 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifying Joint Adversarial Robustness for Model Ensembles
Apr 21, 2020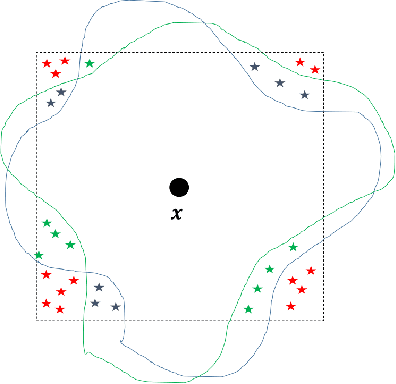
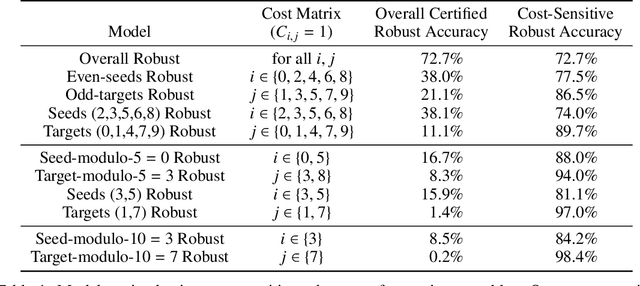
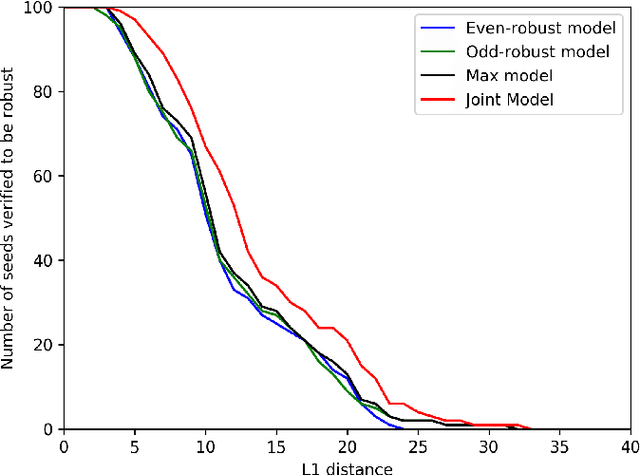
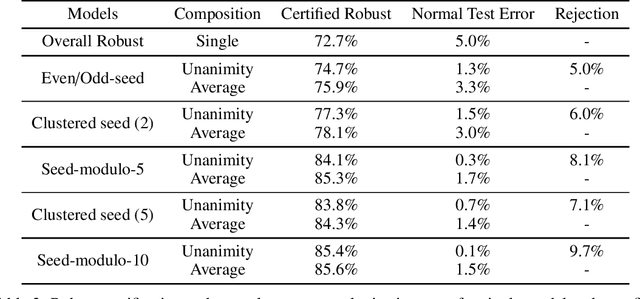
Deep Neural Networks (DNNs) are often vulnerable to adversarial examples.Several proposed defenses deploy an ensemble of models with the hope that, although the individual models may be vulnerable, an adversary will not be able to find an adversarial example that succeeds against the ensemble. Depending on how the ensemble is used, an attacker may need to find a single adversarial example that succeeds against all, or a majority, of the models in the ensemble. The effectiveness of ensemble defenses against strong adversaries depends on the vulnerability spaces of models in the ensemble being disjoint. We consider the joint vulnerability of an ensemble of models, and propose a novel technique for certifying the joint robustness of ensembles, building upon prior works on single-model robustness certification. We evaluate the robustness of various models ensembles, including models trained using cost-sensitive robustness to be diverse, to improve understanding of the potential effectiveness of ensemble models as a defense against adversarial examples.
One Neuron to Fool Them All
Mar 20, 2020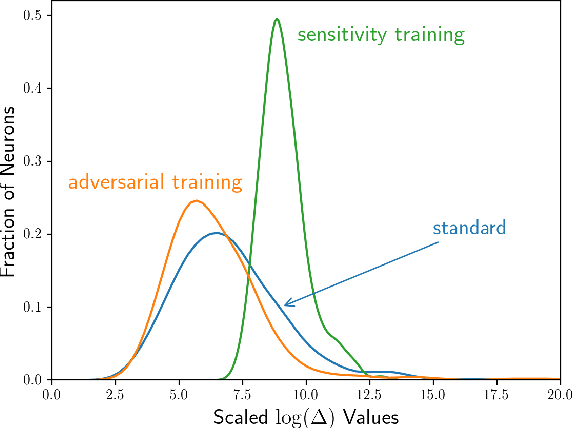
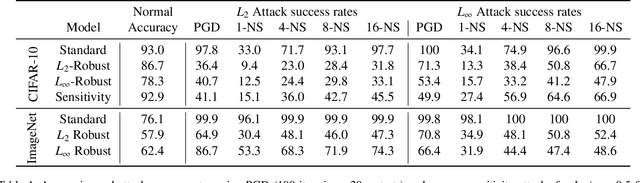
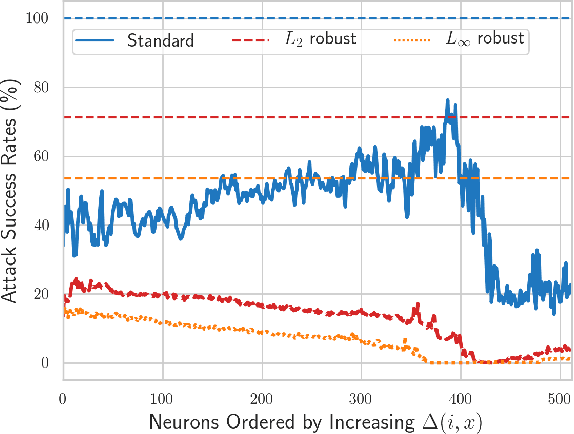
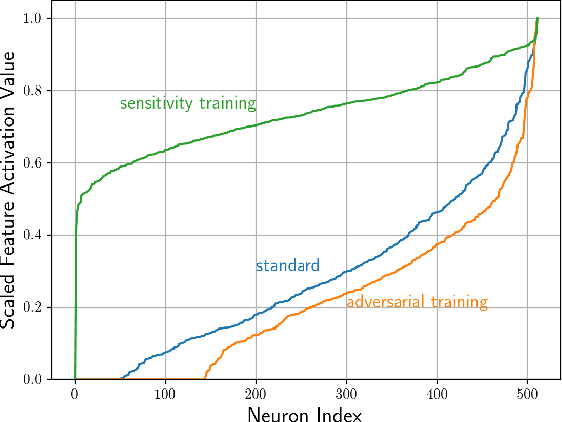
Despite vast research in adversarial examples, the root causes of model susceptibility are not well understood. Instead of looking at attack-specific robustness, we propose a notion that evaluates the sensitivity of individual neurons in terms of how robust the model's output is to direct perturbations of that neuron's output. Analyzing models from this perspective reveals distinctive characteristics of standard as well as adversarially-trained robust models, and leads to several curious results. In our experiments on CIFAR-10 and ImageNet, we find that attacks using a loss function that targets just a single sensitive neuron find adversarial examples nearly as effectively as ones that target the full model. We analyze the properties of these sensitive neurons to propose a regularization term that can help a model achieve robustness to a variety of different perturbation constraints while maintaining accuracy on natural data distributions. Code for all our experiments is available at https://github.com/iamgroot42/sauron .
Understanding the Intrinsic Robustness of Image Distributions using Conditional Generative Models
Mar 01, 2020


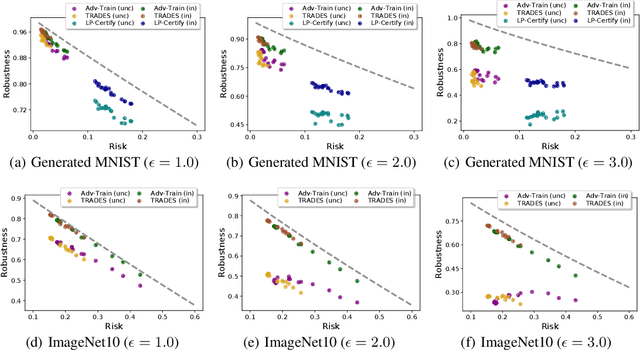
Starting with Gilmer et al. (2018), several works have demonstrated the inevitability of adversarial examples based on different assumptions about the underlying input probability space. It remains unclear, however, whether these results apply to natural image distributions. In this work, we assume the underlying data distribution is captured by some conditional generative model, and prove intrinsic robustness bounds for a general class of classifiers, which solves an open problem in Fawzi et al. (2018). Building upon the state-of-the-art conditional generative models, we study the intrinsic robustness of two common image benchmarks under $\ell_2$ perturbations, and show the existence of a large gap between the robustness limits implied by our theory and the adversarial robustness achieved by current state-of-the-art robust models. Code for all our experiments is available at https://github.com/xiaozhanguva/Intrinsic-Rob.
Learning Adversarially Robust Representations via Worst-Case Mutual Information Maximization
Feb 26, 2020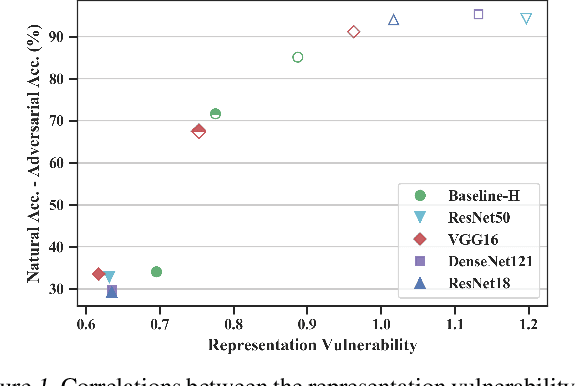
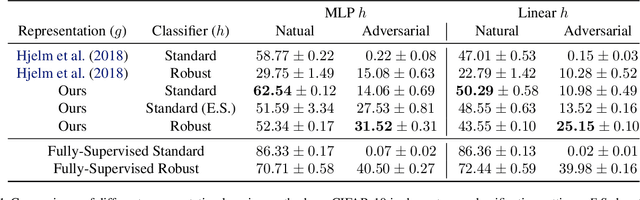
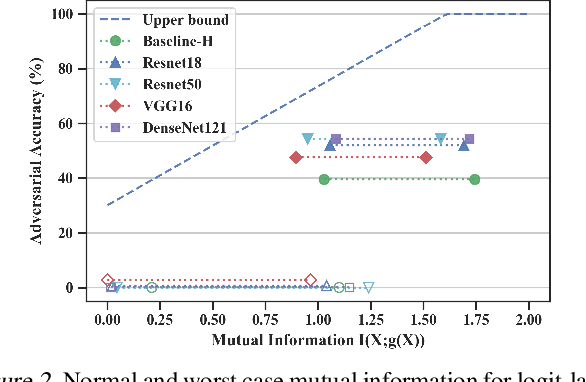

Training machine learning models to be robust against adversarial inputs poses seemingly insurmountable challenges. To better understand model robustness, we consider the underlying problem of learning robust representations. We develop a general definition of representation vulnerability that captures the maximum change of mutual information between the input and output distributions, under the worst-case input distribution perturbation. We prove a theorem that establishes a lower bound on the minimum adversarial risk that can be achieved for any downstream classifier based on this definition. We then propose an unsupervised learning method for obtaining intrinsically robust representations by maximizing the worst-case mutual information between input and output distributions. Experiments on downstream classification tasks and analyses of saliency maps support the robustness of the representations found using unsupervised learning with our training principle.
Advances and Open Problems in Federated Learning
Dec 10, 2019
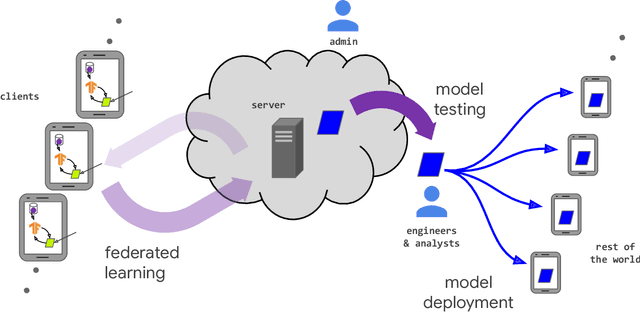
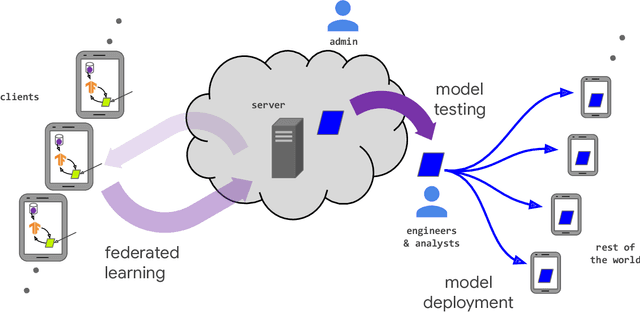

Federated learning (FL) is a machine learning setting where many clients (e.g. mobile devices or whole organizations) collaboratively train a model under the orchestration of a central server (e.g. service provider), while keeping the training data decentralized. FL embodies the principles of focused data collection and minimization, and can mitigate many of the systemic privacy risks and costs resulting from traditional, centralized machine learning and data science approaches. Motivated by the explosive growth in FL research, this paper discusses recent advances and presents an extensive collection of open problems and challenges.
Efficient Privacy-Preserving Nonconvex Optimization
Oct 30, 2019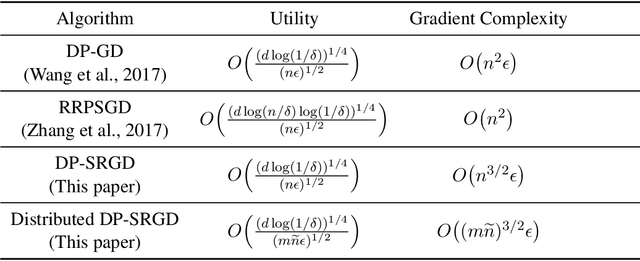
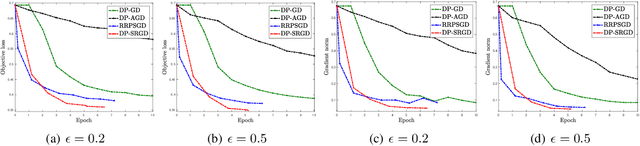
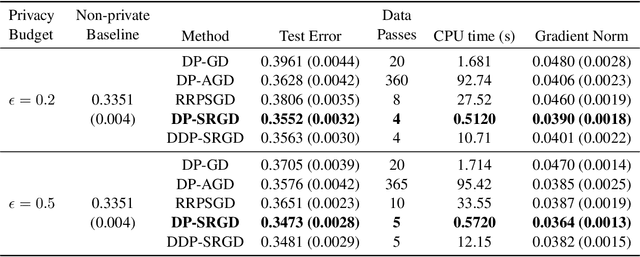
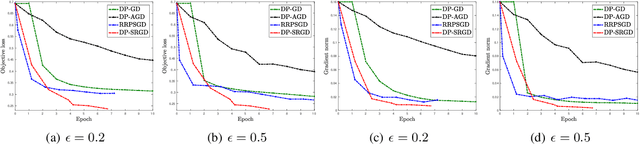
While many solutions for privacy-preserving convex empirical risk minimization (ERM) have been developed, privacy-preserving nonconvex ERM remains under challenging. In this paper, we study nonconvex ERM, which takes the form of minimizing a finite-sum of nonconvex loss functions over a training set. To achieve both efficiency and strong privacy guarantees with efficiency, we propose a differentially-private stochastic gradient descent algorithm for nonconvex ERM, and provide a tight analysis of its privacy and utility guarantees, as well as its gradient complexity. We show that our proposed algorithm can substantially reduce gradient complexity while matching the best-known utility guarantee obtained by Wang et al. (2017). We extend our algorithm to the distributed setting using secure multi-party computation, and show that it is possible for a distributed algorithm to match the privacy and utility guarantees of a centralized algorithm in this setting. Our experiments on benchmark nonconvex ERM problems and real datasets demonstrate superior performance in terms of both training time and utility gains compared with previous differentially-private methods using the same privacy budgets.
Empirically Measuring Concentration: Fundamental Limits on Intrinsic Robustness
May 29, 2019
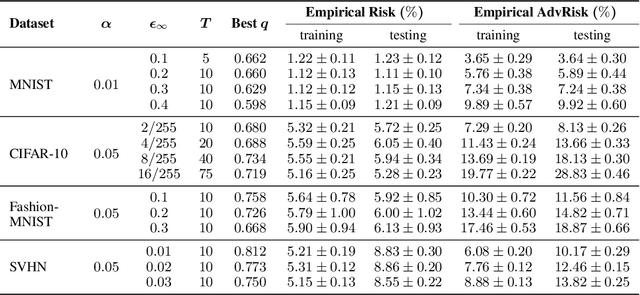
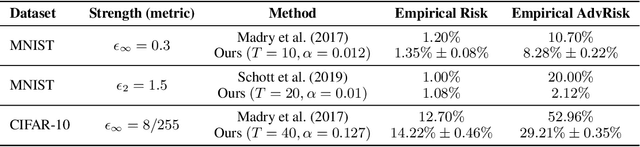
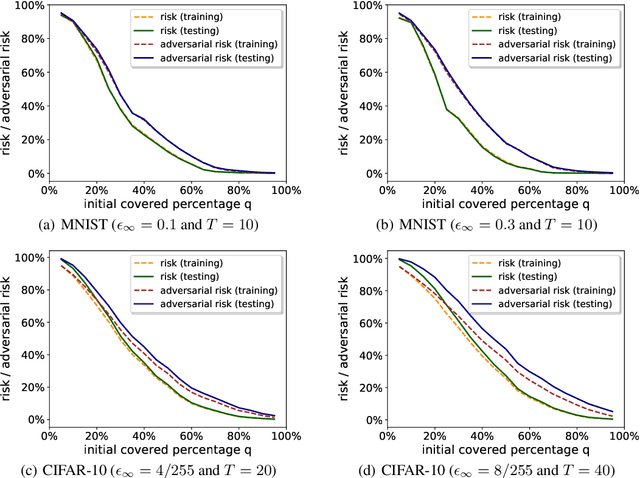
Many recent works have shown that adversarial examples that fool classifiers can be found by minimally perturbing a normal input. Recent theoretical results, starting with Gilmer et al. (2018), show that if the inputs are drawn from a concentrated metric probability space, then adversarial examples with small perturbation are inevitable. A concentrated space has the property that any subset with $\Omega(1)$ (e.g., 1/100) measure, according to the imposed distribution, has small distance to almost all (e.g., 99/100) of the points in the space. It is not clear, however, whether these theoretical results apply to actual distributions such as images. This paper presents a method for empirically measuring and bounding the concentration of a concrete dataset which is proven to converge to the actual concentration. We use it to empirically estimate the intrinsic robustness to $\ell_\infty$ and $\ell_2$ perturbations of several image classification benchmarks.
When Relaxations Go Bad: "Differentially-Private" Machine Learning
Mar 01, 2019
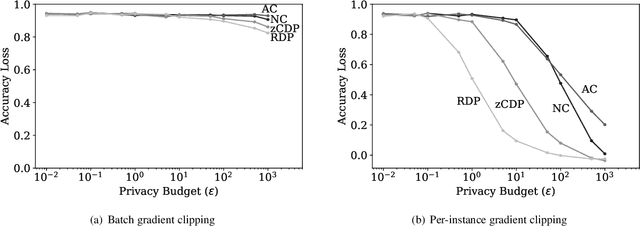
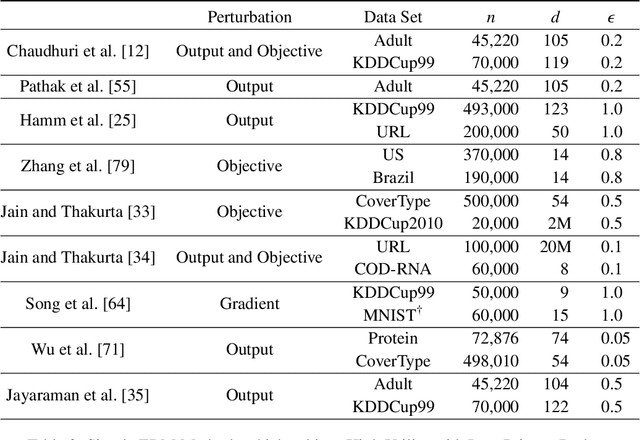
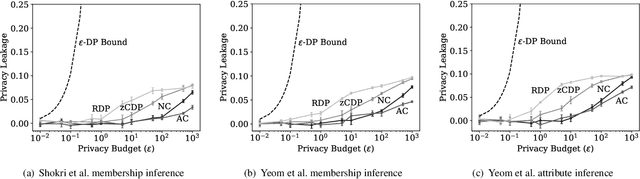
Differential privacy is becoming a standard notion for performing privacy-preserving machine learning over sensitive data. It provides formal guarantees, in terms of the privacy budget, $\epsilon$, on how much information about individual training records is leaked by the model. While the privacy budget is directly correlated to the privacy leakage, the calibration of the privacy budget is not well understood. As a result, many existing works on privacy-preserving machine learning select large values of $\epsilon$ in order to get acceptable utility of the model, with little understanding of the concrete impact of such choices on meaningful privacy. Moreover, in scenarios where iterative learning procedures are used which require privacy guarantees for each iteration, relaxed definitions of differential privacy are often used which further tradeoff privacy for better utility. In this paper, we evaluate the impacts of these choices on privacy in experiments with logistic regression and neural network models. We quantify the privacy leakage in terms of advantage of the adversary performing inference attacks and by analyzing the number of members at risk for exposure. Our main findings are that current mechanisms for differential privacy for machine learning rarely offer acceptable utility-privacy tradeoffs: settings that provide limited accuracy loss provide little effective privacy, and settings that provide strong privacy result in useless models. Open source code is available at https://github.com/bargavj/EvaluatingDPML.
Context-aware Monitoring in Robotic Surgery
Jan 28, 2019
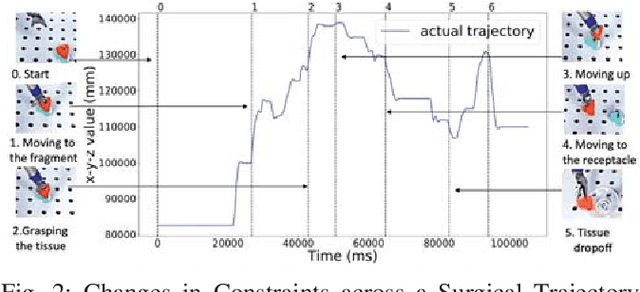
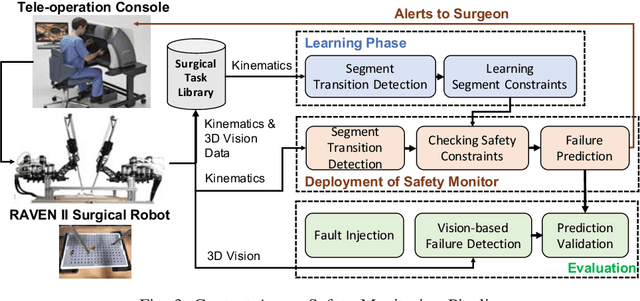
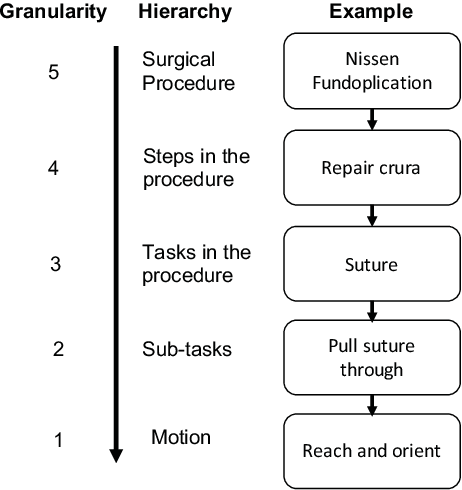
Robotic-assisted minimally invasive surgery (MIS) has enabled procedures with increased precision and dexterity, but surgical robots are still open loop and require surgeons to work with a tele-operation console providing only limited visual feedback. In this setting, mechanical failures, software faults, or human errors might lead to adverse events resulting in patient complications or fatalities. We argue that impending adverse events could be detected and mitigated by applying context-specific safety constraints on the motions of the robot. We present a context-aware safety monitoring system which segments a surgical task into subtasks using kinematics data and monitors safety constraints specific to each subtask. To test our hypothesis about context specificity of safety constraints, we analyze recorded demonstrations of dry-lab surgical tasks collected from the JIGSAWS database as well as from experiments we conducted on a Raven II surgical robot. Analysis of the trajectory data shows that each subtask of a given surgical procedure has consistent safety constraints across multiple demonstrations by different subjects. Our preliminary results show that violations of these safety constraints lead to unsafe events, and there is often sufficient time between the constraint violation and the safety-critical event to allow for a corrective action.
Cost-Sensitive Robustness against Adversarial Examples
Oct 22, 2018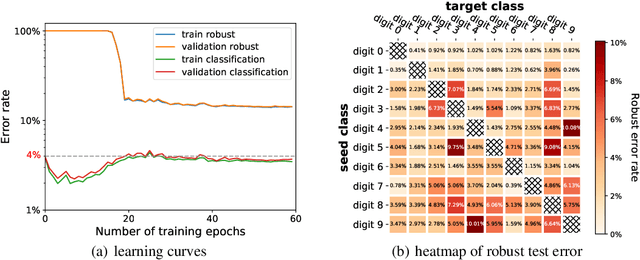
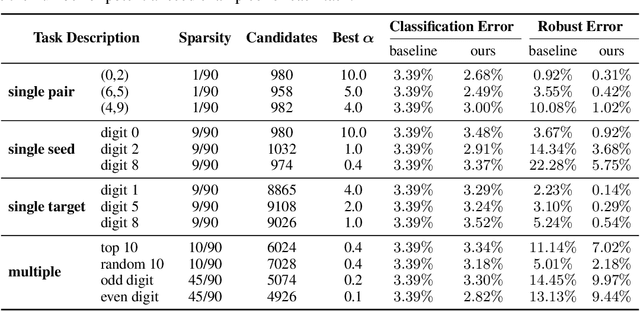
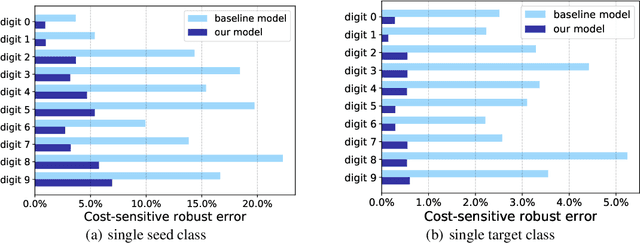

Several recent works have developed methods for training classifiers that are certifiably robust against norm-bounded adversarial perturbations. However, these methods assume that all the adversarial transformations provide equal value for adversaries, which is seldom the case in real-world applications. We advocate for cost-sensitive robustness as the criteria for measuring the classifier's performance for specific tasks. We encode the potential harm of different adversarial transformations in a cost matrix, and propose a general objective function to adapt the robust training method of Wong & Kolter (2018) to optimize for cost-sensitive robustness. Our experiments on simple MNIST and CIFAR10 models and a variety of cost matrices show that the proposed approach can produce models with substantially reduced cost-sensitive robust error, while maintaining classification accuracy.