 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Hindsight to Anchor Past Knowledge in Continual Learning
Feb 19, 2020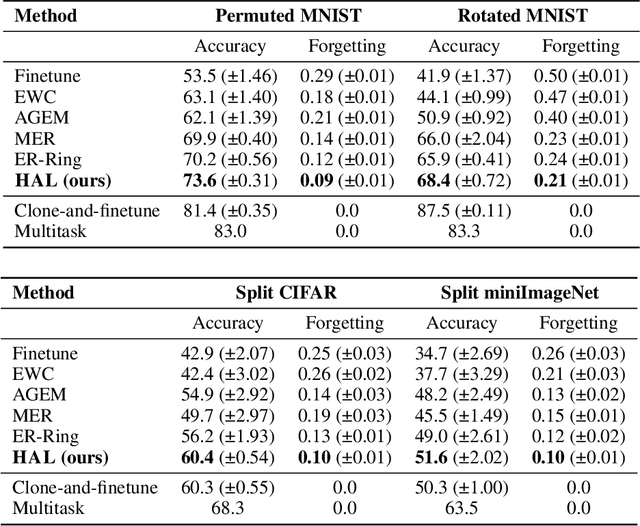
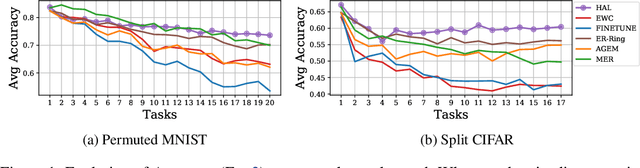
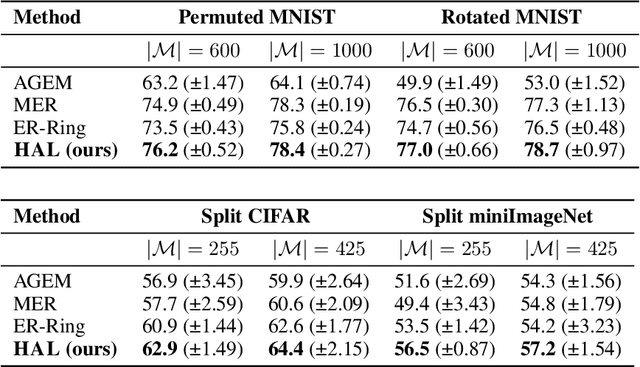
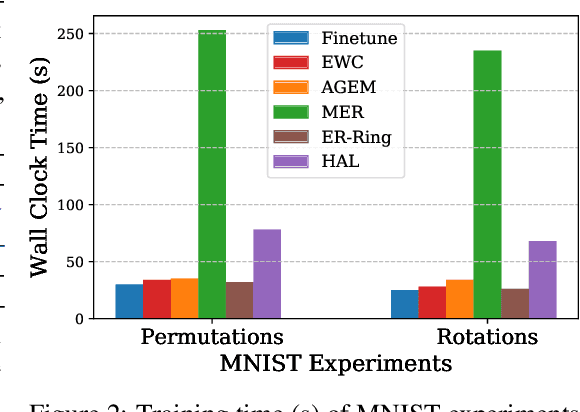
In continual learning, the learner faces a stream of data whose distribution changes over time. Modern neural networks are known to suffer under this setting, as they quickly forget previously acquired knowledge. To address such catastrophic forgetting, many continual learning methods implement different types of experience replay, re-learning on past data stored in a small buffer known as episodic memory. In this work, we complement experience replay with a new objective that we call anchoring, where the learner uses bilevel optimization to update its knowledge on the current task, while keeping intact the predictions on some anchor points of past tasks. These anchor points are learned using gradient-based optimization to maximize forgetting, which is approximated by fine-tuning the currently trained model on the episodic memory of past tasks. Experiments on several supervised learning benchmarks for continual learning demonstrate that our approach improves the standard experience replay in terms of both accuracy and forgetting metrics and for various sizes of episodic memories.
Invariant Risk Minimization
Jul 05, 2019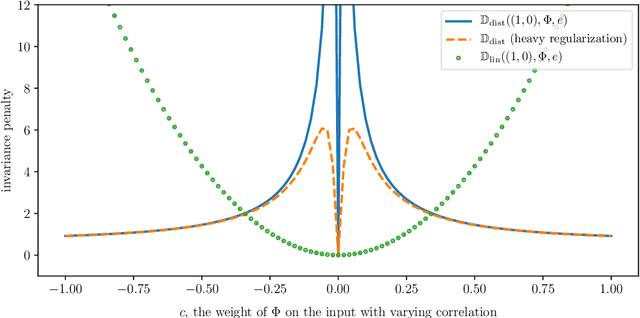

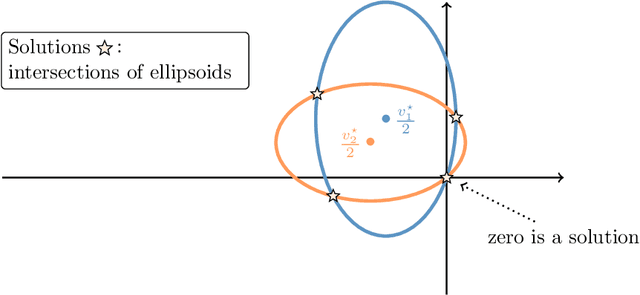
We introduce Invariant Risk Minimization (IRM), a learning paradigm to estimate invariant correlations across multiple training distributions. To achieve this goal, IRM learns a data representation such that the optimal classifier, on top of that data representation, matches for all training distributions. Through theory and experiments, we show how the invariances learned by IRM relate to the causal structures governing the data and enable out-of-distribution generalization.
Interpolation Consistency Training for Semi-Supervised Learning
Mar 09, 2019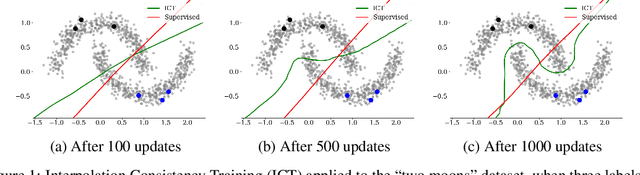
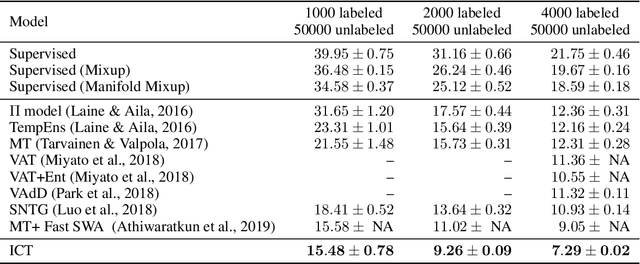
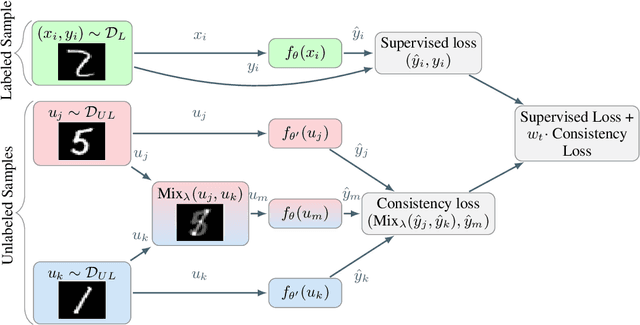
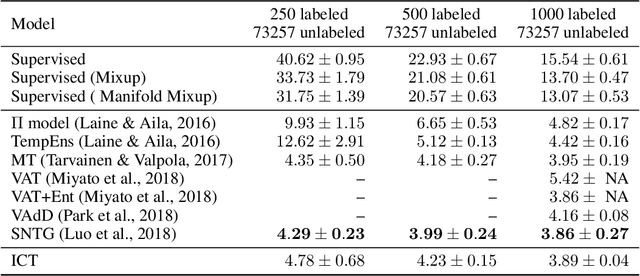
We introduce Interpolation Consistency Training (ICT), a simple and computation efficient algorithm for training Deep Neural Networks in the semi-supervised learning paradigm. ICT encourages the prediction at an interpolation of unlabeled points to be consistent with the interpolation of the predictions at those points. In classification problems, ICT moves the decision boundary to low-density regions of the data distribution. Our experiments show that ICT achieves state-of-the-art performance when applied to standard neural network architectures on the CIFAR-10 and SVHN benchmark datasets.
Learning about an exponential amount of conditional distributions
Feb 22, 2019
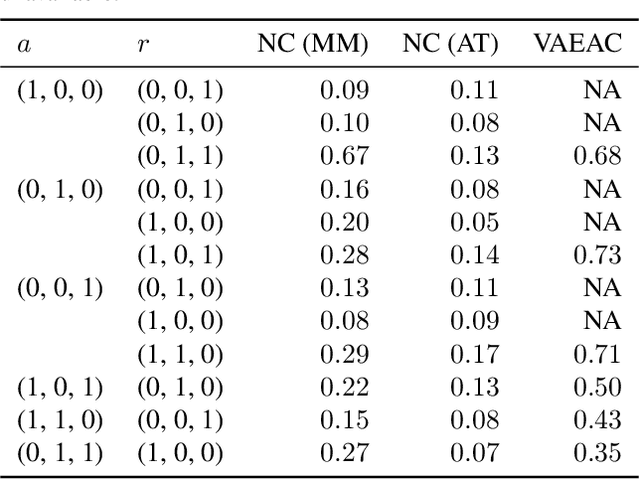


We introduce the Neural Conditioner (NC), a self-supervised machine able to learn about all the conditional distributions of a random vector $X$. The NC is a function $NC(x \cdot a, a, r)$ that leverages adversarial training to match each conditional distribution $P(X_r|X_a=x_a)$. After training, the NC generalizes to sample from conditional distributions never seen, including the joint distribution. The NC is also able to auto-encode examples, providing data representations useful for downstream classification tasks. In sum, the NC integrates different self-supervised tasks (each being the estimation of a conditional distribution) and levels of supervision (partially observed data) seamlessly into a single learning experience.
Frequentist uncertainty estimates for deep learning
Nov 02, 2018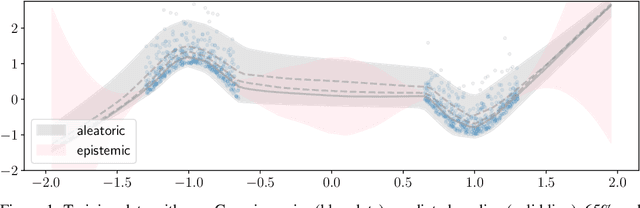
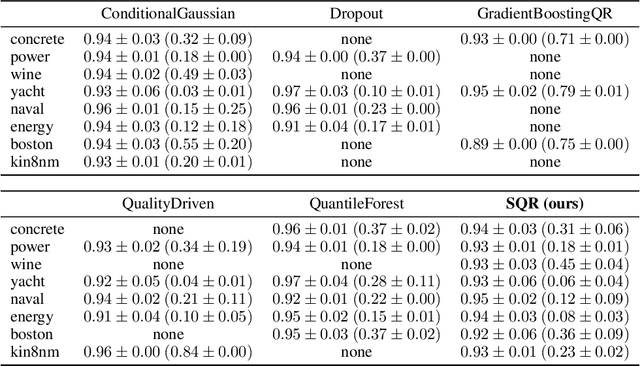
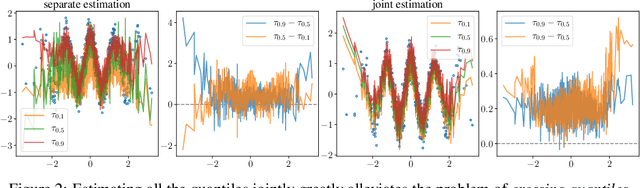
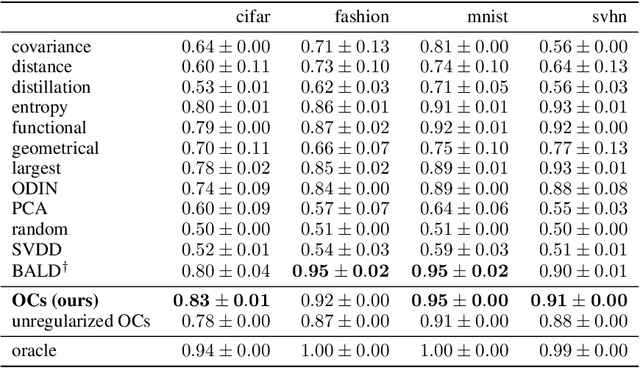
We provide frequentist estimates of aleatoric and epistemic uncertainty for deep neural networks. To estimate aleatoric uncertainty we propose simultaneous quantile regression, a loss function to learn all the conditional quantiles of a given target variable. These quantiles lead to well-calibrated prediction intervals. To estimate epistemic uncertainty we propose training certificates, a collection of diverse non-trivial functions that map all training samples to zero. These certificates map out-of-distribution examples to non-zero values, signaling high epistemic uncertainty. We compare our proposals to prior art in various experiments.
Adversarial Vulnerability of Neural Networks Increases With Input Dimension
Oct 08, 2018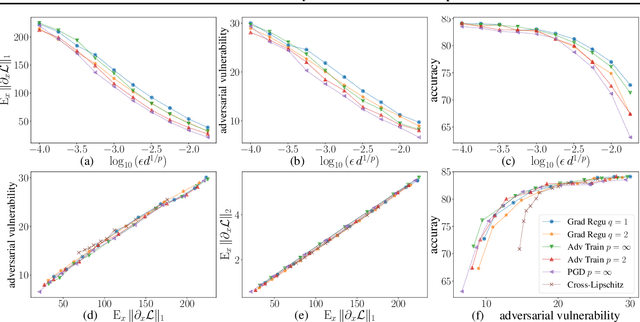
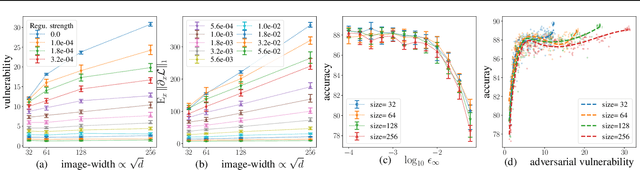
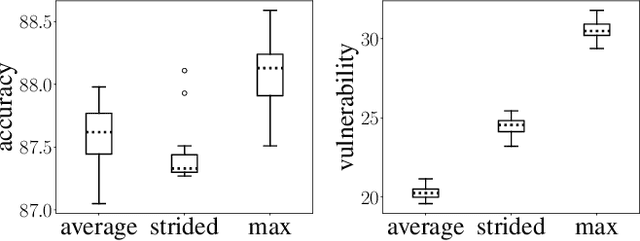
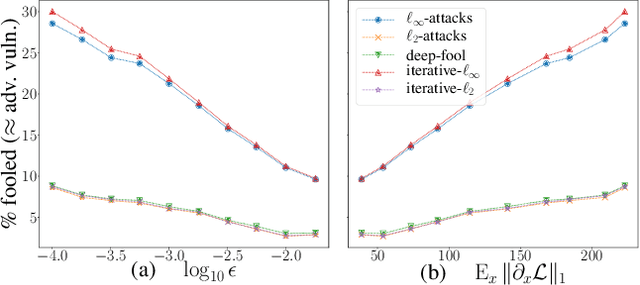
Over the past four years, neural networks have been proven vulnerable to adversarial images: targeted but imperceptible image perturbations lead to drastically different predictions. We show that adversarial vulnerability increases with the gradients of the training objective when viewed as a function of the inputs. For most current network architectures, we prove that the $\ell_1$-norm of these gradients grows as the square root of the input size. These nets therefore become increasingly vulnerable with growing image size. Our proofs rely on the network's weight distribution at initialization, but extensive experiments confirm that our conclusions still hold after training.
mixup: Beyond Empirical Risk Minimization
Apr 27, 2018
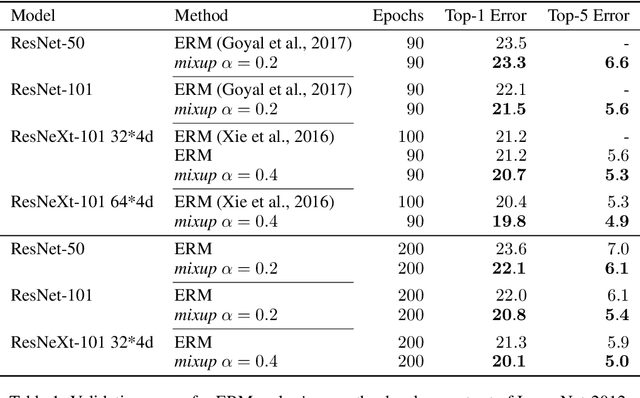
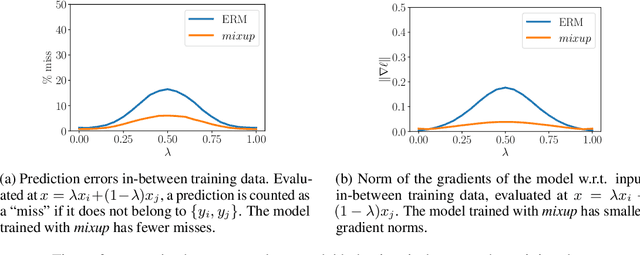
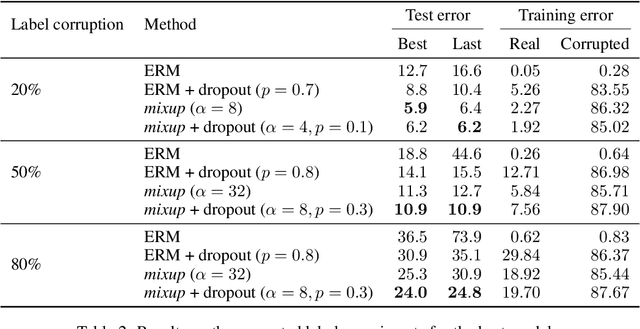
Large deep neural networks are powerful, but exhibit undesirable behaviors such as memorization and sensitivity to adversarial examples. In this work, we propose mixup, a simple learning principle to alleviate these issues. In essence, mixup trains a neural network on convex combinations of pairs of examples and their labels. By doing so, mixup regularizes the neural network to favor simple linear behavior in-between training examples. Our experiments on the ImageNet-2012, CIFAR-10, CIFAR-100, Google commands and UCI datasets show that mixup improves the generalization of state-of-the-art neural network architectures. We also find that mixup reduces the memorization of corrupt labels, increases the robustness to adversarial examples, and stabilizes the training of generative adversarial networks.
Revisiting Classifier Two-Sample Tests
Mar 13, 2018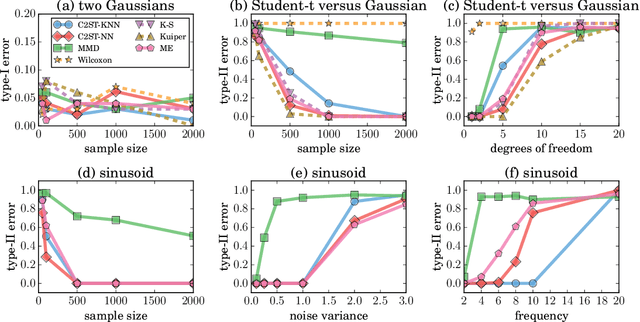
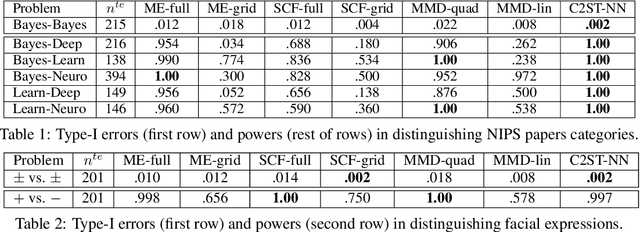
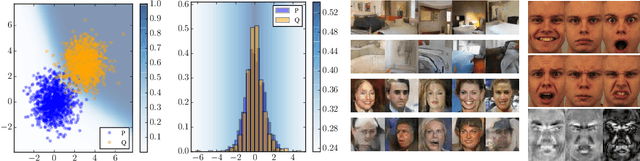

The goal of two-sample tests is to assess whether two samples, $S_P \sim P^n$ and $S_Q \sim Q^m$, are drawn from the same distribution. Perhaps intriguingly, one relatively unexplored method to build two-sample tests is the use of binary classifiers. In particular, construct a dataset by pairing the $n$ examples in $S_P$ with a positive label, and by pairing the $m$ examples in $S_Q$ with a negative label. If the null hypothesis "$P = Q$" is true, then the classification accuracy of a binary classifier on a held-out subset of this dataset should remain near chance-level. As we will show, such Classifier Two-Sample Tests (C2ST) learn a suitable representation of the data on the fly, return test statistics in interpretable units, have a simple null distribution, and their predictive uncertainty allow to interpret where $P$ and $Q$ differ. The goal of this paper is to establish the properties, performance, and uses of C2ST. First, we analyze their main theoretical properties. Second, we compare their performance against a variety of state-of-the-art alternatives. Third, we propose their use to evaluate the sample quality of generative models with intractable likelihoods, such as Generative Adversarial Networks (GANs). Fourth, we showcase the novel application of GANs together with C2ST for causal discovery.
SAM: Structural Agnostic Model, Causal Discovery and Penalized Adversarial Learning
Mar 13, 2018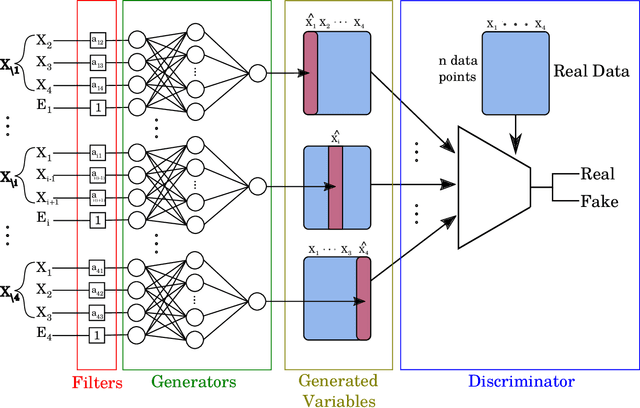
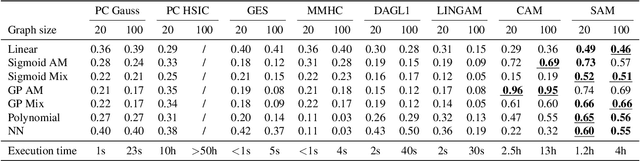
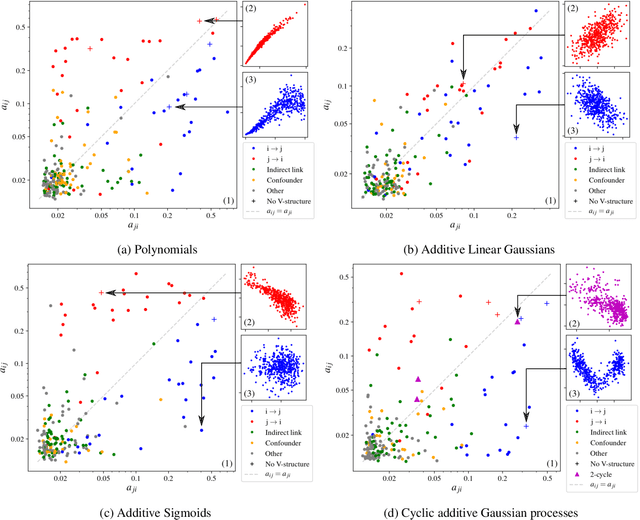
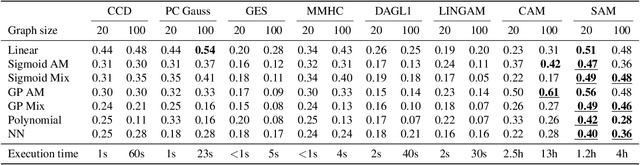
We present the Structural Agnostic Model (SAM), a framework to estimate end-to-end non-acyclic causal graphs from observational data. In a nutshell, SAM implements an adversarial game in which a separate model generates each variable, given real values from all others. In tandem, a discriminator attempts to distinguish between the joint distributions of real and generated samples. Finally, a sparsity penalty forces each generator to consider only a small subset of the variables, yielding a sparse causal graph. SAM scales easily to hundreds variables. Our experiments show the state-of-the-art performance of SAM on discovering causal structures and modeling interventions, in both acyclic and non-acyclic graphs.
Geometrical Insights for Implicit Generative Modeling
Mar 12, 2018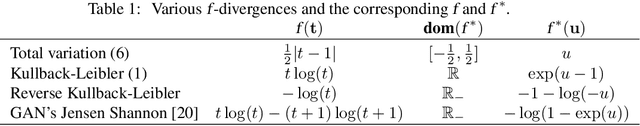
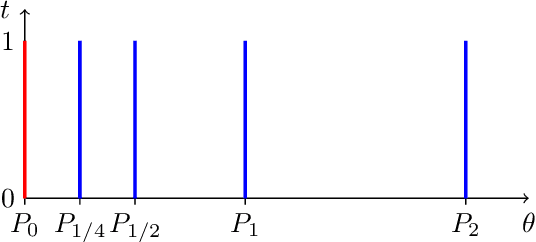

Learning algorithms for implicit generative models can optimize a variety of criteria that measure how the data distribution differs from the implicit model distribution, including the Wasserstein distance, the Energy distance, and the Maximum Mean Discrepancy criterion. A careful look at the geometries induced by these distances on the space of probability measures reveals interesting differences. In particular, we can establish surprising approximate global convergence guarantees for the $1$-Wasserstein distance,even when the parametric generator has a nonconvex parametrization.