 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer attentive probing improves transfer of audio representations for bioacoustics
May 11, 2026Probing heads map the representations learned from audio by a machine learning model to downstream task labels and are a key component in evaluating representation learning. Most bioacoustic benchmarks use a fixed, low-capacity probe, such as a linear layer on the final encoder layer. While this standardization enables model comparisons, it may bias results by overlooking the interaction between encoder features and probe design. In this work, we systematically study different probing strategies across two bioacoustic benchmarks, BEANs and BirdSet. We evaluate last- and multi-layer probing, across linear and attention probes. We show that larger probe heads that leverage time information have superior performance. Our results suggest that current benchmarks may misrepresent encoder quality when relying on a last-layer probing setup. Multi-layer probing improves downstream task performance across all tested models, while attention probing has superior performance to linear probing for transformer models.
Enhancing Box and Block Test with Computer Vision for Post-Stroke Upper Extremity Motor Evaluation
Mar 31, 2026Standard clinical assessments of upper-extremity motor function after stroke either rely on ordinal scoring, which lacks sensitivity, or time-based task metrics, which do not capture movement quality. In this work, we present a computer vision-based framework for analysis of upper-extremity movement during the Box and Block Test (BBT) through world-aligned joint angles of fingers, arm, and trunk without depth sensors or calibration objects. We apply this framework to a dataset of 136 BBT recordings collected from 48 healthy individuals and 7 individuals post stroke. Using unsupervised dimensionality reduction of joint-angle features, we analyze movement patterns without relying on expert clinical labels. The resulting embeddings show separation between healthy movement patterns and stroke-related movement deviations. Importantly, some patients with the same BBT scores can be separated with different postural patterns. These results show that world-aligned joint angles can capture meaningful information of upper-extremity functions beyond standard time-based BBT scores, with no effort from the clinician other than monocular video recordings of the patient using a phone or camera. This work highlights the potential of a camera-based, calibration-free framework to measure movement quality in clinical assessments without changing the widely adopted clinical routine.
Audio-to-Image Bird Species Retrieval without Audio-Image Pairs via Text Distillation
Jan 31, 2026Audio-to-image retrieval offers an interpretable alternative to audio-only classification for bioacoustic species recognition, but learning aligned audio-image representations is challenging due to the scarcity of paired audio-image data. We propose a simple and data-efficient approach that enables audio-to-image retrieval without any audio-image supervision. Our proposed method uses text as a semantic intermediary: we distill the text embedding space of a pretrained image-text model (BioCLIP-2), which encodes rich visual and taxonomic structure, into a pretrained audio-text model (BioLingual) by fine-tuning its audio encoder with a contrastive objective. This distillation transfers visually grounded semantics into the audio representation, inducing emergent alignment between audio and image embeddings without using images during training. We evaluate the resulting model on multiple bioacoustic benchmarks. The distilled audio encoder preserves audio discriminative power while substantially improving audio-text alignment on focal recordings and soundscape datasets. Most importantly, on the SSW60 benchmark, the proposed approach achieves strong audio-to-image retrieval performance exceeding baselines based on zero-shot model combinations or learned mappings between text embeddings, despite not training on paired audio-image data. These results demonstrate that indirect semantic transfer through text is sufficient to induce meaningful audio-image alignment, providing a practical solution for visually grounded species recognition in data-scarce bioacoustic settings.
Compact Hypercube Embeddings for Fast Text-based Wildlife Observation Retrieval
Jan 30, 2026Large-scale biodiversity monitoring platforms increasingly rely on multimodal wildlife observations. While recent foundation models enable rich semantic representations across vision, audio, and language, retrieving relevant observations from massive archives remains challenging due to the computational cost of high-dimensional similarity search. In this work, we introduce compact hypercube embeddings for fast text-based wildlife observation retrieval, a framework that enables efficient text-based search over large-scale wildlife image and audio databases using compact binary representations. Building on the cross-view code alignment hashing framework, we extend lightweight hashing beyond a single-modality setup to align natural language descriptions with visual or acoustic observations in a shared Hamming space. Our approach leverages pretrained wildlife foundation models, including BioCLIP and BioLingual, and adapts them efficiently for hashing using parameter-efficient fine-tuning. We evaluate our method on large-scale benchmarks, including iNaturalist2024 for text-to-image retrieval and iNatSounds2024 for text-to-audio retrieval, as well as multiple soundscape datasets to assess robustness under domain shift. Results show that retrieval using discrete hypercube embeddings achieves competitive, and in several cases superior, performance compared to continuous embeddings, while drastically reducing memory and search cost. Moreover, we observe that the hashing objective consistently improves the underlying encoder representations, leading to stronger retrieval and zero-shot generalization. These results demonstrate that binary, language-based retrieval enables scalable and efficient search over large wildlife archives for biodiversity monitoring systems.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
NatureLM-audio: an Audio-Language Foundation Model for Bioacoustics
Nov 11, 2024



Large language models (LLMs) prompted with text and audio represent the state of the art in various auditory tasks, including speech, music, and general audio, showing emergent abilities on unseen tasks. However, these capabilities have yet to be fully demonstrated in bioacoustics tasks, such as detecting animal vocalizations in large recordings, classifying rare and endangered species, and labeling context and behavior - tasks that are crucial for conservation, biodiversity monitoring, and the study of animal behavior. In this work, we present NatureLM-audio, the first audio-language foundation model specifically designed for bioacoustics. Our carefully curated training dataset comprises text-audio pairs spanning a diverse range of bioacoustics, speech, and music data, designed to address the challenges posed by limited annotated datasets in the field. We demonstrate successful transfer of learned representations from music and speech to bioacoustics, and our model shows promising generalization to unseen taxa and tasks. Importantly, we test NatureLM-audio on a novel benchmark (BEANS-Zero) and it sets the new state of the art (SotA) on several bioacoustics tasks, including zero-shot classification of unseen species. To advance bioacoustics research, we also open-source the code for generating training and benchmark data, as well as for training the model.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Transferable Models for Bioacoustics with Human Language Supervision
Aug 09, 2023



Passive acoustic monitoring offers a scalable, non-invasive method for tracking global biodiversity and anthropogenic impacts on species. Although deep learning has become a vital tool for processing this data, current models are inflexible, typically cover only a handful of species, and are limited by data scarcity. In this work, we propose BioLingual, a new model for bioacoustics based on contrastive language-audio pretraining. We first aggregate bioacoustic archives into a language-audio dataset, called AnimalSpeak, with over a million audio-caption pairs holding information on species, vocalization context, and animal behavior. After training on this dataset to connect language and audio representations, our model can identify over a thousand species' calls across taxa, complete bioacoustic tasks zero-shot, and retrieve animal vocalization recordings from natural text queries. When fine-tuned, BioLingual sets a new state-of-the-art on nine tasks in the Benchmark of Animal Sounds. Given its broad taxa coverage and ability to be flexibly queried in human language, we believe this model opens new paradigms in ecological monitoring and research, including free-text search on the world's acoustic monitoring archives. We open-source our models, dataset, and code.
Interpreting multi-variate models with setPCA
Nov 17, 2021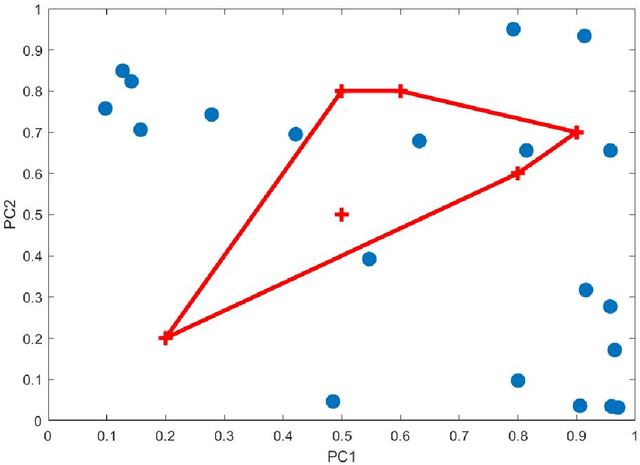
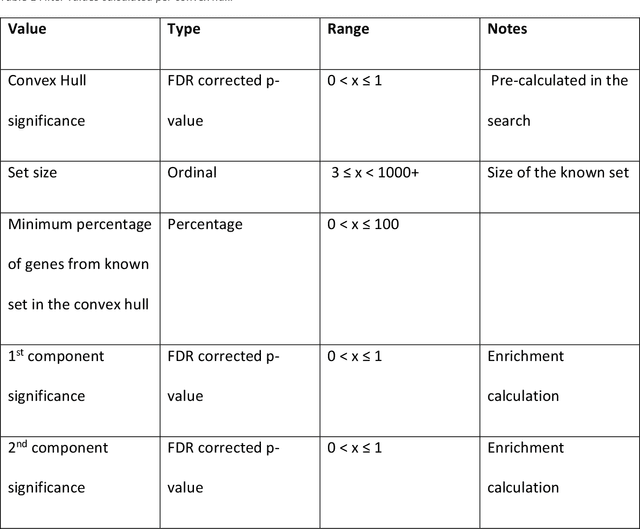
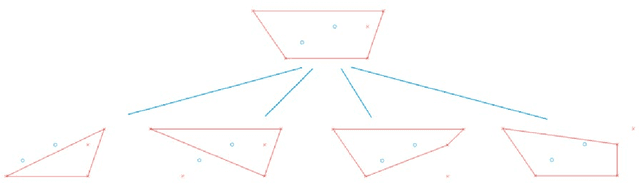
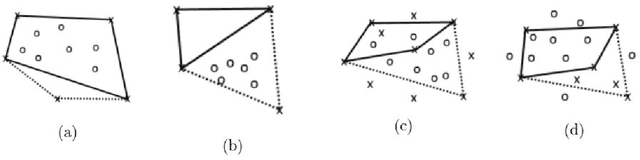
Principal Component Analysis (PCA) and other multi-variate models are often used in the analysis of "omics" data. These models contain much information which is currently neither easily accessible nor interpretable. Here we present an algorithmic method which has been developed to integrate this information with existing databases of background knowledge, stored in the form of known sets (for instance genesets or pathways). To make this accessible we have produced a Graphical User Interface (GUI) in Matlab which allows the overlay of known set information onto the loadings plot and thus improves the interpretability of the multi-variate model. For each known set the optimal convex hull, covering a subset of elements from the known set, is found through a search algorithm and displayed. In this paper we discuss two main topics; the details of the search algorithm for the optimal convex hull for this problem and the GUI interface which is freely available for download for academic use.