We demonstrate the utility of this procedure with a synthetic environment of sepsis management.
Support and Invertibility in Domain-Invariant Representations
Mar 21, 2019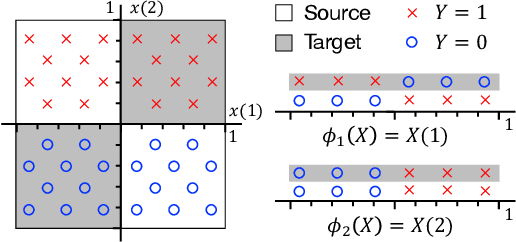
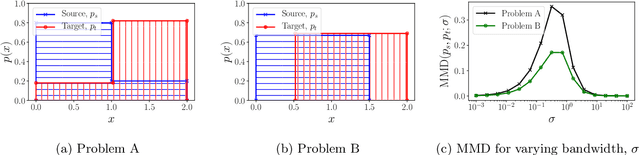

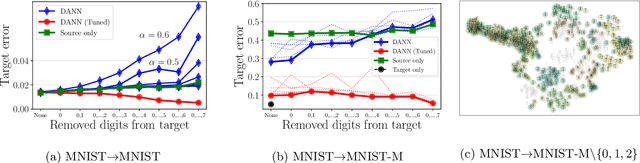
Learning domain-invariant representations has become a popular approach to unsupervised domain adaptation and is often justified by invoking a particular suite of theoretical results. We argue that there are two significant flaws in such arguments. First, the results in question hold only for a fixed representation and do not account for information lost in non-invertible transformations. Second, domain invariance is often a far too strict requirement and does not always lead to consistent estimation, even under strong and favorable assumptions. In this work, we give generalization bounds for unsupervised domain adaptation that hold for any representation function by acknowledging the cost of non-invertibility. In addition, we show that penalizing distance between densities is often wasteful and propose a bound based on measuring the extent to which the support of the source domain covers the target domain. We perform experiments on well-known benchmarks that illustrate the short-comings of current standard practice.
Overcomplete Independent Component Analysis via SDP
Jan 24, 2019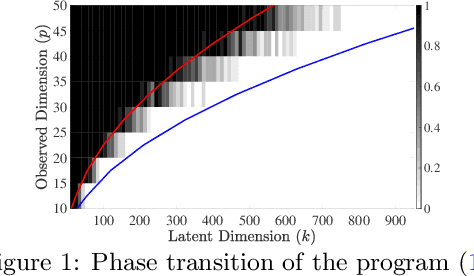
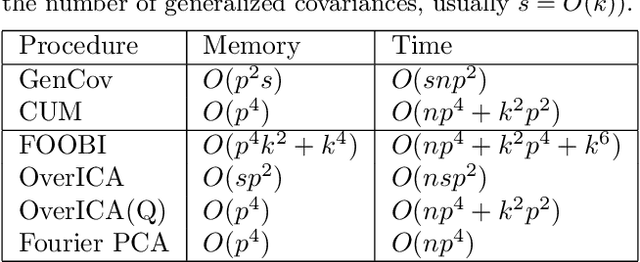
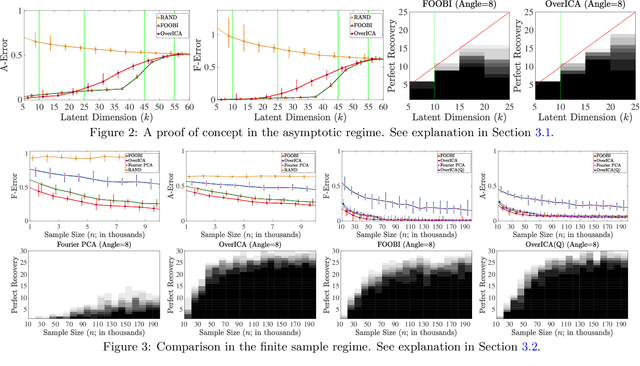

We present a novel algorithm for overcomplete independent components analysis (ICA), where the number of latent sources k exceeds the dimension p of observed variables. Previous algorithms either suffer from high computational complexity or make strong assumptions about the form of the mixing matrix. Our algorithm does not make any sparsity assumption yet enjoys favorable computational and theoretical properties. Our algorithm consists of two main steps: (a) estimation of the Hessians of the cumulant generating function (as opposed to the fourth and higher order cumulants used by most algorithms) and (b) a novel semi-definite programming (SDP) relaxation for recovering a mixing component. We show that this relaxation can be efficiently solved with a projected accelerated gradient descent method, which makes the whole algorithm computationally practical. Moreover, we conjecture that the proposed program recovers a mixing component at the rate k < p^2/4 and prove that a mixing component can be recovered with high probability when k < (2 - epsilon) p log p when the original components are sampled uniformly at random on the hyper sphere. Experiments are provided on synthetic data and the CIFAR-10 dataset of real images.
Prototypical Clustering Networks for Dermatological Disease Diagnosis
Nov 07, 2018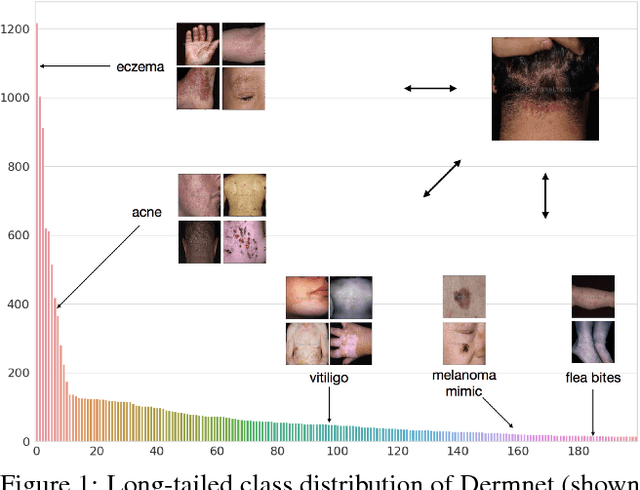
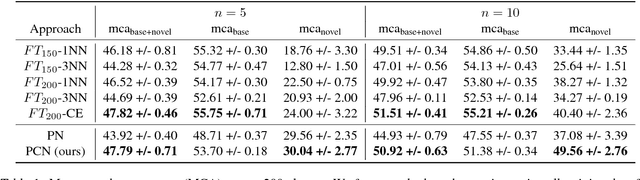
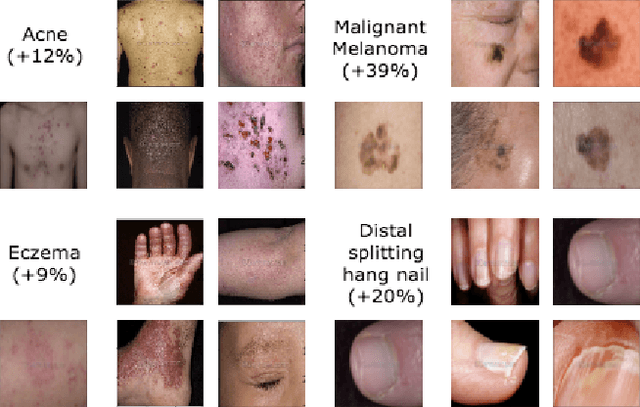
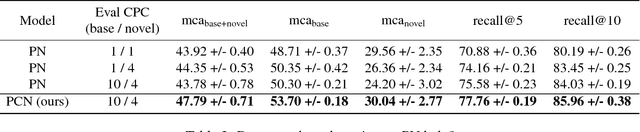
We consider the problem of image classification for the purpose of aiding doctors in dermatological diagnosis. Dermatological diagnosis poses two major challenges for standard off-the-shelf techniques: First, the data distribution is typically extremely long tailed. Second, intra-class variability is often large. To address the first issue, we formulate the problem as low-shot learning, where once deployed, a base classifier must rapidly generalize to diagnose novel conditions given very few labeled examples. To model diverse classes effectively, we propose Prototypical Clustering Networks (PCN), an extension to Prototypical Networks that learns a mixture of prototypes for each class. Prototypes are initialized for each class via clustering and refined via an online update scheme. Classification is performed by measuring similarity to a weighted combination of prototypes within a class, where the weights are the inferred cluster responsibilities. We demonstrate the strengths of our approach in effective diagnosis on a realistic dataset of dermatological conditions.
Block Stability for MAP Inference
Oct 12, 2018
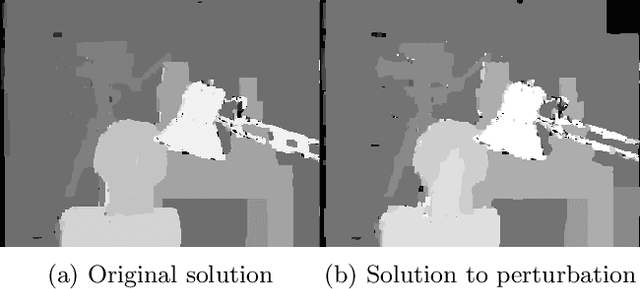
To understand the empirical success of approximate MAP inference, recent work (Lang et al., 2018) has shown that some popular approximation algorithms perform very well when the input instance is stable. The simplest stability condition assumes that the MAP solution does not change at all when some of the pairwise potentials are (adversarially) perturbed. Unfortunately, this strong condition does not seem to be satisfied in practice. In this paper, we introduce a significantly more relaxed condition that only requires blocks (portions) of an input instance to be stable. Under this block stability condition, we prove that the pairwise LP relaxation is persistent on the stable blocks. We complement our theoretical results with an empirical evaluation of real-world MAP inference instances from computer vision. We design an algorithm to find stable blocks, and find that these real instances have large stable regions. Our work gives a theoretical explanation for the widespread empirical phenomenon of persistency for this LP relaxation.
Semi-Amortized Variational Autoencoders
Jul 23, 2018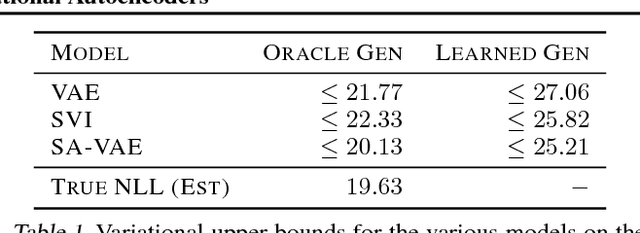
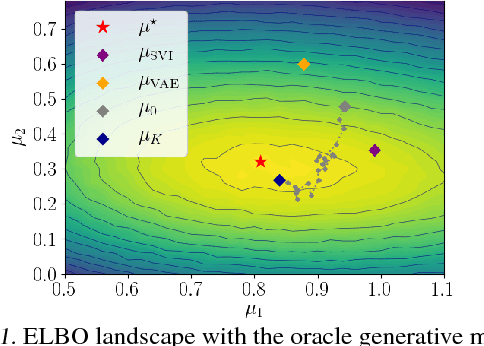
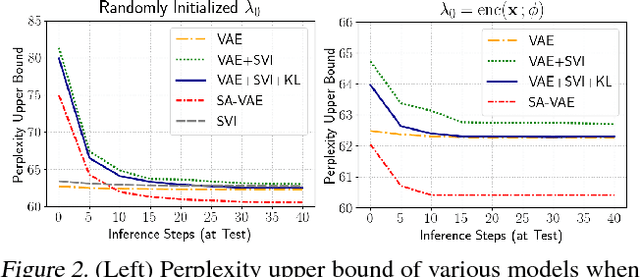
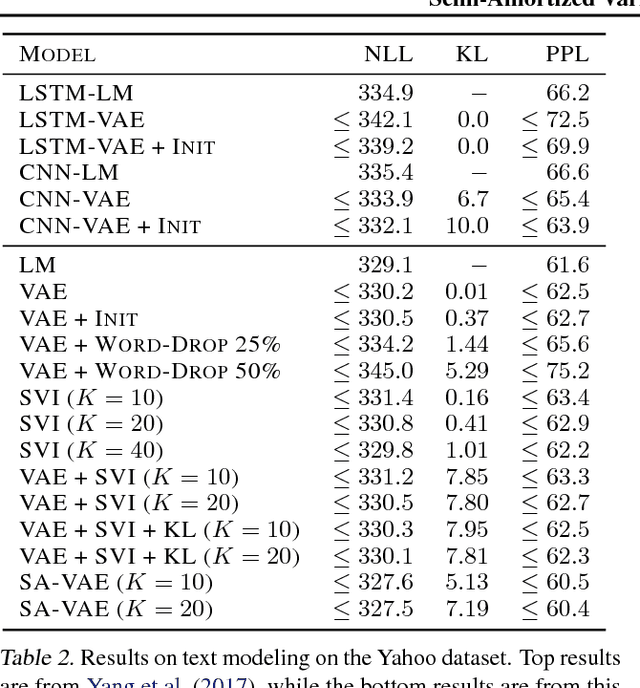
Amortized variational inference (AVI) replaces instance-specific local inference with a global inference network. While AVI has enabled efficient training of deep generative models such as variational autoencoders (VAE), recent empirical work suggests that inference networks can produce suboptimal variational parameters. We propose a hybrid approach, to use AVI to initialize the variational parameters and run stochastic variational inference (SVI) to refine them. Crucially, the local SVI procedure is itself differentiable, so the inference network and generative model can be trained end-to-end with gradient-based optimization. This semi-amortized approach enables the use of rich generative models without experiencing the posterior-collapse phenomenon common in training VAEs for problems like text generation. Experiments show this approach outperforms strong autoregressive and variational baselines on standard text and image datasets.
Learning Representations for Counterfactual Inference
Jun 06, 2018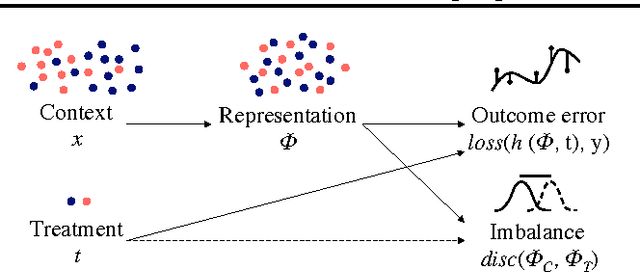
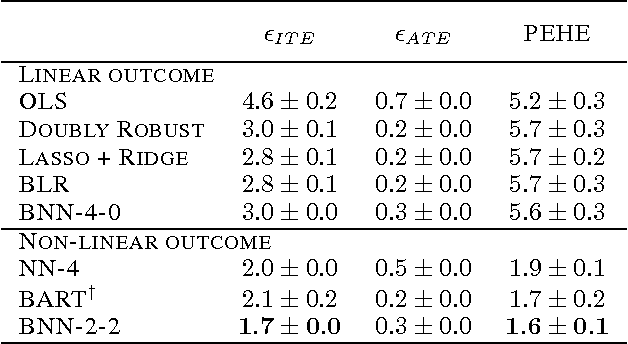
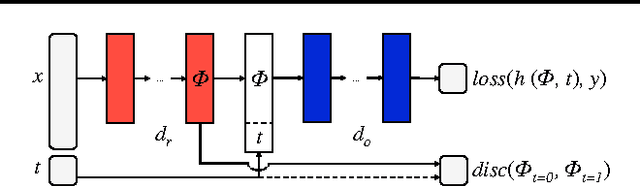
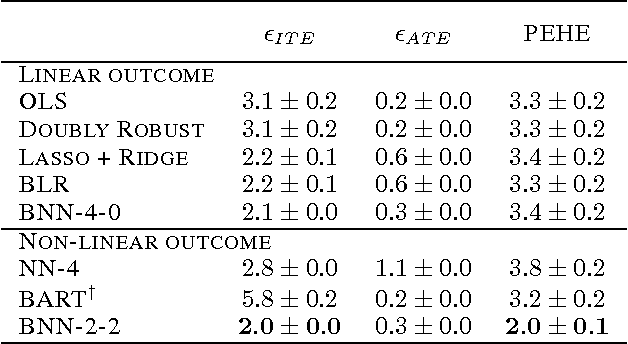
Observational studies are rising in importance due to the widespread accumulation of data in fields such as healthcare, education, employment and ecology. We consider the task of answering counterfactual questions such as, "Would this patient have lower blood sugar had she received a different medication?". We propose a new algorithmic framework for counterfactual inference which brings together ideas from domain adaptation and representation learning. In addition to a theoretical justification, we perform an empirical comparison with previous approaches to causal inference from observational data. Our deep learning algorithm significantly outperforms the previous state-of-the-art.