 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Exact Invariances in Polynomial Time
Feb 27, 2025We study the statistical-computational trade-offs for learning with exact invariances (or symmetries) using kernel regression. Traditional methods, such as data augmentation, group averaging, canonicalization, and frame-averaging, either fail to provide a polynomial-time solution or are not applicable in the kernel setting. However, with oracle access to the geometric properties of the input space, we propose a polynomial-time algorithm that learns a classifier with \emph{exact} invariances. Moreover, our approach achieves the same excess population risk (or generalization error) as the original kernel regression problem. To the best of our knowledge, this is the first polynomial-time algorithm to achieve exact (not approximate) invariances in this context. Our proof leverages tools from differential geometry, spectral theory, and optimization. A key result in our development is a new reformulation of the problem of learning under invariances as optimizing an infinite number of linearly constrained convex quadratic programs, which may be of independent interest.
A Universal Class of Sharpness-Aware Minimization Algorithms
Jun 06, 2024Recently, there has been a surge in interest in developing optimization algorithms for overparameterized models as achieving generalization is believed to require algorithms with suitable biases. This interest centers on minimizing sharpness of the original loss function; the Sharpness-Aware Minimization (SAM) algorithm has proven effective. However, most literature only considers a few sharpness measures, such as the maximum eigenvalue or trace of the training loss Hessian, which may not yield meaningful insights for non-convex optimization scenarios like neural networks. Additionally, many sharpness measures are sensitive to parameter invariances in neural networks, magnifying significantly under rescaling parameters. Motivated by these challenges, we introduce a new class of sharpness measures in this paper, leading to new sharpness-aware objective functions. We prove that these measures are \textit{universally expressive}, allowing any function of the training loss Hessian matrix to be represented by appropriate hyperparameters. Furthermore, we show that the proposed objective functions explicitly bias towards minimizing their corresponding sharpness measures, and how they allow meaningful applications to models with parameter invariances (such as scale-invariances). Finally, as instances of our proposed general framework, we present \textit{Frob-SAM} and \textit{Det-SAM}, which are specifically designed to minimize the Frobenius norm and the determinant of the Hessian of the training loss, respectively. We also demonstrate the advantages of our general framework through extensive experiments.
Coded Computing: A Learning-Theoretic Framework
Jun 01, 2024



Coded computing has emerged as a promising framework for tackling significant challenges in large-scale distributed computing, including the presence of slow, faulty, or compromised servers. In this approach, each worker node processes a combination of the data, rather than the raw data itself. The final result then is decoded from the collective outputs of the worker nodes. However, there is a significant gap between current coded computing approaches and the broader landscape of general distributed computing, particularly when it comes to machine learning workloads. To bridge this gap, we propose a novel foundation for coded computing, integrating the principles of learning theory, and developing a new framework that seamlessly adapts with machine learning applications. In this framework, the objective is to find the encoder and decoder functions that minimize the loss function, defined as the mean squared error between the estimated and true values. Facilitating the search for the optimum decoding and functions, we show that the loss function can be upper-bounded by the summation of two terms: the generalization error of the decoding function and the training error of the encoding function. Focusing on the second-order Sobolev space, we then derive the optimal encoder and decoder. We show that in the proposed solution, the mean squared error of the estimation decays with the rate of $O(S^4 N^{-3})$ and $O(S^{\frac{8}{5}}N^{\frac{-3}{5}})$ in noiseless and noisy computation settings, respectively, where $N$ is the number of worker nodes with at most $S$ slow servers (stragglers). Finally, we evaluate the proposed scheme on inference tasks for various machine learning models and demonstrate that the proposed framework outperforms the state-of-the-art in terms of accuracy and rate of convergence.
Sample Complexity Bounds for Estimating Probability Divergences under Invariances
Nov 06, 2023
Group-invariant probability distributions appear in many data-generative models in machine learning, such as graphs, point clouds, and images. In practice, one often needs to estimate divergences between such distributions. In this work, we study how the inherent invariances, with respect to any smooth action of a Lie group on a manifold, improve sample complexity when estimating the Wasserstein distance, the Sobolev Integral Probability Metrics (Sobolev IPMs), the Maximum Mean Discrepancy (MMD), and also the complexity of the density estimation problem (in the $L^2$ and $L^\infty$ distance). Our results indicate a two-fold gain: (1) reducing the sample complexity by a multiplicative factor corresponding to the group size (for finite groups) or the normalized volume of the quotient space (for groups of positive dimension); (2) improving the exponent in the convergence rate (for groups of positive dimension). These results are completely new for groups of positive dimension and extend recent bounds for finite group actions.
The Exact Sample Complexity Gain from Invariances for Kernel Regression on Manifolds
Mar 24, 2023In practice, encoding invariances into models helps sample complexity. In this work, we tighten and generalize theoretical results on how invariances improve sample complexity. In particular, we provide minimax optimal rates for kernel ridge regression on any manifold, with a target function that is invariant to an arbitrary group action on the manifold. Our results hold for (almost) any group action, even groups of positive dimension. For a finite group, the gain increases the "effective" number of samples by the group size. For groups of positive dimension, the gain is observed by a reduction in the manifold's dimension, in addition to a factor proportional to the volume of the quotient space. Our proof takes the viewpoint of differential geometry, in contrast to the more common strategy of using invariant polynomials. Hence, this new geometric viewpoint on learning with invariances may be of independent interest.
Counting Substructures with Higher-Order Graph Neural Networks: Possibility and Impossibility Results
Dec 06, 2020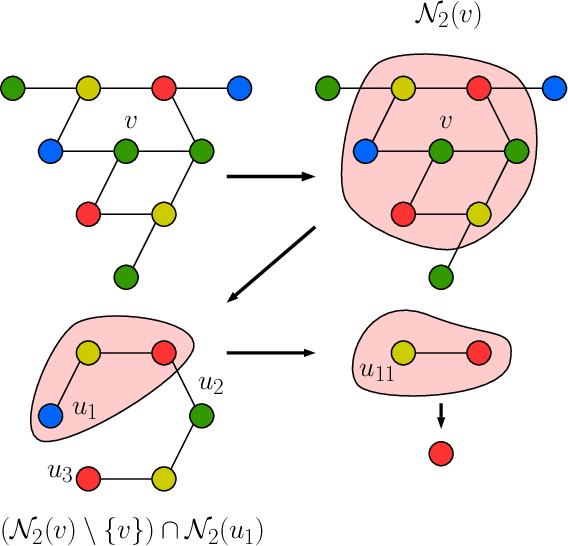
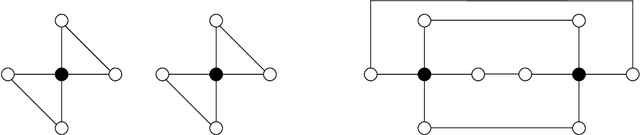
While massage passing based Graph Neural Networks (GNNs) have become increasingly popular architectures for learning with graphs, recent works have revealed important shortcomings in their expressive power. In response, several higher-order GNNs have been proposed, which substantially increase the expressive power, but at a large computational cost. Motivated by this gap, we introduce and analyze a new recursive pooling technique of local neighborhoods that allows different tradeoffs of computational cost and expressive power. First, we show that this model can count subgraphs of size $k$, and thereby overcomes a known limitation of low-order GNNs. Second, we prove that, in several cases, the proposed algorithm can greatly reduce computational complexity compared to the existing higher-order $k$-GNN and Local Relational Pooling (LRP) networks. We also provide a (near) matching information-theoretic lower bound for graph representations that can provably count subgraphs, and discuss time complexity lower bounds as well.