 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironmental Sound Deepfake Detection Using Deep-Learning Framework
Apr 21, 2026In this paper, we propose a deep-learning framework for environmental sound deepfake detection (ESDD) -- the task of identifying whether the sound scene and sound event in an input audio recording is fake or not. To this end, we conducted extensive experiments to explore how individual spectrograms, a wide range of network architectures and pre-trained models, ensemble of spectrograms or network architectures affect the ESDD task performance. The experimental results on the benchmark datasets of EnvSDD and ESDD-Challenge-TestSet indicate that detecting deepfake audio of sound scene and detecting deepfake audio of sound event should be considered as individual tasks. We also indicate that the approach of finetuning a pre-trained model is more effective compared with training a model from scratch for the ESDD task. Eventually, our best model, which was finetuned from the pre-trained WavLM model with the proposed three-stage training strategy, achieve the Accuracy of 0.98, F1 Score of 0.95, AuC of 0.99 on EnvSDD Test subset and the Accuracy of 0.88, F1 Score of 0.77, and AuC of 0.92 on ESDD-Challenge-TestSet dataset.
Single-Agent LLMs Outperform Multi-Agent Systems on Multi-Hop Reasoning Under Equal Thinking Token Budgets
Apr 02, 2026Recent work reports strong performance from multi-agent LLM systems (MAS), but these gains are often confounded by increased test-time computation. When computation is normalized, single-agent systems (SAS) can match or outperform MAS, yet the theoretical basis and evaluation methodology behind this comparison remain unclear. We present an information-theoretic argument, grounded in the Data Processing Inequality, suggesting that under a fixed reasoning-token budget and with perfect context utilization, single-agent systems are more information-efficient. This perspective further predicts that multi-agent systems become competitive when a single agent's effective context utilization is degraded, or when more compute is expended. We test these predictions in a controlled empirical study across three model families (Qwen3, DeepSeek-R1-Distill-Llama, and Gemini 2.5), comparing SAS with multiple MAS architectures under matched budgets. We find that SAS consistently match or outperform MAS on multi-hop reasoning tasks when reasoning tokens are held constant. Beyond aggregate performance, we conduct a detailed diagnostic analysis of system behavior and evaluation methodology. We identify significant artifacts in API-based budget control (particularly in Gemini 2.5) and in standard benchmarks, both of which can inflate apparent gains from MAS. Overall, our results suggest that, for multi-hop reasoning tasks, many reported advantages of multi-agent systems are better explained by unaccounted computation and context effects rather than inherent architectural benefits, and highlight the importance of understanding and explicitly controlling the trade-offs between compute, context, and coordination in agentic systems.
A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Mar 29, 2026In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Entropy Guided Diversification and Preference Elicitation in Agentic Recommendation Systems
Mar 12, 2026Users on e-commerce platforms can be uncertain about their preferences early in their search. Queries to recommendation systems are frequently ambiguous, incomplete, or weakly specified. Agentic systems are expected to proactively reason, ask clarifying questions, and act on the user's behalf, which makes handling such ambiguity increasingly important. In existing platforms, ambiguity led to excessive interactions and question fatigue or overconfident recommendations prematurely collapsing the search space. We present an Interactive Decision Support System (IDSS) that addresses ambiguous user queries using entropy as a unifying signal. IDSS maintains a dynamically filtered candidate product set and quantifies uncertainty over item attributes using entropy. This uncertainty guides adaptive preference elicitation by selecting follow-up questions that maximize expected information gain. When preferences remain incomplete, IDSS explicitly incorporates residual uncertainty into downstream recommendations through uncertainty-aware ranking and entropy-based diversification, rather than forcing premature resolution. We evaluate IDSS using review-driven simulated users grounded in real user reviews, enabling a controlled study of diverse shopping behaviors. Our evaluation measures both interaction efficiency and recommendation quality. Results show that entropy-guided elicitation reduces unnecessary follow-up questions, while uncertainty-aware ranking and presentation yield more informative, diverse, and transparent recommendation sets under ambiguous intent. These findings demonstrate that entropy-guided reasoning provides an effective foundation for agentic recommendation systems operating under uncertainty.
Aud-Sur: An Audio Analyzer Assistant for Audio Surveillance Applications
Mar 31, 2025



In this paper, we present an audio analyzer assistant tool designed for a wide range of audio-based surveillance applications (This work is a part of our DEFAME FAKES and EUCINF projects). The proposed tool, refered to as Aud-Sur, comprises two main phases Audio Analysis and Audio Retrieval, respectively. In the first phase, multiple open-source audio models are leveraged to extract information from input audio recording uploaded by a user. In the second phase, users interact with the Aud-Sur tool via a natural question-and-answer manner, powered by a large language model (LLM), to retrieve the information extracted from the processed audio file. The Aud-Sur tool was deployed using Docker on a microservices-based architecture design. By leveraging open-source audio models for information extraction, LLM for audio information retrieval, and a microservices-based deployment approach, the proposed Aud-Sur tool offers a highly extensible and adaptable framework that can integrate more audio tasks, and be widely shared within the audio community for further development.
DIN-CTS: Low-Complexity Depthwise-Inception Neural Network with Contrastive Training Strategy for Deepfake Speech Detection
Feb 27, 2025In this paper, we propose a deep neural network approach for deepfake speech detection (DSD) based on a lowcomplexity Depthwise-Inception Network (DIN) trained with a contrastive training strategy (CTS). In this framework, input audio recordings are first transformed into spectrograms using Short-Time Fourier Transform (STFT) and Linear Filter (LF), which are then used to train the DIN. Once trained, the DIN processes bonafide utterances to extract audio embeddings, which are used to construct a Gaussian distribution representing genuine speech. Deepfake detection is then performed by computing the distance between a test utterance and this distribution to determine whether the utterance is fake or bonafide. To evaluate our proposed systems, we conducted extensive experiments on the benchmark dataset of ASVspoof 2019 LA. The experimental results demonstrate the effectiveness of combining the Depthwise-Inception Network with the contrastive learning strategy in distinguishing between fake and bonafide utterances. We achieved Equal Error Rate (EER), Accuracy (Acc.), F1, AUC scores of 4.6%, 95.4%, 97.3%, and 98.9% respectively using a single, low-complexity DIN with just 1.77 M parameters and 985 M FLOPS on short audio segments (4 seconds). Furthermore, our proposed system outperforms the single-system submissions in the ASVspoof 2019 LA challenge, showcasing its potential for real-time applications.
Terrorism Event Classification Using Fuzzy Inference Systems
Apr 11, 2010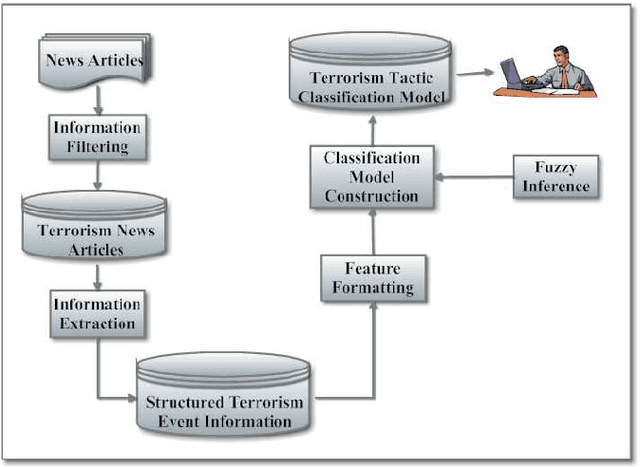
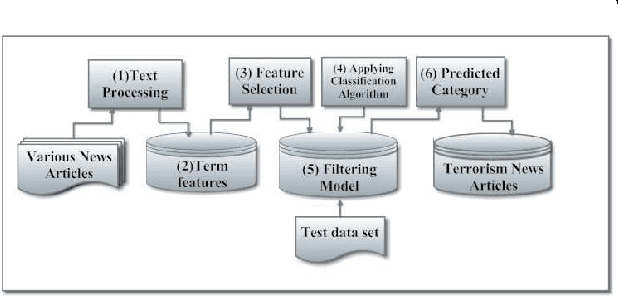
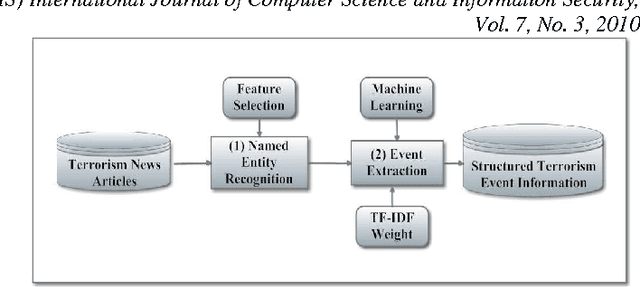
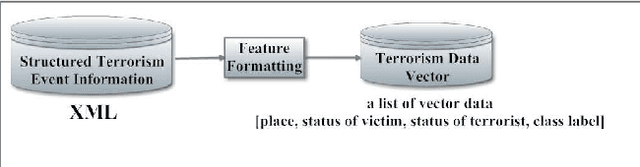
Terrorism has led to many problems in Thai societies, not only property damage but also civilian casualties. Predicting terrorism activities in advance can help prepare and manage risk from sabotage by these activities. This paper proposes a framework focusing on event classification in terrorism domain using fuzzy inference systems (FISs). Each FIS is a decision-making model combining fuzzy logic and approximate reasoning. It is generated in five main parts: the input interface, the fuzzification interface, knowledge base unit, decision making unit and output defuzzification interface. Adaptive neuro-fuzzy inference system (ANFIS) is a FIS model adapted by combining the fuzzy logic and neural network. The ANFIS utilizes automatic identification of fuzzy logic rules and adjustment of membership function (MF). Moreover, neural network can directly learn from data set to construct fuzzy logic rules and MF implemented in various applications. FIS settings are evaluated based on two comparisons. The first evaluation is the comparison between unstructured and structured events using the same FIS setting. The second comparison is the model settings between FIS and ANFIS for classifying structured events. The data set consists of news articles related to terrorism events in three southern provinces of Thailand. The experimental results show that the classification performance of the FIS resulting from structured events achieves satisfactory accuracy and is better than the unstructured events. In addition, the classification of structured events using ANFIS gives higher performance than the events using only FIS in the prediction of terrorism events.
* IEEE Publication format, ISSN 1947 5500, http://sites.google.com/site/ijcsis/
Novel Intrusion Detection using Probabilistic Neural Network and Adaptive Boosting
Nov 03, 2009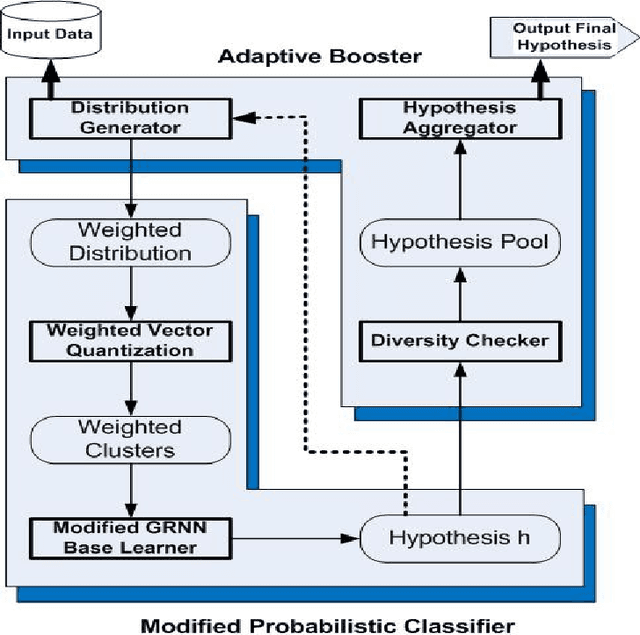
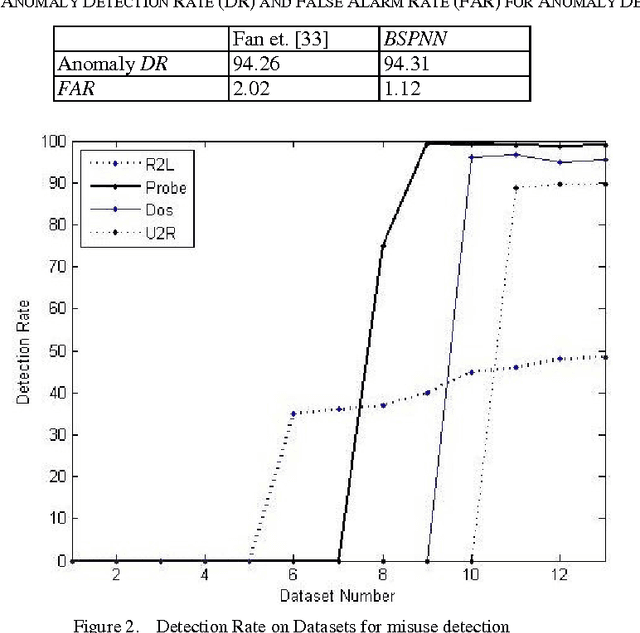
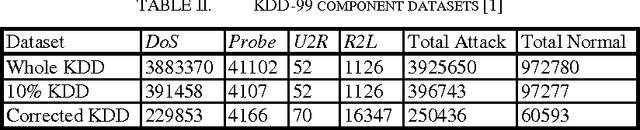
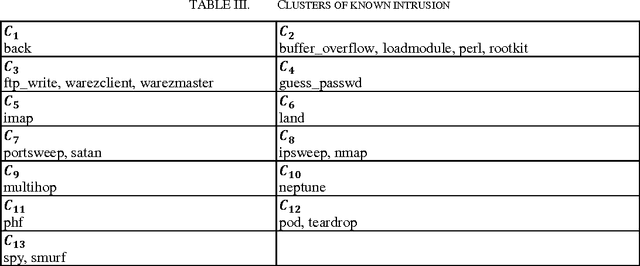
This article applies Machine Learning techniques to solve Intrusion Detection problems within computer networks. Due to complex and dynamic nature of computer networks and hacking techniques, detecting malicious activities remains a challenging task for security experts, that is, currently available defense systems suffer from low detection capability and high number of false alarms. To overcome such performance limitations, we propose a novel Machine Learning algorithm, namely Boosted Subspace Probabilistic Neural Network (BSPNN), which integrates an adaptive boosting technique and a semi parametric neural network to obtain good tradeoff between accuracy and generality. As the result, learning bias and generalization variance can be significantly minimized. Substantial experiments on KDD 99 intrusion benchmark indicate that our model outperforms other state of the art learning algorithms, with significantly improved detection accuracy, minimal false alarms and relatively small computational complexity.
* 9 pages IEEE format, International Journal of Computer Science and Information Security, IJCSIS 2009, ISSN 1947 5500, Impact Factor 0.423, http://sites.google.com/site/ijcsis/