 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObeying the Order: Introducing Ordered Transfer Hyperparameter Optimisation
Jun 29, 2023We introduce ordered transfer hyperparameter optimisation (OTHPO), a version of transfer learning for hyperparameter optimisation (HPO) where the tasks follow a sequential order. Unlike for state-of-the-art transfer HPO, the assumption is that each task is most correlated to those immediately before it. This matches many deployed settings, where hyperparameters are retuned as more data is collected; for instance tuning a sequence of movie recommendation systems as more movies and ratings are added. We propose a formal definition, outline the differences to related problems and propose a basic OTHPO method that outperforms state-of-the-art transfer HPO. We empirically show the importance of taking order into account using ten benchmarks. The benchmarks are in the setting of gradually accumulating data, and span XGBoost, random forest, approximate k-nearest neighbor, elastic net, support vector machines and a separate real-world motivated optimisation problem. We open source the benchmarks to foster future research on ordered transfer HPO.
Optimizing Hyperparameters with Conformal Quantile Regression
May 05, 2023Many state-of-the-art hyperparameter optimization (HPO) algorithms rely on model-based optimizers that learn surrogate models of the target function to guide the search. Gaussian processes are the de facto surrogate model due to their ability to capture uncertainty but they make strong assumptions about the observation noise, which might not be warranted in practice. In this work, we propose to leverage conformalized quantile regression which makes minimal assumptions about the observation noise and, as a result, models the target function in a more realistic and robust fashion which translates to quicker HPO convergence on empirical benchmarks. To apply our method in a multi-fidelity setting, we propose a simple, yet effective, technique that aggregates observed results across different resource levels and outperforms conventional methods across many empirical tasks.
Criteria for Classifying Forecasting Methods
Dec 07, 2022


Classifying forecasting methods as being either of a "machine learning" or "statistical" nature has become commonplace in parts of the forecasting literature and community, as exemplified by the M4 competition and the conclusion drawn by the organizers. We argue that this distinction does not stem from fundamental differences in the methods assigned to either class. Instead, this distinction is probably of a tribal nature, which limits the insights into the appropriateness and effectiveness of different forecasting methods. We provide alternative characteristics of forecasting methods which, in our view, allow to draw meaningful conclusions. Further, we discuss areas of forecasting which could benefit most from cross-pollination between the ML and the statistics communities.
Multi-Objective Model Selection for Time Series Forecasting
Feb 17, 2022



Research on time series forecasting has predominantly focused on developing methods that improve accuracy. However, other criteria such as training time or latency are critical in many real-world applications. We therefore address the question of how to choose an appropriate forecasting model for a given dataset among the plethora of available forecasting methods when accuracy is only one of many criteria. For this, our contributions are two-fold. First, we present a comprehensive benchmark, evaluating 7 classical and 6 deep learning forecasting methods on 44 heterogeneous, publicly available datasets. The benchmark code is open-sourced along with evaluations and forecasts for all methods. These evaluations enable us to answer open questions such as the amount of data required for deep learning models to outperform classical ones. Second, we leverage the benchmark evaluations to learn good defaults that consider multiple objectives such as accuracy and latency. By learning a mapping from forecasting models to performance metrics, we show that our method PARETOSELECT is able to accurately select models from the Pareto front -- alleviating the need to train or evaluate many forecasting models for model selection. To the best of our knowledge, PARETOSELECT constitutes the first method to learn default models in a multi-objective setting.
Meta-Forecasting by combining Global Deep Representations with Local Adaptation
Nov 12, 2021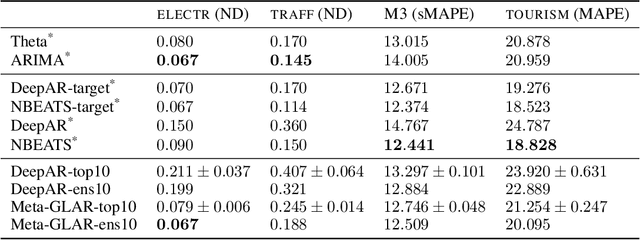
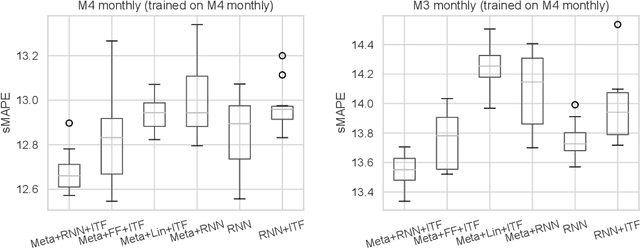
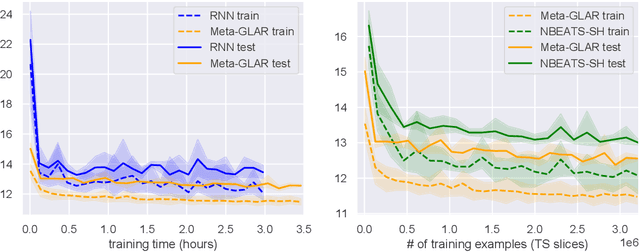

While classical time series forecasting considers individual time series in isolation, recent advances based on deep learning showed that jointly learning from a large pool of related time series can boost the forecasting accuracy. However, the accuracy of these methods suffers greatly when modeling out-of-sample time series, significantly limiting their applicability compared to classical forecasting methods. To bridge this gap, we adopt a meta-learning view of the time series forecasting problem. We introduce a novel forecasting method, called Meta Global-Local Auto-Regression (Meta-GLAR), that adapts to each time series by learning in closed-form the mapping from the representations produced by a recurrent neural network (RNN) to one-step-ahead forecasts. Crucially, the parameters ofthe RNN are learned across multiple time series by backpropagating through the closed-form adaptation mechanism. In our extensive empirical evaluation we show that our method is competitive with the state-of-the-art in out-of-sample forecasting accuracy reported in earlier work.
Multi-objective Asynchronous Successive Halving
Jun 23, 2021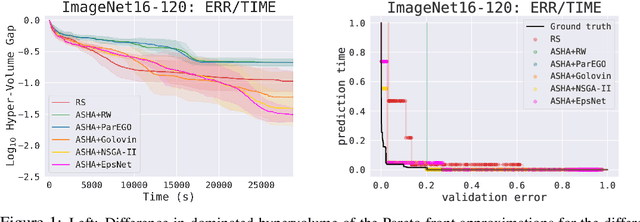

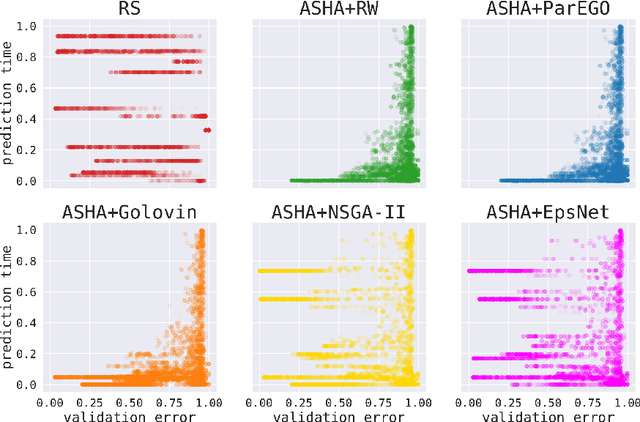

Hyperparameter optimization (HPO) is increasingly used to automatically tune the predictive performance (e.g., accuracy) of machine learning models. However, in a plethora of real-world applications, accuracy is only one of the multiple -- often conflicting -- performance criteria, necessitating the adoption of a multi-objective (MO) perspective. While the literature on MO optimization is rich, few prior studies have focused on HPO. In this paper, we propose algorithms that extend asynchronous successive halving (ASHA) to the MO setting. Considering multiple evaluation metrics, we assess the performance of these methods on three real world tasks: (i) Neural architecture search, (ii) algorithmic fairness and (iii) language model optimization. Our empirical analysis shows that MO ASHA enables to perform MO HPO at scale. Further, we observe that that taking the entire Pareto front into account for candidate selection consistently outperforms multi-fidelity HPO based on MO scalarization in terms of wall-clock time. Our algorithms (to be open-sourced) establish new baselines for future research in the area.
A multi-objective perspective on jointly tuning hardware and hyperparameters
Jun 10, 2021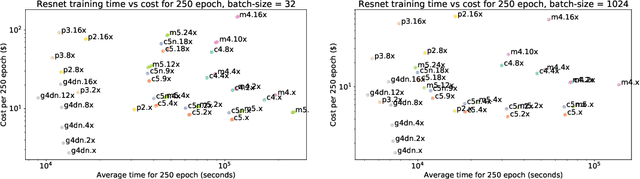
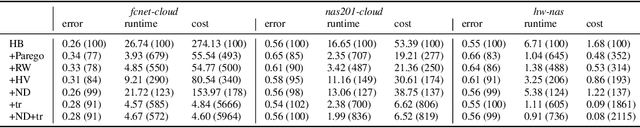
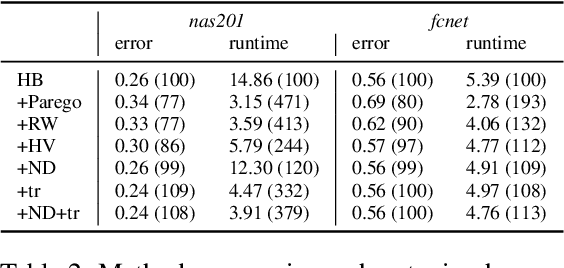
In addition to the best model architecture and hyperparameters, a full AutoML solution requires selecting appropriate hardware automatically. This can be framed as a multi-objective optimization problem: there is not a single best hardware configuration but a set of optimal ones achieving different trade-offs between cost and runtime. In practice, some choices may be overly costly or take days to train. To lift this burden, we adopt a multi-objective approach that selects and adapts the hardware configuration automatically alongside neural architectures and their hyperparameters. Our method builds on Hyperband and extends it in two ways. First, we replace the stopping rule used in Hyperband by a non-dominated sorting rule to preemptively stop unpromising configurations. Second, we leverage hyperparameter evaluations from related tasks via transfer learning by building a probabilistic estimate of the Pareto front that finds promising configurations more efficiently than random search. We show in extensive NAS and HPO experiments that both ingredients bring significant speed-ups and cost savings, with little to no impact on accuracy. In three benchmarks where hardware is selected in addition to hyperparameters, we obtain runtime and cost reductions of at least 5.8x and 8.8x, respectively. Furthermore, when applying our multi-objective method to the tuning of hyperparameters only, we obtain a 10\% improvement in runtime while maintaining the same accuracy on two popular NAS benchmarks.
A resource-efficient method for repeated HPO and NAS problems
Mar 30, 2021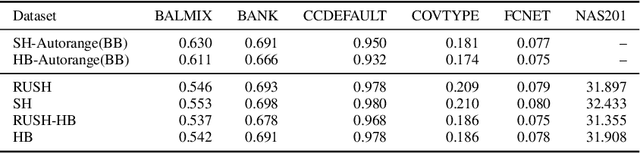
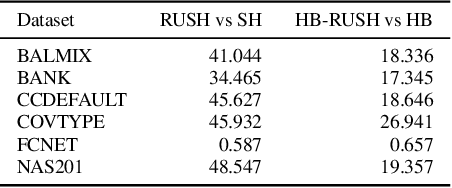
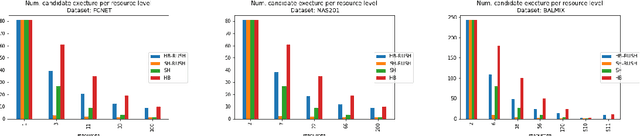
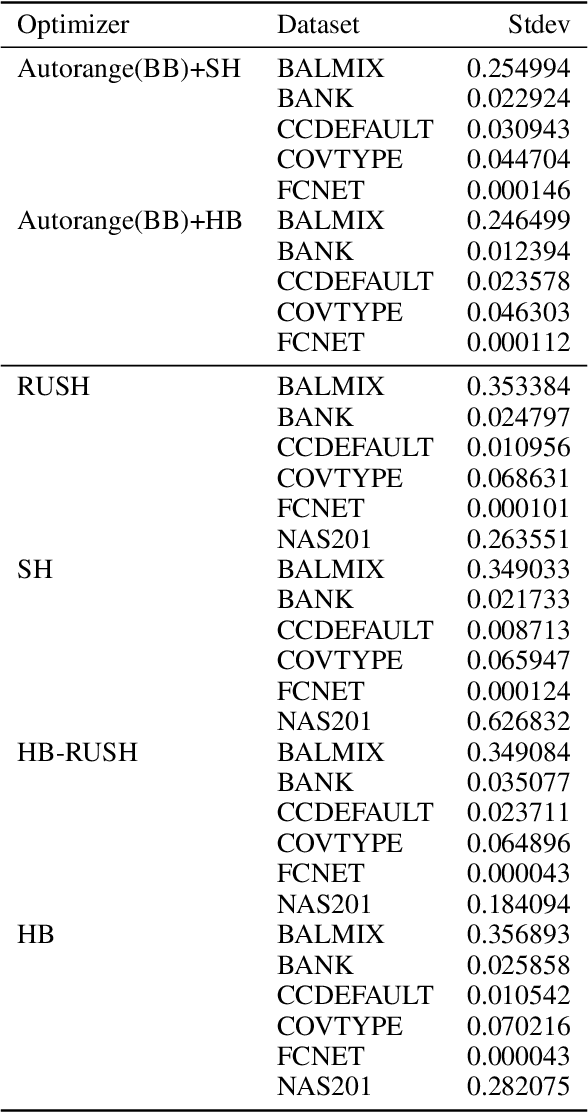
In this work we consider the problem of repeated hyperparameter and neural architecture search (HNAS). We propose an extension of Successive Halving that is able to leverage information gained in previous HNAS problems with the goal of saving computational resources. We empirically demonstrate that our solution is able to drastically decrease costs while maintaining accuracy and being robust to negative transfer. Our method is significantly simpler than competing transfer learning approaches, setting a new baseline for transfer learning in HNAS.
The Effectiveness of Discretization in Forecasting: An Empirical Study on Neural Time Series Models
May 20, 2020
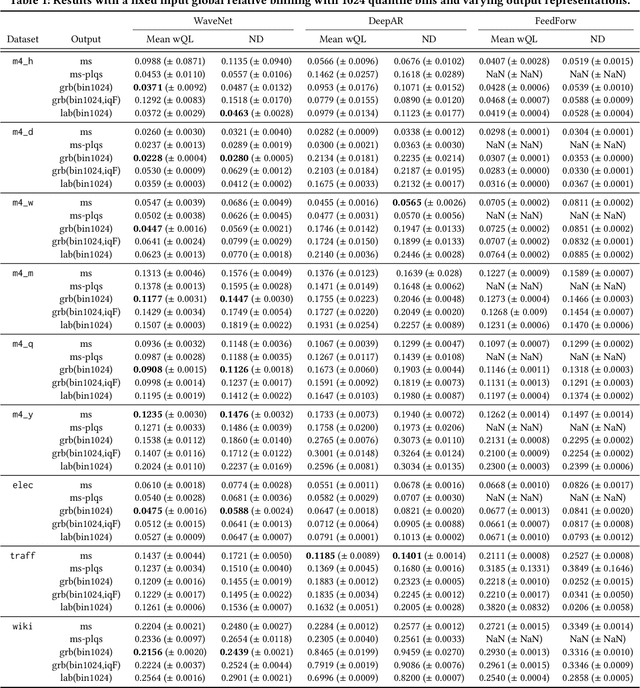
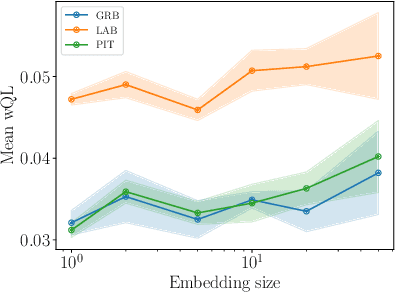
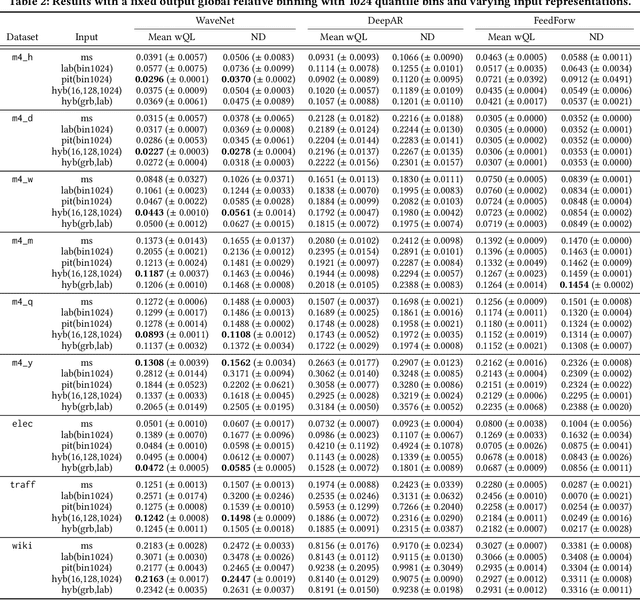
Time series modeling techniques based on deep learning have seen many advancements in recent years, especially in data-abundant settings and with the central aim of learning global models that can extract patterns across multiple time series. While the crucial importance of appropriate data pre-processing and scaling has often been noted in prior work, most studies focus on improving model architectures. In this paper we empirically investigate the effect of data input and output transformations on the predictive performance of several neural forecasting architectures. In particular, we investigate the effectiveness of several forms of data binning, i.e. converting real-valued time series into categorical ones, when combined with feed-forward, recurrent neural networks, and convolution-based sequence models. In many non-forecasting applications where these models have been very successful, the model inputs and outputs are categorical (e.g. words from a fixed vocabulary in natural language processing applications or quantized pixel color intensities in computer vision). For forecasting applications, where the time series are typically real-valued, various ad-hoc data transformations have been proposed, but have not been systematically compared. To remedy this, we evaluate the forecasting accuracy of instances of the aforementioned model classes when combined with different types of data scaling and binning. We find that binning almost always improves performance (compared to using normalized real-valued inputs), but that the particular type of binning chosen is of lesser importance.
Neural forecasting: Introduction and literature overview
Apr 21, 2020


Neural network based forecasting methods have become ubiquitous in large-scale industrial forecasting applications over the last years. As the prevalence of neural network based solutions among the best entries in the recent M4 competition shows, the recent popularity of neural forecasting methods is not limited to industry and has also reached academia. This article aims at providing an introduction and an overview of some of the advances that have permitted the resurgence of neural networks in machine learning. Building on these foundations, the article then gives an overview of the recent literature on neural networks for forecasting and applications.