 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021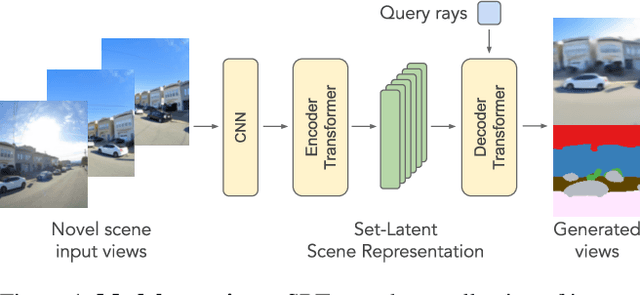

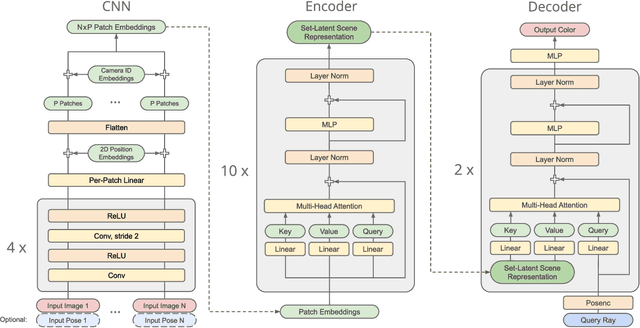
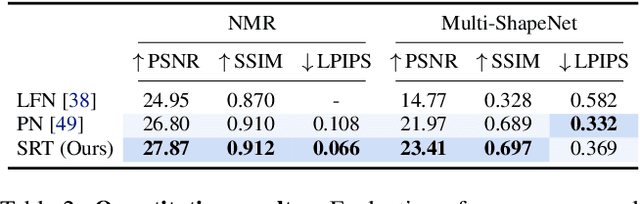
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
Whitening and second order optimization both destroy information about the dataset, and can make generalization impossible
Aug 25, 2020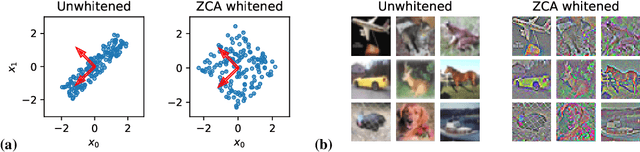
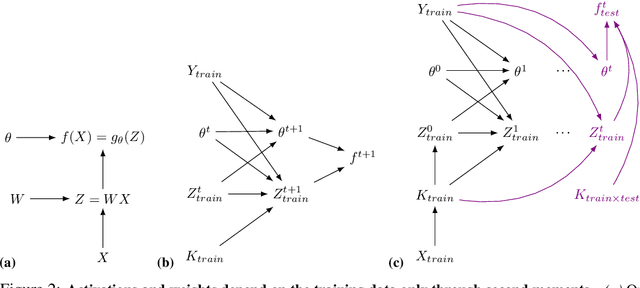
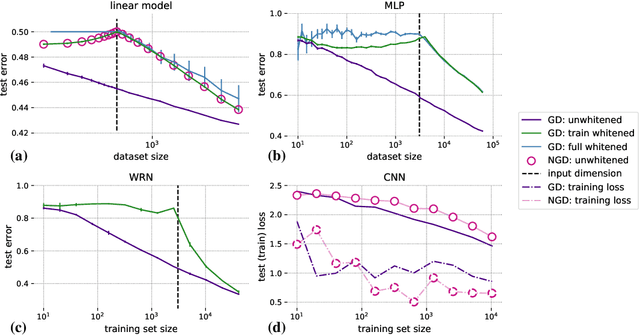
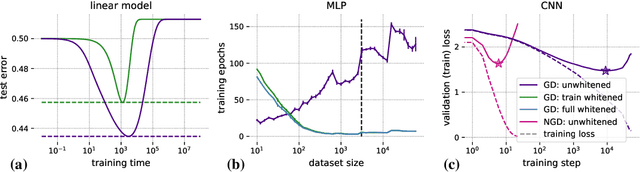
Machine learning is predicated on the concept of generalization: a model achieving low error on a sufficiently large training set should also perform well on novel samples from the same distribution. We show that both data whitening and second order optimization can harm or entirely prevent generalization. In general, model training harnesses information contained in the sample-sample second moment matrix of a dataset. For a general class of models, namely models with a fully connected first layer, we prove that the information contained in this matrix is the only information which can be used to generalize. Models trained using whitened data, or with certain second order optimization schemes, have less access to this information; in the high dimensional regime they have no access at all, producing models that generalize poorly or not at all. We experimentally verify these predictions for several architectures, and further demonstrate that generalization continues to be harmed even when theoretical requirements are relaxed. However, we also show experimentally that regularized second order optimization can provide a practical tradeoff, where training is still accelerated but less information is lost, and generalization can in some circumstances even improve.
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 13, 2020
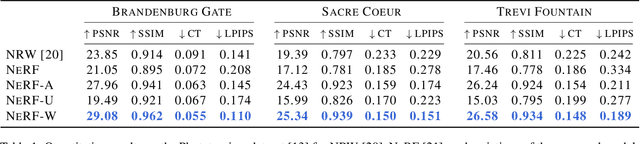

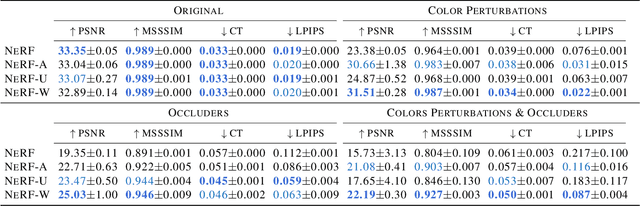
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.
Trading Off Diversity and Quality in Natural Language Generation
Apr 22, 2020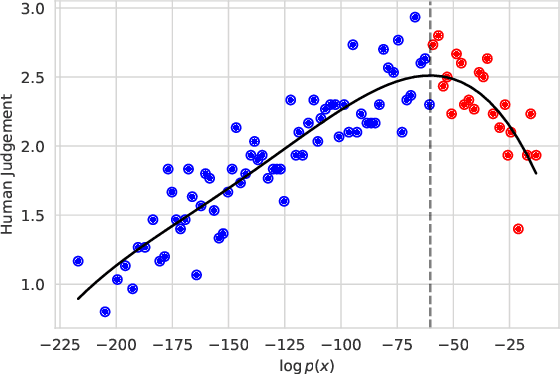

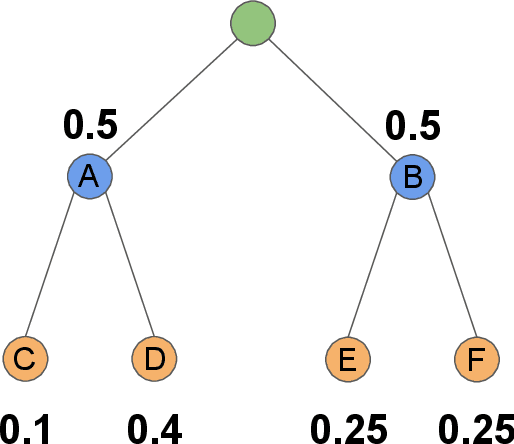
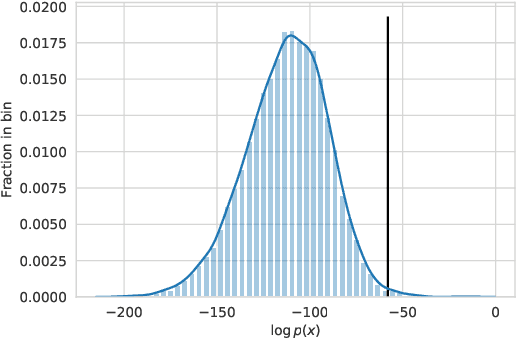
For open-ended language generation tasks such as storytelling and dialogue, choosing the right decoding algorithm is critical to controlling the tradeoff between generation quality and diversity. However, there presently exists no consensus on which decoding procedure is best or even the criteria by which to compare them. We address these issues by casting decoding as a multi-objective optimization problem aiming to simultaneously maximize both response quality and diversity. Our framework enables us to perform the first large-scale evaluation of decoding methods along the entire quality-diversity spectrum. We find that when diversity is a priority, all methods perform similarly, but when quality is viewed as more important, the recently proposed nucleus sampling (Holtzman et al. 2019) outperforms all other evaluated decoding algorithms. Our experiments also confirm the existence of the `likelihood trap', the counter-intuitive observation that high likelihood sequences are often surprisingly low quality. We leverage our findings to create and evaluate an algorithm called \emph{selective sampling} which tractably approximates globally-normalized temperature sampling.
Human and Automatic Detection of Generated Text
Nov 02, 2019
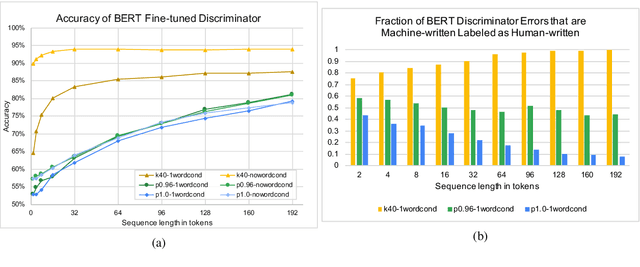
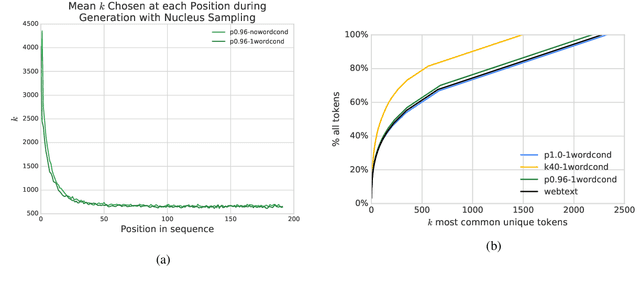
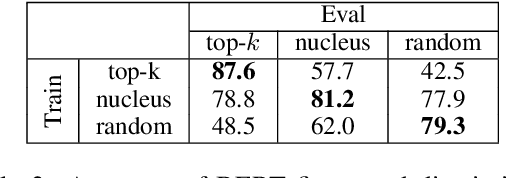
With the advent of generative models with a billion parameters or more, it is now possible to automatically generate vast amounts of human-sounding text. This raises questions into just how human-like is the machine-generated text, and how long does a text excerpt need to be for both humans and automatic discriminators to be able reliably detect that it was machine-generated. In this paper, we conduct a thorough investigation of how choices such as sampling strategy and text excerpt length can impact the performance of automatic detection methods as well as human raters. We find that the sampling strategies which result in more human-like text according to human raters create distributional differences from human-written text that make detection easy for automatic discriminators.
Neural Assistant: Joint Action Prediction, Response Generation, and Latent Knowledge Reasoning
Oct 31, 2019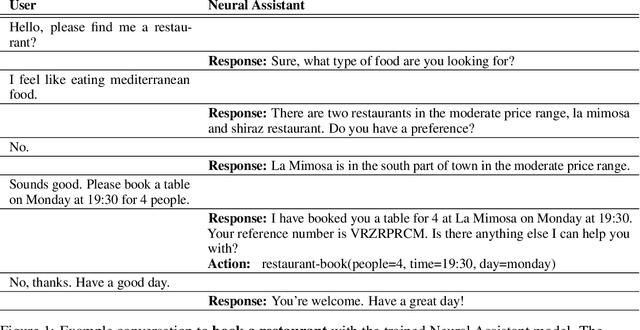
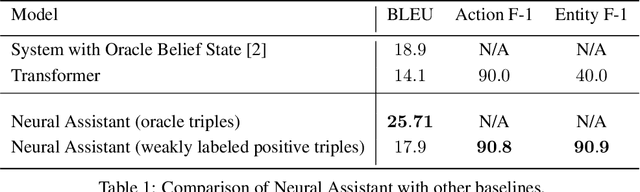
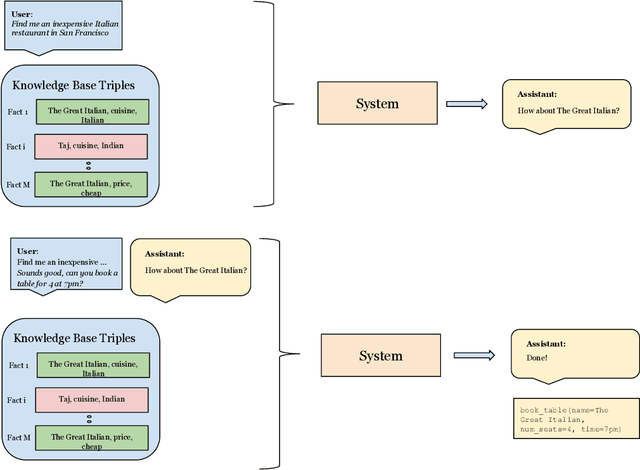
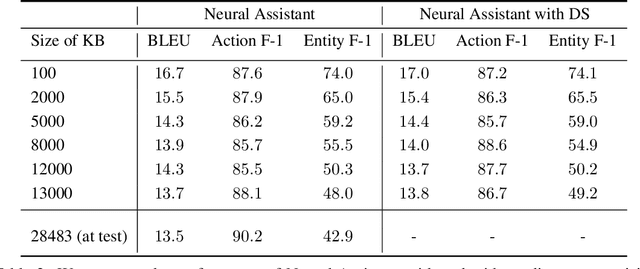
Task-oriented dialog presents a difficult challenge encompassing multiple problems including multi-turn language understanding and generation, knowledge retrieval and reasoning, and action prediction. Modern dialog systems typically begin by converting conversation history to a symbolic object referred to as belief state by using supervised learning. The belief state is then used to reason on an external knowledge source whose result along with the conversation history is used in action prediction and response generation tasks independently. Such a pipeline of individually optimized components not only makes the development process cumbersome but also makes it non-trivial to leverage session-level user reinforcement signals. In this paper, we develop Neural Assistant: a single neural network model that takes conversation history and an external knowledge source as input and jointly produces both text response and action to be taken by the system as output. The model learns to reason on the provided knowledge source with weak supervision signal coming from the text generation and the action prediction tasks, hence removing the need for belief state annotations. In the MultiWOZ dataset, we study the effect of distant supervision, and the size of knowledge base on model performance. We find that the Neural Assistant without belief states is able to incorporate external knowledge information achieving higher factual accuracy scores compared to Transformer. In settings comparable to reported baseline systems, Neural Assistant when provided with oracle belief state significantly improves language generation performance.
Taskmaster-1: Toward a Realistic and Diverse Dialog Dataset
Sep 01, 2019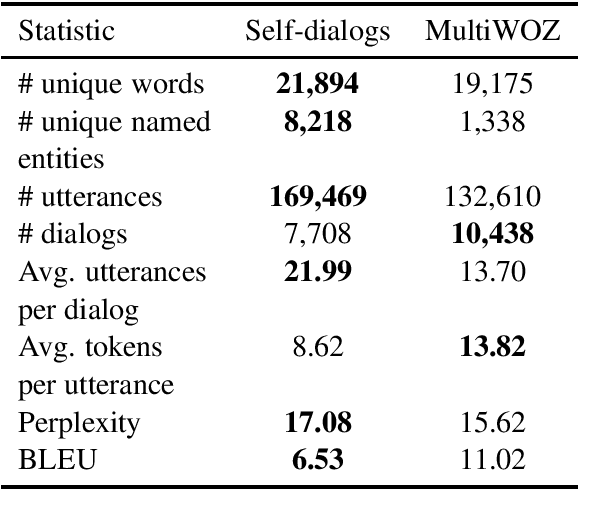

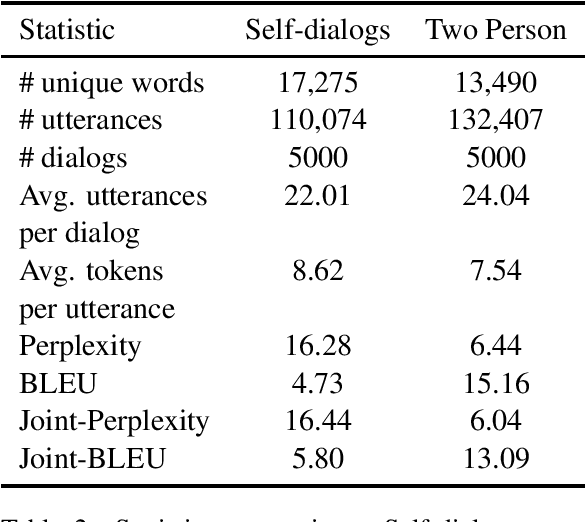
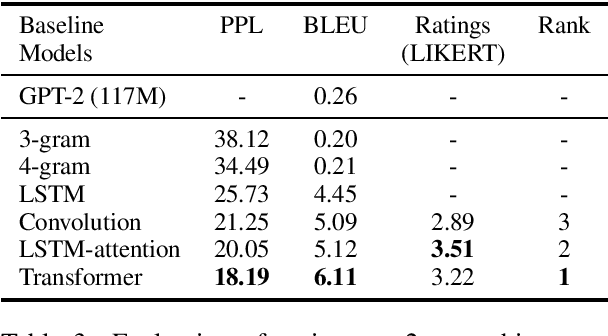
A significant barrier to progress in data-driven approaches to building dialog systems is the lack of high quality, goal-oriented conversational data. To help satisfy this elementary requirement, we introduce the initial release of the Taskmaster-1 dataset which includes 13,215 task-based dialogs comprising six domains. Two procedures were used to create this collection, each with unique advantages. The first involves a two-person, spoken "Wizard of Oz" (WOz) approach in which trained agents and crowdsourced workers interact to complete the task while the second is "self-dialog" in which crowdsourced workers write the entire dialog themselves. We do not restrict the workers to detailed scripts or to a small knowledge base and hence we observe that our dataset contains more realistic and diverse conversations in comparison to existing datasets. We offer several baseline models including state of the art neural seq2seq architectures with benchmark performance as well as qualitative human evaluations. Dialogs are labeled with API calls and arguments, a simple and cost effective approach which avoids the requirement of complex annotation schema. The layer of abstraction between the dialog model and the service provider API allows for a given model to interact with multiple services that provide similar functionally. Finally, the dataset will evoke interest in written vs. spoken language, discourse patterns, error handling and other linguistic phenomena related to dialog system research, development and design.
Parallel Scheduled Sampling
Jun 11, 2019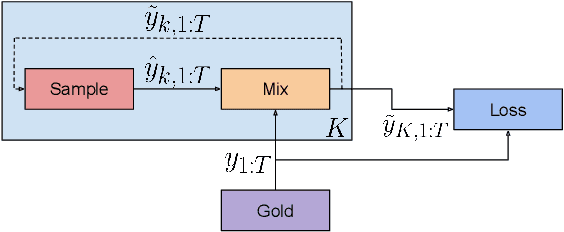
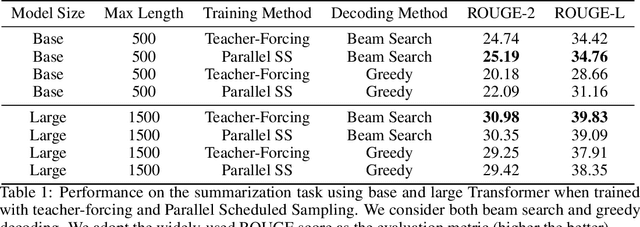
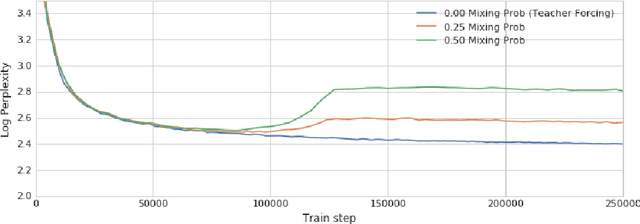
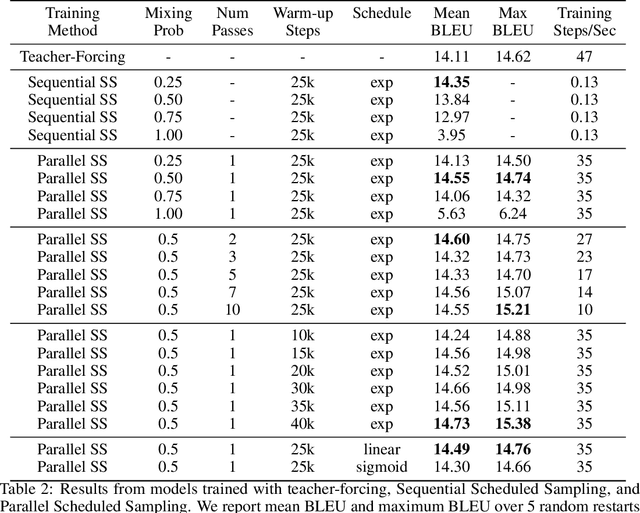
Auto-regressive models are widely used in sequence generation problems. The output sequence is typically generated in a predetermined order, one discrete unit (pixel or word or character) at a time. The models are trained by teacher-forcing where ground-truth history is fed to the model as input, which at test time is replaced by the model prediction. Scheduled Sampling aims to mitigate this discrepancy between train and test time by randomly replacing some discrete units in the history with the model's prediction. While teacher-forced training works well with ML accelerators as the computation can be parallelized across time, Scheduled Sampling involves undesirable sequential processing. In this paper, we introduce a simple technique to parallelize Scheduled Sampling across time. We find that in most cases our technique leads to better empirical performance on summarization and dialog generation tasks compared to teacher-forced training. Further, we discuss the effects of different hyper-parameters associated with Scheduled Sampling on the model performance.
Stochastic natural gradient descent draws posterior samples in function space
Oct 16, 2018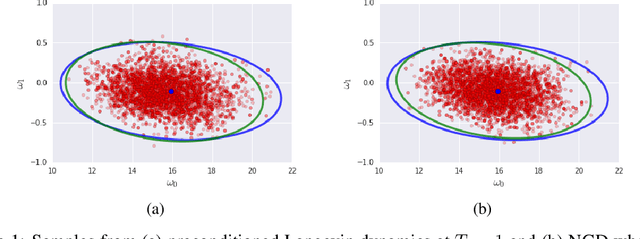
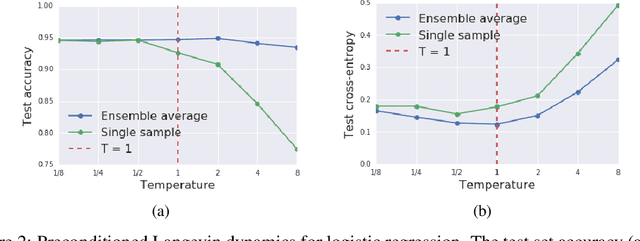
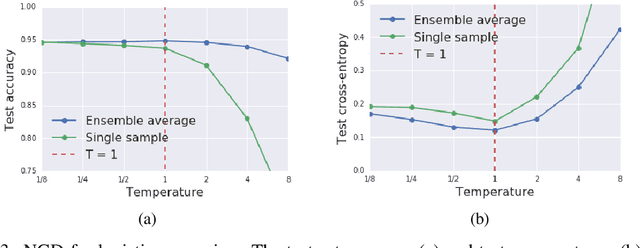
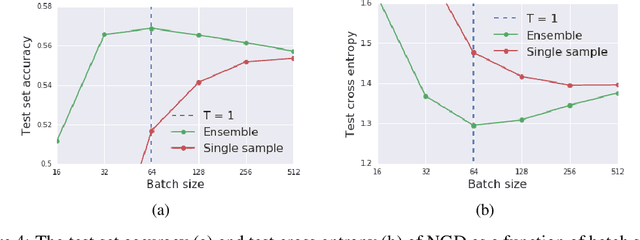
We prove that as the model predictions on the training set approach the true conditional distribution of labels given inputs, the noise inherent in minibatch gradients causes the stationary distribution of natural gradient descent to approach a Bayesian posterior near local minima as the learning rate $\epsilon \rightarrow 0$. The temperature $T \approx \epsilon N/(2B)$ of this posterior is controlled by the learning rate, training set size $N$ and batch size $B$. However minibatch NGD is not parameterisation invariant, and we therefore introduce "stochastic natural gradient descent", which preserves parameterisation invariance by introducing a multiplicative bias to the stationary distribution. We identify this bias as the well known Jeffreys prior. To support our claims, we show that the distribution of samples from NGD is close to the Laplace approximation to the posterior when $T = 1$. Furthermore, the test loss of ensembles drawn using NGD falls rapidly as we increase the batch size until $B \approx \epsilon N/2$, while above this point the test loss is constant or rises slowly.
The Importance of Generation Order in Language Modeling
Aug 23, 2018
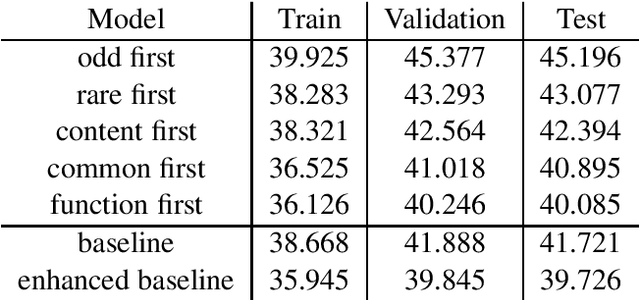
Neural language models are a critical component of state-of-the-art systems for machine translation, summarization, audio transcription, and other tasks. These language models are almost universally autoregressive in nature, generating sentences one token at a time from left to right. This paper studies the influence of token generation order on model quality via a novel two-pass language model that produces partially-filled sentence "templates" and then fills in missing tokens. We compare various strategies for structuring these two passes and observe a surprisingly large variation in model quality. We find the most effective strategy generates function words in the first pass followed by content words in the second. We believe these experimental results justify a more extensive investigation of generation order for neural language models.