 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLens: An End-to-End Framework for Error Detection and Correction in Text-to-SQL
Jun 04, 2025Text-to-SQL systems translate natural language (NL) questions into SQL queries, enabling non-technical users to interact with structured data. While large language models (LLMs) have shown promising results on the text-to-SQL task, they often produce semantically incorrect yet syntactically valid queries, with limited insight into their reliability. We propose SQLens, an end-to-end framework for fine-grained detection and correction of semantic errors in LLM-generated SQL. SQLens integrates error signals from both the underlying database and the LLM to identify potential semantic errors within SQL clauses. It further leverages these signals to guide query correction. Empirical results on two public benchmarks show that SQLens outperforms the best LLM-based self-evaluation method by 25.78% in F1 for error detection, and improves execution accuracy of out-of-the-box text-to-SQL systems by up to 20%.
TailorSQL: An NL2SQL System Tailored to Your Query Workload
May 29, 2025NL2SQL (natural language to SQL) translates natural language questions into SQL queries, thereby making structured data accessible to non-technical users, serving as the foundation for intelligent data applications. State-of-the-art NL2SQL techniques typically perform translation by retrieving database-specific information, such as the database schema, and invoking a pre-trained large language model (LLM) using the question and retrieved information to generate the SQL query. However, existing NL2SQL techniques miss a key opportunity which is present in real-world settings: NL2SQL is typically applied on existing databases which have already served many SQL queries in the past. The past query workload implicitly contains information which is helpful for accurate NL2SQL translation and is not apparent from the database schema alone, such as common join paths and the semantics of obscurely-named tables and columns. We introduce TailorSQL, a NL2SQL system that takes advantage of information in the past query workload to improve both the accuracy and latency of translating natural language questions into SQL. By specializing to a given workload, TailorSQL achieves up to 2$\times$ improvement in execution accuracy on standardized benchmarks.
ODIN: A NL2SQL Recommender to Handle Schema Ambiguity
May 25, 2025NL2SQL (natural language to SQL) systems translate natural language into SQL queries, allowing users with no technical background to interact with databases and create tools like reports or visualizations. While recent advancements in large language models (LLMs) have significantly improved NL2SQL accuracy, schema ambiguity remains a major challenge in enterprise environments with complex schemas, where multiple tables and columns with semantically similar names often co-exist. To address schema ambiguity, we introduce ODIN, a NL2SQL recommendation engine. Instead of producing a single SQL query given a natural language question, ODIN generates a set of potential SQL queries by accounting for different interpretations of ambiguous schema components. ODIN dynamically adjusts the number of suggestions based on the level of ambiguity, and ODIN learns from user feedback to personalize future SQL query recommendations. Our evaluation shows that ODIN improves the likelihood of generating the correct SQL query by 1.5-2$\times$ compared to baselines.
Bounding the Last Mile: Efficient Learned String Indexing
Nov 29, 2021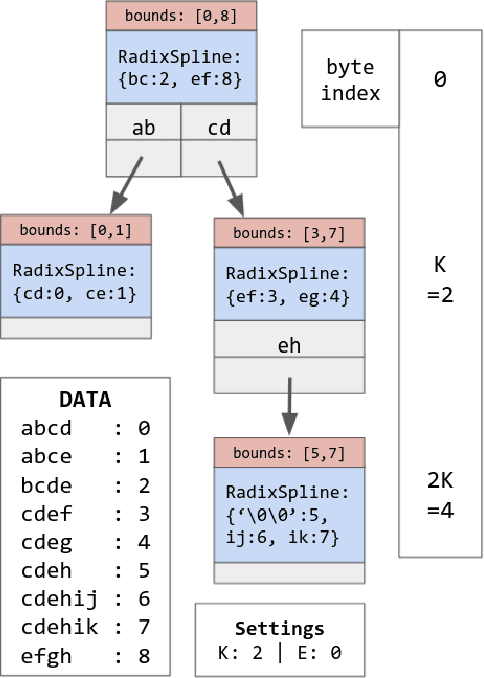
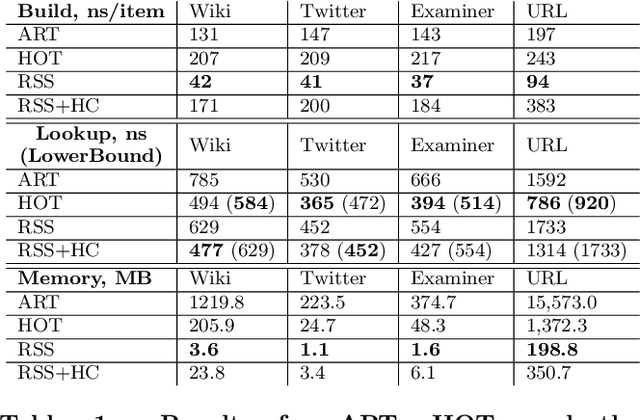
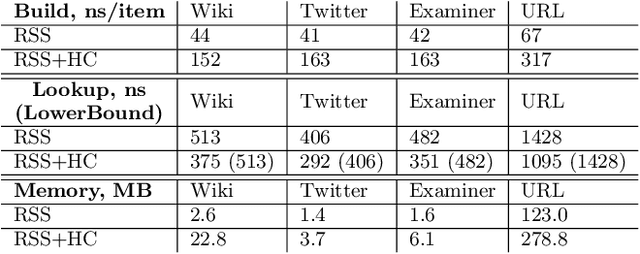
We introduce the RadixStringSpline (RSS) learned index structure for efficiently indexing strings. RSS is a tree of radix splines each indexing a fixed number of bytes. RSS approaches or exceeds the performance of traditional string indexes while using 7-70$\times$ less memory. RSS achieves this by using the minimal string prefix to sufficiently distinguish the data unlike most learned approaches which index the entire string. Additionally, the bounded-error nature of RSS accelerates the last mile search and also enables a memory-efficient hash-table lookup accelerator. We benchmark RSS on several real-world string datasets against ART and HOT. Our experiments suggest this line of research may be promising for future memory-intensive database applications.
Partitioned Learned Bloom Filter
Jun 05, 2020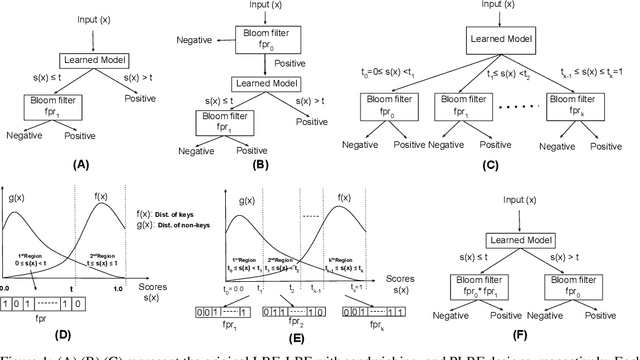
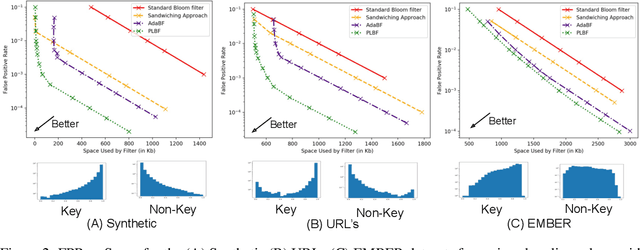
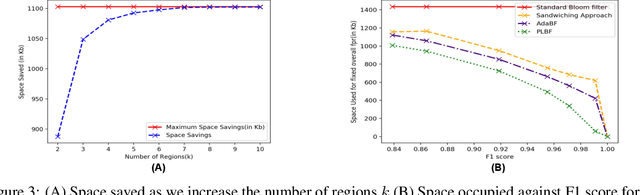
Learned Bloom filters enhance standard Bloom filters by using a learned model for the represented data set. However, a learned Bloom filter may under-utilize the model by not taking full advantage of the output. The learned Bloom filter uses the output score by simply applying a threshold, with elements above the threshold being interpreted as positives, and elements below the threshold subject to further analysis independent of the output score (using a smaller backup Bloom filter to prevent false negatives). While recent work has suggested additional heuristic approaches to take better advantage of the score, the results are only heuristic. Here, we instead frame the problem of optimal model utilization as an optimization problem. We show that the optimization problem can be effectively solved efficiently, yielding an improved {partitioned learned Bloom filter}, which partitions the score space and utilizes separate backup Bloom filters for each region. Experimental results from both simulated and real-world datasets show significant performance improvements from our optimization approach over both the original learned Bloom filter constructions and previously proposed heuristic improvements.