 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Generated Images: What Humans and Machines See When They Look at the Same Image
May 07, 2026The misuse of generative AI in online disinformation campaigns highlights the urgent need for transparent and explainable detection systems. In this work, we investigate how detectors for AI-generated images can be more effective in providing human-understandable explanations for their predictions. To this end, we develop a suite of detectors with various architectures and fine-tuning strategies, trained on our large-scale photorealistic fake image dataset, AIText2Image, and assess their performance on state-of-the-art text-to-image AI generators. We integrate 16 different explainable AI (XAI) methods into our detection framework, and the visual explanations are comprehensively refined and evaluated through a novel approach that prioritizes human understanding of AI-generated images, using both textual and visual responses collected from a survey of 100 participants. This framework offers insights into visual-language cues in fake image detection and into the clarity of XAI methods from a human perspective, measuring the alignment of XAI outputs with human preferences.
Environmental Sound Deepfake Detection Using Deep-Learning Framework
Apr 21, 2026In this paper, we propose a deep-learning framework for environmental sound deepfake detection (ESDD) -- the task of identifying whether the sound scene and sound event in an input audio recording is fake or not. To this end, we conducted extensive experiments to explore how individual spectrograms, a wide range of network architectures and pre-trained models, ensemble of spectrograms or network architectures affect the ESDD task performance. The experimental results on the benchmark datasets of EnvSDD and ESDD-Challenge-TestSet indicate that detecting deepfake audio of sound scene and detecting deepfake audio of sound event should be considered as individual tasks. We also indicate that the approach of finetuning a pre-trained model is more effective compared with training a model from scratch for the ESDD task. Eventually, our best model, which was finetuned from the pre-trained WavLM model with the proposed three-stage training strategy, achieve the Accuracy of 0.98, F1 Score of 0.95, AuC of 0.99 on EnvSDD Test subset and the Accuracy of 0.88, F1 Score of 0.77, and AuC of 0.92 on ESDD-Challenge-TestSet dataset.
A General Model for Deepfake Speech Detection: Diverse Bonafide Resources or Diverse AI-Based Generators
Mar 29, 2026In this paper, we analyze two main factors of Bonafide Resource (BR) or AI-based Generator (AG) which affect the performance and the generality of a Deepfake Speech Detection (DSD) model. To this end, we first propose a deep-learning based model, referred to as the baseline. Then, we conducted experiments on the baseline by which we indicate how Bonafide Resource (BR) and AI-based Generator (AG) factors affect the threshold score used to detect fake or bonafide input audio in the inference process. Given the experimental results, a dataset, which re-uses public Deepfake Speech Detection (DSD) datasets and shows a balance between Bonafide Resource (BR) or AI-based Generator (AG), is proposed. We then train various deep-learning based models on the proposed dataset and conduct cross-dataset evaluation on different benchmark datasets. The cross-dataset evaluation results prove that the balance of Bonafide Resources (BR) and AI-based Generators (AG) is the key factor to train and achieve a general Deepfake Speech Detection (DSD) model.
Aud-Sur: An Audio Analyzer Assistant for Audio Surveillance Applications
Mar 31, 2025



In this paper, we present an audio analyzer assistant tool designed for a wide range of audio-based surveillance applications (This work is a part of our DEFAME FAKES and EUCINF projects). The proposed tool, refered to as Aud-Sur, comprises two main phases Audio Analysis and Audio Retrieval, respectively. In the first phase, multiple open-source audio models are leveraged to extract information from input audio recording uploaded by a user. In the second phase, users interact with the Aud-Sur tool via a natural question-and-answer manner, powered by a large language model (LLM), to retrieve the information extracted from the processed audio file. The Aud-Sur tool was deployed using Docker on a microservices-based architecture design. By leveraging open-source audio models for information extraction, LLM for audio information retrieval, and a microservices-based deployment approach, the proposed Aud-Sur tool offers a highly extensible and adaptable framework that can integrate more audio tasks, and be widely shared within the audio community for further development.
DF-Net: The Digital Forensics Network for Image Forgery Detection
Mar 28, 2025The orchestrated manipulation of public opinion, particularly through manipulated images, often spread via online social networks (OSN), has become a serious threat to society. In this paper we introduce the Digital Forensics Net (DF-Net), a deep neural network for pixel-wise image forgery detection. The released model outperforms several state-of-the-art methods on four established benchmark datasets. Most notably, DF-Net's detection is robust against lossy image operations (e.g resizing, compression) as they are automatically performed by social networks.
* Published in 2023 at the 25th Irish Machine Vision and Image Processing Conference (IMVIP), https://iprcs.github.io/pdf/IMVIP2023_Proceeding.pdf
DF2023: The Digital Forensics 2023 Dataset for Image Forgery Detection
Mar 28, 2025



The deliberate manipulation of public opinion, especially through altered images, which are frequently disseminated through online social networks, poses a significant danger to society. To fight this issue on a technical level we support the research community by releasing the Digital Forensics 2023 (DF2023) training and validation dataset, comprising one million images from four major forgery categories: splicing, copy-move, enhancement and removal. This dataset enables an objective comparison of network architectures and can significantly reduce the time and effort of researchers preparing datasets.
* Published at the 25th Irish Machine Vision and Image Processing Conference (IMVIP) --- Proceedings: https://iprcs.github.io/pdf/IMVIP2023_Proceeding.pdf --- Dataset download: https://zenodo.org/records/7326540/files/DF2023_train.zip https://zenodo.org/records/7326540/files/DF2023_val.zip Kaggle: https://www.kaggle.com/datasets/davidfischinger/df2023-digital-forensics-2023-dataset/data
EasyLabel: A Semi-Automatic Pixel-wise Object Annotation Tool for Creating Robotic RGB-D Datasets
Mar 01, 2019

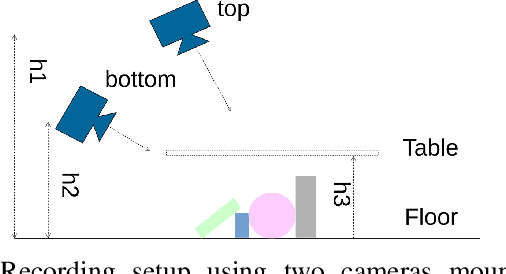
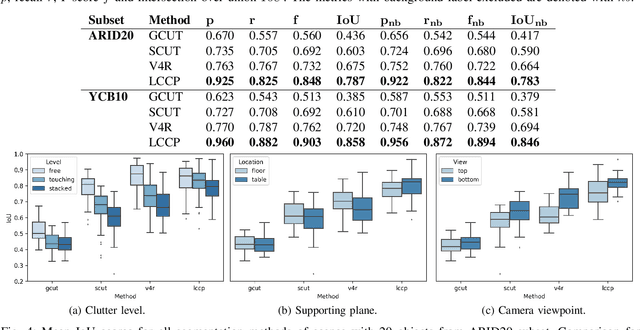
Developing robot perception systems for recognizing objects in the real-world requires computer vision algorithms to be carefully scrutinized with respect to the expected operating domain. This demands large quantities of ground truth data to rigorously evaluate the performance of algorithms. This paper presents the EasyLabel tool for easily acquiring high quality ground truth annotation of objects at the pixel-level in densely cluttered scenes. In a semi-automatic process, complex scenes are incrementally built and EasyLabel exploits depth change to extract precise object masks at each step. We use this tool to generate the Object Cluttered Indoor Dataset (OCID) that captures diverse settings of objects, background, context, sensor to scene distance, viewpoint angle and lighting conditions. OCID is used to perform a systematic comparison of existing object segmentation methods. The baseline comparison supports the need for pixel- and object-wise annotation to progress robot vision towards realistic applications. This insight reveals the usefulness of EasyLabel and OCID to better understand the challenges that robots face in the real-world. Copyright 20XX IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works.