 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Images: What Humans and Machines See When They Look at the Same Image
May 07, 2026The misuse of generative AI in online disinformation campaigns highlights the urgent need for transparent and explainable detection systems. In this work, we investigate how detectors for AI-generated images can be more effective in providing human-understandable explanations for their predictions. To this end, we develop a suite of detectors with various architectures and fine-tuning strategies, trained on our large-scale photorealistic fake image dataset, AIText2Image, and assess their performance on state-of-the-art text-to-image AI generators. We integrate 16 different explainable AI (XAI) methods into our detection framework, and the visual explanations are comprehensively refined and evaluated through a novel approach that prioritizes human understanding of AI-generated images, using both textual and visual responses collected from a survey of 100 participants. This framework offers insights into visual-language cues in fake image detection and into the clarity of XAI methods from a human perspective, measuring the alignment of XAI outputs with human preferences.
Environmental Sound Deepfake Detection Using Deep-Learning Framework
Apr 21, 2026In this paper, we propose a deep-learning framework for environmental sound deepfake detection (ESDD) -- the task of identifying whether the sound scene and sound event in an input audio recording is fake or not. To this end, we conducted extensive experiments to explore how individual spectrograms, a wide range of network architectures and pre-trained models, ensemble of spectrograms or network architectures affect the ESDD task performance. The experimental results on the benchmark datasets of EnvSDD and ESDD-Challenge-TestSet indicate that detecting deepfake audio of sound scene and detecting deepfake audio of sound event should be considered as individual tasks. We also indicate that the approach of finetuning a pre-trained model is more effective compared with training a model from scratch for the ESDD task. Eventually, our best model, which was finetuned from the pre-trained WavLM model with the proposed three-stage training strategy, achieve the Accuracy of 0.98, F1 Score of 0.95, AuC of 0.99 on EnvSDD Test subset and the Accuracy of 0.88, F1 Score of 0.77, and AuC of 0.92 on ESDD-Challenge-TestSet dataset.
A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Mar 29, 2026In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Aud-Sur: An Audio Analyzer Assistant for Audio Surveillance Applications
Mar 31, 2025



In this paper, we present an audio analyzer assistant tool designed for a wide range of audio-based surveillance applications (This work is a part of our DEFAME FAKES and EUCINF projects). The proposed tool, refered to as Aud-Sur, comprises two main phases Audio Analysis and Audio Retrieval, respectively. In the first phase, multiple open-source audio models are leveraged to extract information from input audio recording uploaded by a user. In the second phase, users interact with the Aud-Sur tool via a natural question-and-answer manner, powered by a large language model (LLM), to retrieve the information extracted from the processed audio file. The Aud-Sur tool was deployed using Docker on a microservices-based architecture design. By leveraging open-source audio models for information extraction, LLM for audio information retrieval, and a microservices-based deployment approach, the proposed Aud-Sur tool offers a highly extensible and adaptable framework that can integrate more audio tasks, and be widely shared within the audio community for further development.
DF-Net: The Digital Forensics Network for Image Forgery Detection
Mar 28, 2025The orchestrated manipulation of public opinion, particularly through manipulated images, often spread via online social networks (OSN), has become a serious threat to society. In this paper we introduce the Digital Forensics Net (DF-Net), a deep neural network for pixel-wise image forgery detection. The released model outperforms several state-of-the-art methods on four established benchmark datasets. Most notably, DF-Net's detection is robust against lossy image operations (e.g resizing, compression) as they are automatically performed by social networks.
* Published in 2023 at the 25th Irish Machine Vision and Image Processing Conference (IMVIP), https://iprcs.github.io/pdf/IMVIP2023_Proceeding.pdf
DF2023: The Digital Forensics 2023 Dataset for Image Forgery Detection
Mar 28, 2025



The deliberate manipulation of public opinion, especially through altered images, which are frequently disseminated through online social networks, poses a significant danger to society. To fight this issue on a technical level we support the research community by releasing the Digital Forensics 2023 (DF2023) training and validation dataset, comprising one million images from four major forgery categories: splicing, copy-move, enhancement and removal. This dataset enables an objective comparison of network architectures and can significantly reduce the time and effort of researchers preparing datasets.
* Published at the 25th Irish Machine Vision and Image Processing Conference (IMVIP) --- Proceedings: https://iprcs.github.io/pdf/IMVIP2023_Proceeding.pdf --- Dataset download: https://zenodo.org/records/7326540/files/DF2023_train.zip https://zenodo.org/records/7326540/files/DF2023_val.zip Kaggle: https://www.kaggle.com/datasets/davidfischinger/df2023-digital-forensics-2023-dataset/data
DIN-CTS: Low-Complexity Depthwise-Inception Neural Network with Contrastive Training Strategy for Deepfake Speech Detection
Feb 27, 2025In this paper, we propose a deep neural network approach for deepfake speech detection (DSD) based on a lowcomplexity Depthwise-Inception Network (DIN) trained with a contrastive training strategy (CTS). In this framework, input audio recordings are first transformed into spectrograms using Short-Time Fourier Transform (STFT) and Linear Filter (LF), which are then used to train the DIN. Once trained, the DIN processes bonafide utterances to extract audio embeddings, which are used to construct a Gaussian distribution representing genuine speech. Deepfake detection is then performed by computing the distance between a test utterance and this distribution to determine whether the utterance is fake or bonafide. To evaluate our proposed systems, we conducted extensive experiments on the benchmark dataset of ASVspoof 2019 LA. The experimental results demonstrate the effectiveness of combining the Depthwise-Inception Network with the contrastive learning strategy in distinguishing between fake and bonafide utterances. We achieved Equal Error Rate (EER), Accuracy (Acc.), F1, AUC scores of 4.6%, 95.4%, 97.3%, and 98.9% respectively using a single, low-complexity DIN with just 1.77 M parameters and 985 M FLOPS on short audio segments (4 seconds). Furthermore, our proposed system outperforms the single-system submissions in the ASVspoof 2019 LA challenge, showcasing its potential for real-time applications.
Multi-Modal Video Forensic Platform for Investigating Post-Terrorist Attack Scenarios
Apr 02, 2020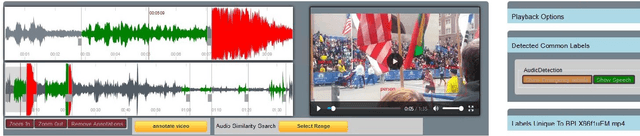
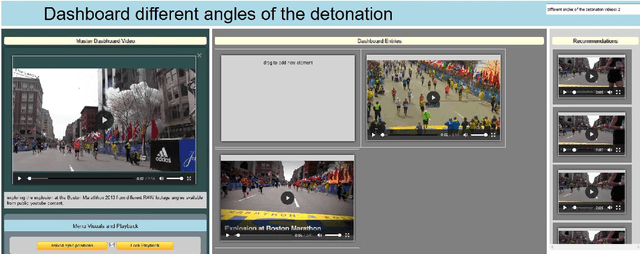
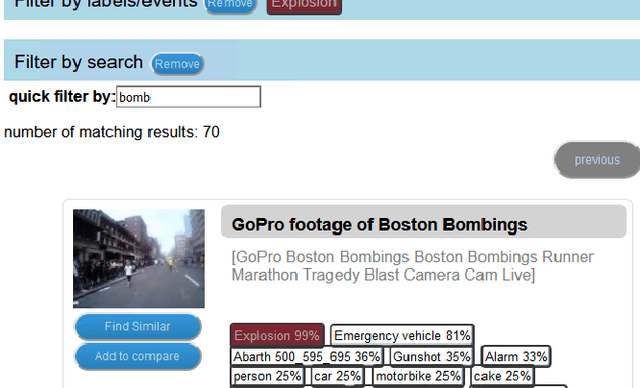
The forensic investigation of a terrorist attack poses a significant challenge to the investigative authorities, as often several thousand hours of video footage must be viewed. Large scale Video Analytic Platforms (VAP) assist law enforcement agencies (LEA) in identifying suspects and securing evidence. Current platforms focus primarily on the integration of different computer vision methods and thus are restricted to a single modality. We present a video analytic platform that integrates visual and audio analytic modules and fuses information from surveillance cameras and video uploads from eyewitnesses. Videos are analyzed according their acoustic and visual content. Specifically, Audio Event Detection is applied to index the content according to attack-specific acoustic concepts. Audio similarity search is utilized to identify similar video sequences recorded from different perspectives. Visual object detection and tracking are used to index the content according to relevant concepts. Innovative user-interface concepts are introduced to harness the full potential of the heterogeneous results of the analytical modules, allowing investigators to more quickly follow-up on leads and eyewitness reports.
Large Scale Audio-Visual Video Analytics Platform for Forensic Investigations of Terroristic Attacks
Nov 28, 2018
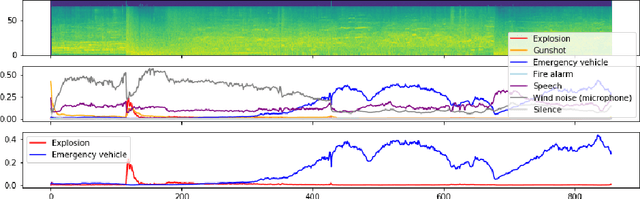
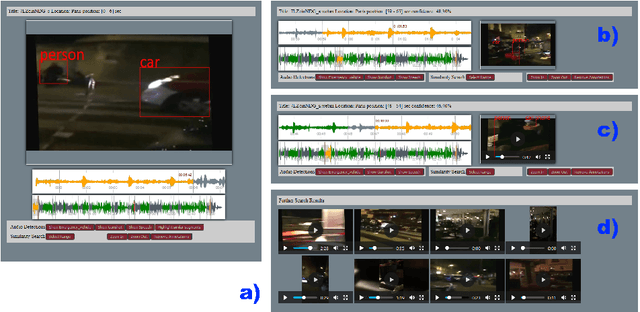

The forensic investigation of a terrorist attack poses a huge challenge to the investigative authorities, as several thousand hours of video footage need to be spotted. To assist law enforcement agencies (LEA) in identifying suspects and securing evidences, we present a platform which fuses information of surveillance cameras and video uploads from eyewitnesses. The platform integrates analytical modules for different input-modalities on a scalable architecture. Videos are analyzed according their acoustic and visual content. Specifically, Audio Event Detection is applied to index the content according to attack-specific acoustic concepts. Audio similarity search is utilized to identify similar video sequences recorded from different perspectives. Visual object detection and tracking are used to index the content according to relevant concepts. The heterogeneous results of the analytical modules are fused into a distributed index of visual and acoustic concepts to facilitate rapid start of investigations, following traits and investigating witness reports.