 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025



In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
Privacy-Preserving Dataset Combination
Feb 09, 2025



Access to diverse, high-quality datasets is crucial for machine learning model performance, yet data sharing remains limited by privacy concerns and competitive interests, particularly in regulated domains like healthcare. This dynamic especially disadvantages smaller organizations that lack resources to purchase data or negotiate favorable sharing agreements. We present SecureKL, a privacy-preserving framework that enables organizations to identify beneficial data partnerships without exposing sensitive information. Building on recent advances in dataset combination methods, we develop a secure multiparty computation protocol that maintains strong privacy guarantees while achieving >90\% correlation with plaintext evaluations. In experiments with real-world hospital data, SecureKL successfully identifies beneficial data partnerships that improve model performance for intensive care unit mortality prediction while preserving data privacy. Our framework provides a practical solution for organizations seeking to leverage collective data resources while maintaining privacy and competitive advantages. These results demonstrate the potential for privacy-preserving data collaboration to advance machine learning applications in high-stakes domains while promoting more equitable access to data resources.
Machine Learning for Health (ML4H) Workshop at NeurIPS 2018
Nov 24, 2018This volume represents the accepted submissions from the Machine Learning for Health (ML4H) workshop at the conference on Neural Information Processing Systems (NeurIPS) 2018, held on December 8, 2018 in Montreal, Canada.
Why Is My Classifier Discriminatory?
May 30, 2018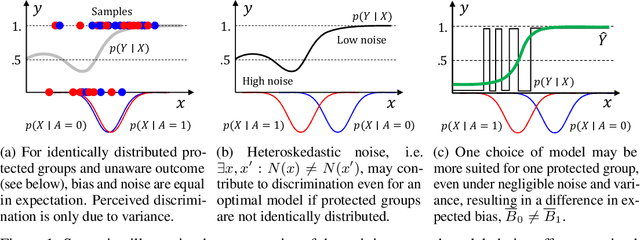
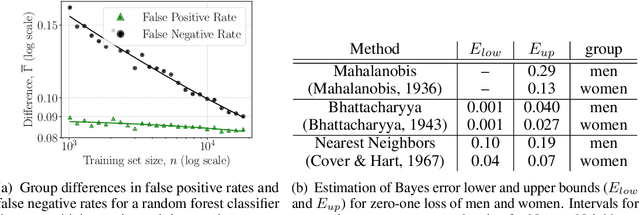
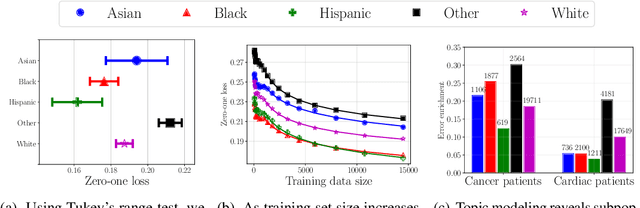
Recent attempts to achieve fairness in predictive models focus on the balance between fairness and accuracy. In sensitive applications such as healthcare or criminal justice, this trade-off is often undesirable as any increase in prediction error could have devastating consequences. In this work, we argue that the fairness of predictions should be evaluated in context of the data, and that unfairness induced by inadequate samples sizes or unmeasured predictive variables should be addressed through data collection, rather than by constraining the model. We decompose cost-based metrics of discrimination into bias, variance, and noise, and propose actions aimed at estimating and reducing each term. Finally, we perform case-studies on prediction of income, mortality, and review ratings, confirming the value of this analysis. We find that data collection is often a means to reduce discrimination without sacrificing accuracy.