 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Execution through Neural Code Fusion
Jun 17, 2019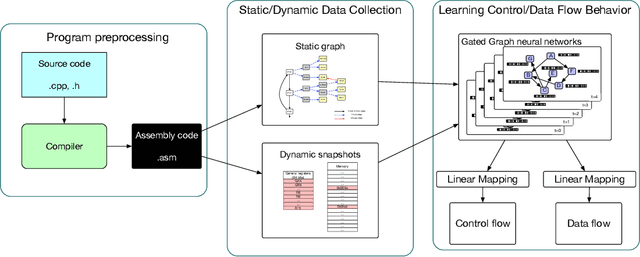
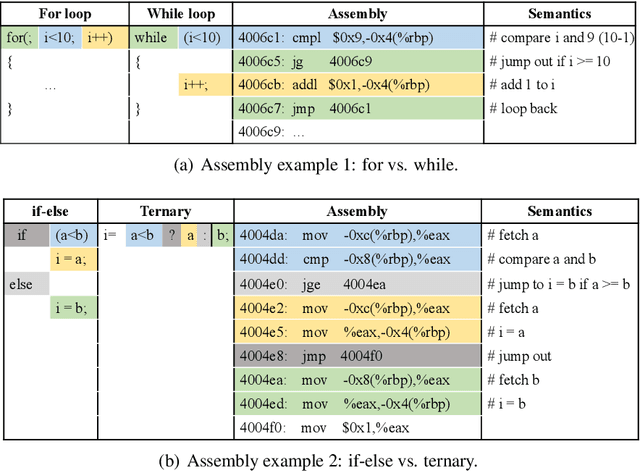
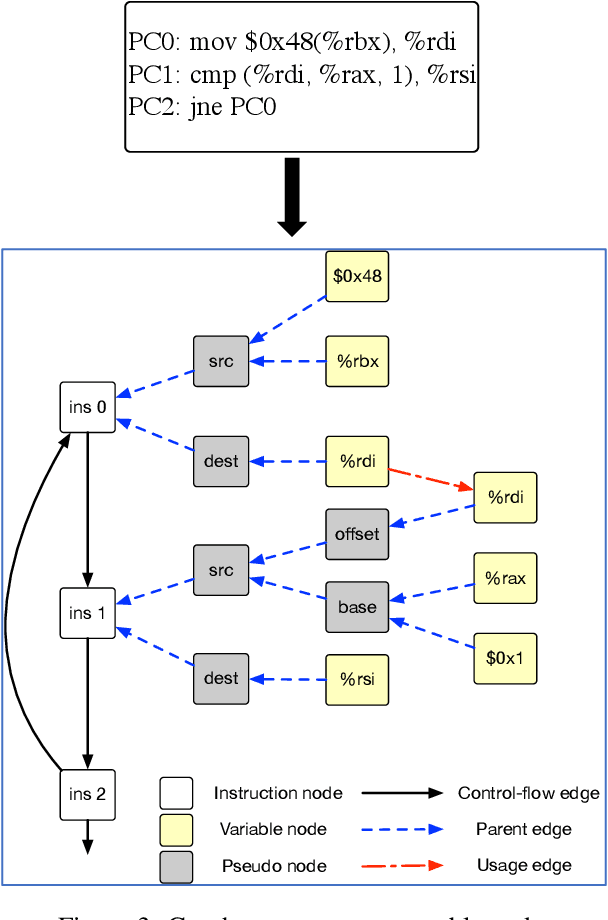
As the performance of computer systems stagnates due to the end of Moore's Law, there is a need for new models that can understand and optimize the execution of general purpose code. While there is a growing body of work on using Graph Neural Networks (GNNs) to learn representations of source code, these representations do not understand how code dynamically executes. In this work, we propose a new approach to use GNNs to learn fused representations of general source code and its execution. Our approach defines a multi-task GNN over low-level representations of source code and program state (i.e., assembly code and dynamic memory states), converting complex source code constructs and complex data structures into a simpler, more uniform format. We show that this leads to improved performance over similar methods that do not use execution and it opens the door to applying GNN models to new tasks that would not be feasible from static code alone. As an illustration of this, we apply the new model to challenging dynamic tasks (branch prediction and prefetching) from the SPEC CPU benchmark suite, outperforming the state-of-the-art by 26% and 45% respectively. Moreover, we use the learned fused graph embeddings to demonstrate transfer learning with high performance on an indirectly related task (algorithm classification).
Direct Policy Gradients: Direct Optimization of Policies in Discrete Action Spaces
Jun 14, 2019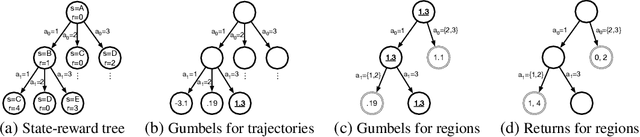
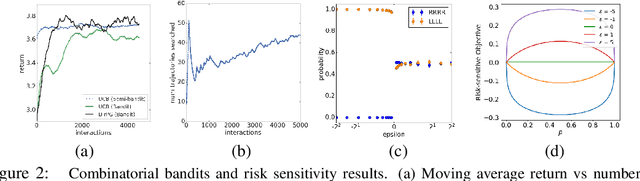
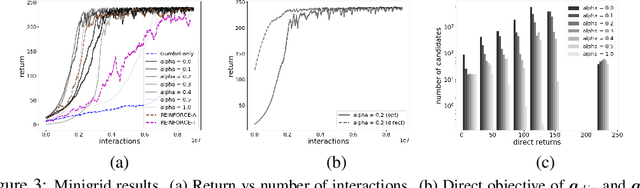
Direct optimization is an appealing approach to differentiating through discrete quantities. Rather than relying on REINFORCE or continuous relaxations of discrete structures, it uses optimization in discrete space to compute gradients through a discrete argmax operation. In this paper, we develop reinforcement learning algorithms that use direct optimization to compute gradients of the expected return in environments with discrete actions. We call the resulting algorithms "direct policy gradient" algorithms and investigate their properties, showing that there is a built-in variance reduction technique and that a parameter that was previously viewed as a numerical approximation can be interpreted as controlling risk sensitivity. We also tackle challenges in algorithm design, leveraging ideas from A$^\star$ Sampling to develop a practical algorithm. Empirically, we show that the algorithm performs well in illustrative domains, and that it can make use of domain knowledge about upper bounds on return-to-go to speed up training.
Neural Networks for Modeling Source Code Edits
Apr 04, 2019
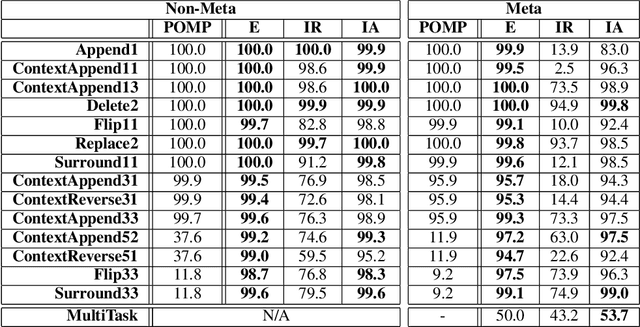

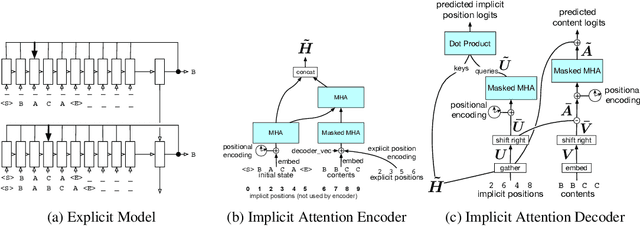
Programming languages are emerging as a challenging and interesting domain for machine learning. A core task, which has received significant attention in recent years, is building generative models of source code. However, to our knowledge, previous generative models have always been framed in terms of generating static snapshots of code. In this work, we instead treat source code as a dynamic object and tackle the problem of modeling the edits that software developers make to source code files. This requires extracting intent from previous edits and leveraging it to generate subsequent edits. We develop several neural networks and use synthetic data to test their ability to learn challenging edit patterns that require strong generalization. We then collect and train our models on a large-scale dataset of Google source code, consisting of millions of fine-grained edits from thousands of Python developers. From the modeling perspective, our main conclusion is that a new composition of attentional and pointer network components provides the best overall performance and scalability. From the application perspective, our results provide preliminary evidence of the feasibility of developing tools that learn to predict future edits.
Graph Partition Neural Networks for Semi-Supervised Classification
Mar 16, 2018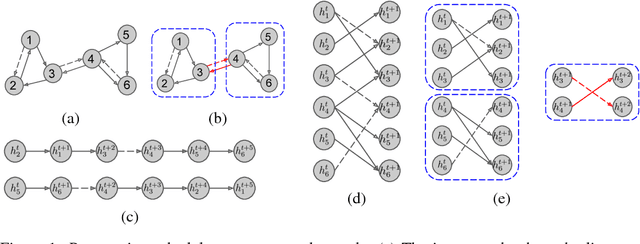

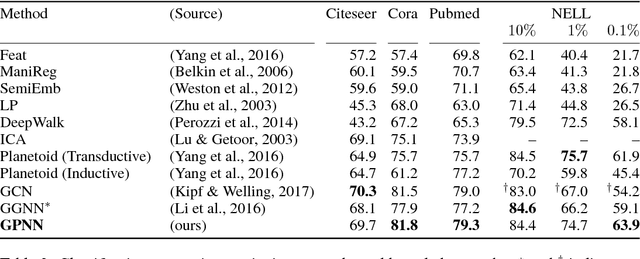
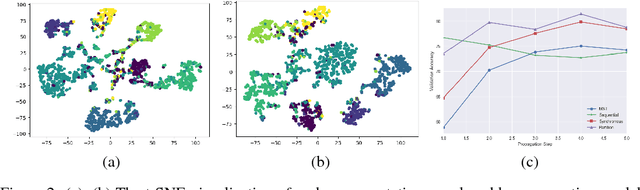
We present graph partition neural networks (GPNN), an extension of graph neural networks (GNNs) able to handle extremely large graphs. GPNNs alternate between locally propagating information between nodes in small subgraphs and globally propagating information between the subgraphs. To efficiently partition graphs, we experiment with several partitioning algorithms and also propose a novel variant for fast processing of large scale graphs. We extensively test our model on a variety of semi-supervised node classification tasks. Experimental results indicate that GPNNs are either superior or comparable to state-of-the-art methods on a wide variety of datasets for graph-based semi-supervised classification. We also show that GPNNs can achieve similar performance as standard GNNs with fewer propagation steps.
Gated Graph Sequence Neural Networks
Sep 22, 2017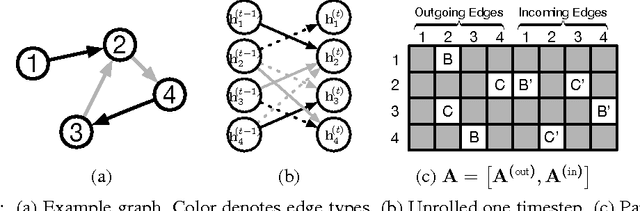
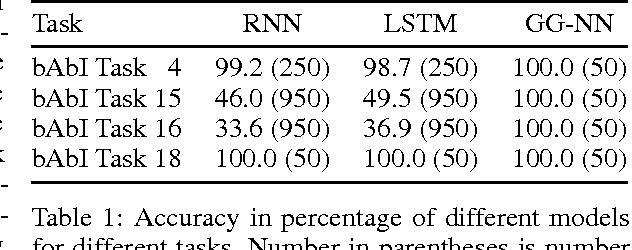
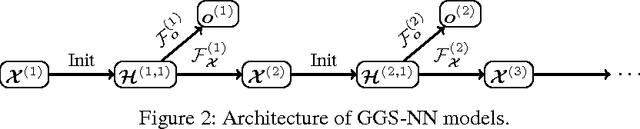

Graph-structured data appears frequently in domains including chemistry, natural language semantics, social networks, and knowledge bases. In this work, we study feature learning techniques for graph-structured inputs. Our starting point is previous work on Graph Neural Networks (Scarselli et al., 2009), which we modify to use gated recurrent units and modern optimization techniques and then extend to output sequences. The result is a flexible and broadly useful class of neural network models that has favorable inductive biases relative to purely sequence-based models (e.g., LSTMs) when the problem is graph-structured. We demonstrate the capabilities on some simple AI (bAbI) and graph algorithm learning tasks. We then show it achieves state-of-the-art performance on a problem from program verification, in which subgraphs need to be matched to abstract data structures.
AMPNet: Asynchronous Model-Parallel Training for Dynamic Neural Networks
Jun 22, 2017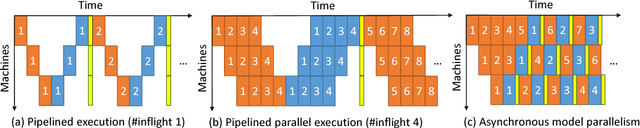
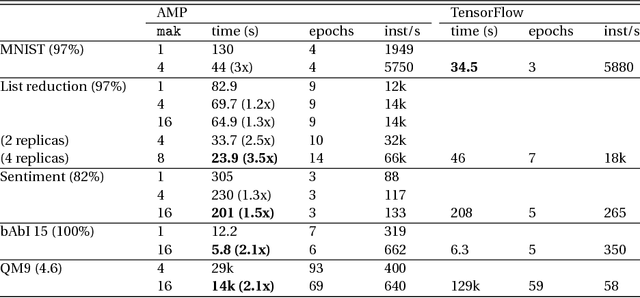
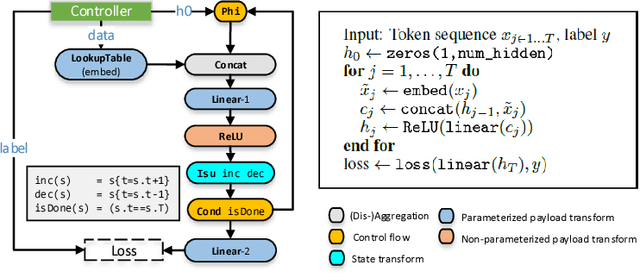
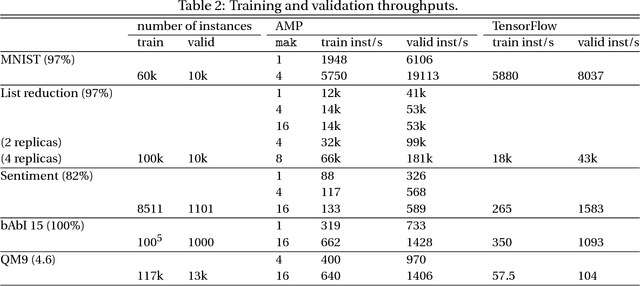
New types of machine learning hardware in development and entering the market hold the promise of revolutionizing deep learning in a manner as profound as GPUs. However, existing software frameworks and training algorithms for deep learning have yet to evolve to fully leverage the capability of the new wave of silicon. We already see the limitations of existing algorithms for models that exploit structured input via complex and instance-dependent control flow, which prohibits minibatching. We present an asynchronous model-parallel (AMP) training algorithm that is specifically motivated by training on networks of interconnected devices. Through an implementation on multi-core CPUs, we show that AMP training converges to the same accuracy as conventional synchronous training algorithms in a similar number of epochs, but utilizes the available hardware more efficiently even for small minibatch sizes, resulting in significantly shorter overall training times. Our framework opens the door for scaling up a new class of deep learning models that cannot be efficiently trained today.
DeepCoder: Learning to Write Programs
Mar 08, 2017


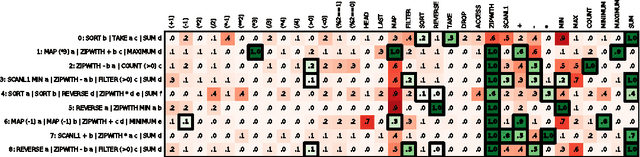
We develop a first line of attack for solving programming competition-style problems from input-output examples using deep learning. The approach is to train a neural network to predict properties of the program that generated the outputs from the inputs. We use the neural network's predictions to augment search techniques from the programming languages community, including enumerative search and an SMT-based solver. Empirically, we show that our approach leads to an order of magnitude speedup over the strong non-augmented baselines and a Recurrent Neural Network approach, and that we are able to solve problems of difficulty comparable to the simplest problems on programming competition websites.
Differentiable Programs with Neural Libraries
Mar 02, 2017
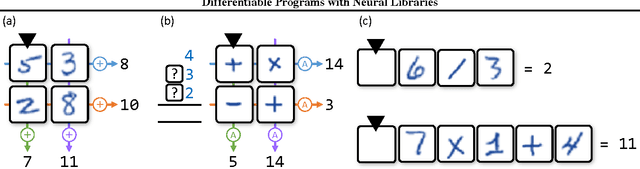

We develop a framework for combining differentiable programming languages with neural networks. Using this framework we create end-to-end trainable systems that learn to write interpretable algorithms with perceptual components. We explore the benefits of inductive biases for strong generalization and modularity that come from the program-like structure of our models. In particular, modularity allows us to learn a library of (neural) functions which grows and improves as more tasks are solved. Empirically, we show that this leads to lifelong learning systems that transfer knowledge to new tasks more effectively than baselines.
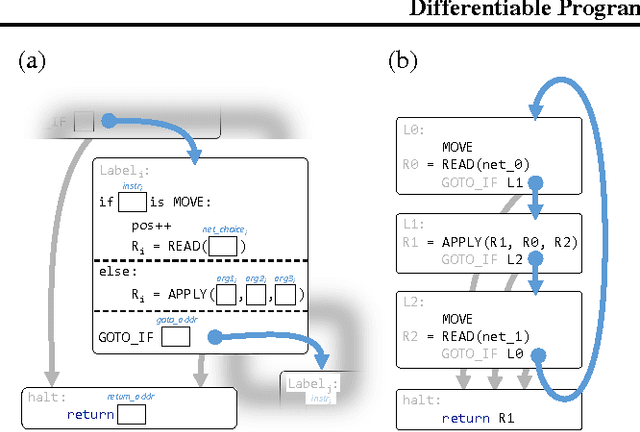
Differentiable Functional Program Interpreters
Mar 02, 2017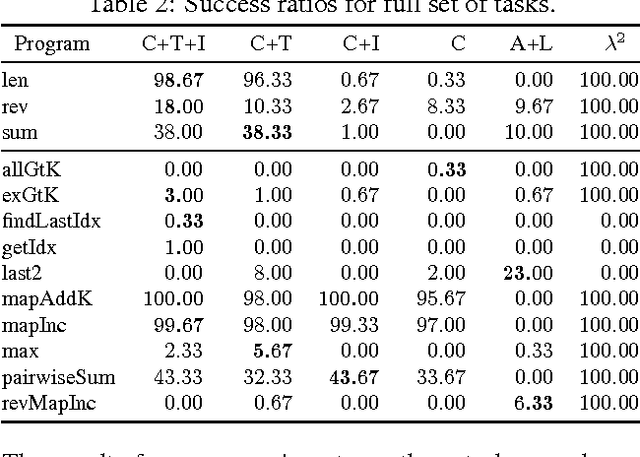
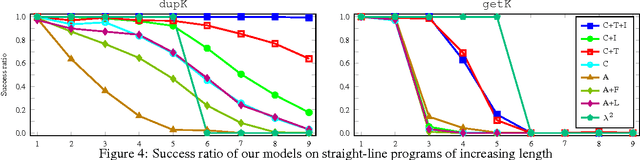
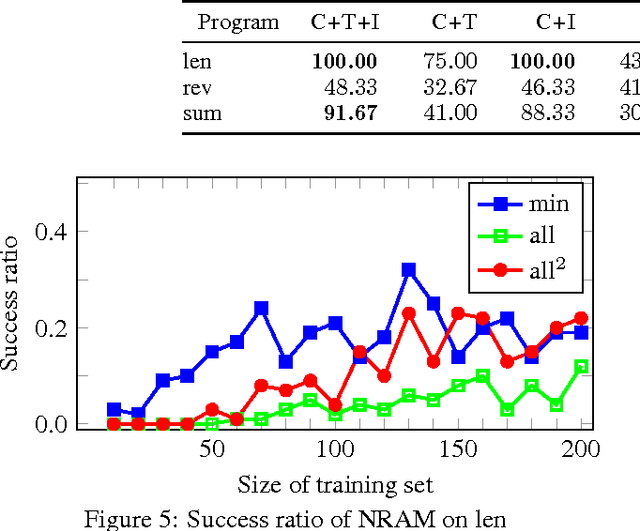

Programming by Example (PBE) is the task of inducing computer programs from input-output examples. It can be seen as a type of machine learning where the hypothesis space is the set of legal programs in some programming language. Recent work on differentiable interpreters relaxes the discrete space of programs into a continuous space so that search over programs can be performed using gradient-based optimization. While conceptually powerful, so far differentiable interpreter-based program synthesis has only been capable of solving very simple problems. In this work, we study modeling choices that arise when constructing a differentiable programming language and their impact on the success of synthesis. The main motivation for the modeling choices comes from functional programming: we study the effect of memory allocation schemes, immutable data, type systems, and built-in control-flow structures. Empirically we show that incorporating functional programming ideas into differentiable programming languages allows us to learn much more complex programs than is possible with existing differentiable languages.
Summary - TerpreT: A Probabilistic Programming Language for Program Induction
Dec 02, 2016
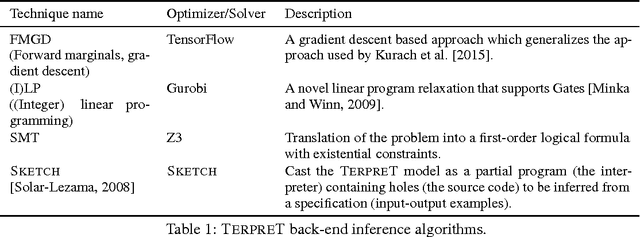
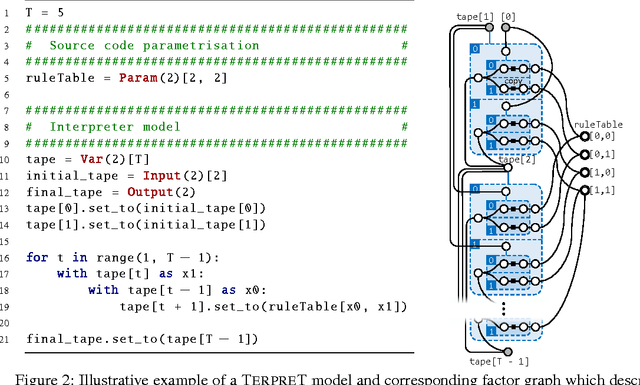
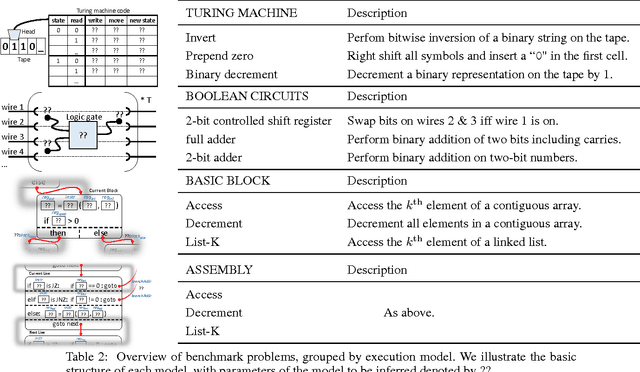
We study machine learning formulations of inductive program synthesis; that is, given input-output examples, synthesize source code that maps inputs to corresponding outputs. Our key contribution is TerpreT, a domain-specific language for expressing program synthesis problems. A TerpreT model is composed of a specification of a program representation and an interpreter that describes how programs map inputs to outputs. The inference task is to observe a set of input-output examples and infer the underlying program. From a TerpreT model we automatically perform inference using four different back-ends: gradient descent (thus each TerpreT model can be seen as defining a differentiable interpreter), linear program (LP) relaxations for graphical models, discrete satisfiability solving, and the Sketch program synthesis system. TerpreT has two main benefits. First, it enables rapid exploration of a range of domains, program representations, and interpreter models. Second, it separates the model specification from the inference algorithm, allowing proper comparisons between different approaches to inference. We illustrate the value of TerpreT by developing several interpreter models and performing an extensive empirical comparison between alternative inference algorithms on a variety of program models. To our knowledge, this is the first work to compare gradient-based search over program space to traditional search-based alternatives. Our key empirical finding is that constraint solvers dominate the gradient descent and LP-based formulations. This is a workshop summary of a longer report at arXiv:1608.04428