 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhases of Muon: When Muon Eclipses SignSGD
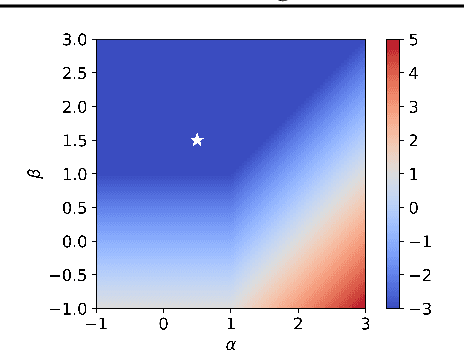
May 10, 2026Recently, Muon and related spectral optimizers have demonstrated strong empirical performance as scalable stochastic methods, often outperforming Adam. Yet their behaviour remains poorly understood. We analyze stochastic spectral optimizers, including Muon, on a high-dimensional matrix-valued least squares problem. We derive explicit deterministic dynamics that provide a tractable framework for studying learning behaviour with a focus on (stochastic) SignSVD, which Muon approximates, and (stochastic) SignSGD, the latter serving as a proxy for Adam. Our analysis shows that for large batch size, SignSVD performs a square-root preconditioning with respect to the data covariance spectrum, while for small batch size smaller eigenmodes behave like SGD, slowing down convergence. We contrast with SignSGD which for generic covariance performs no preconditioning and has no transition, leading to different optimal learning rates and convergence characteristics. The two methods match up to a constant factor with isotropic data, but behave differently with anisotropic data. An analysis of a power law covariance model with data exponent $α$ and target exponent $β$ shows there are three phases in the $(α,β)$ plane: one where SignSGD is uniformly favored, one where SignSVD is uniformly favored, and a third where the two methods exhibit a trade-off in performance.
Logarithmic-time Schedules for Scaling Language Models with Momentum
Feb 05, 2026In practice, the hyperparameters $(β_1, β_2)$ and weight-decay $λ$ in AdamW are typically kept at fixed values. Is there any reason to do otherwise? We show that for large-scale language model training, the answer is yes: by exploiting the power-law structure of language data, one can design time-varying schedules for $(β_1, β_2, λ)$ that deliver substantial performance gains. We study logarithmic-time scheduling, in which the optimizer's gradient memory horizon grows with training time. Although naive variants of this are unstable, we show that suitable damping mechanisms restore stability while preserving the benefits of longer memory. Based on this, we present ADANA, an AdamW-like optimizer that couples log-time schedules with explicit damping to balance stability and performance. We empirically evaluate ADANA across transformer scalings (45M to 2.6B parameters), comparing against AdamW, Muon, and AdEMAMix. When properly tuned, ADANA achieves up to 40% compute efficiency relative to a tuned AdamW, with gains that persist--and even improve--as model scale increases. We further show that similar benefits arise when applying logarithmic-time scheduling to AdEMAMix, and that logarithmic-time weight-decay alone can yield significant improvements. Finally, we present variants of ADANA that mitigate potential failure modes and improve robustness.
Dimension-adapted Momentum Outscales SGD
May 22, 2025We investigate scaling laws for stochastic momentum algorithms with small batch on the power law random features model, parameterized by data complexity, target complexity, and model size. When trained with a stochastic momentum algorithm, our analysis reveals four distinct loss curve shapes determined by varying data-target complexities. While traditional stochastic gradient descent with momentum (SGD-M) yields identical scaling law exponents to SGD, dimension-adapted Nesterov acceleration (DANA) improves these exponents by scaling momentum hyperparameters based on model size and data complexity. This outscaling phenomenon, which also improves compute-optimal scaling behavior, is achieved by DANA across a broad range of data and target complexities, while traditional methods fall short. Extensive experiments on high-dimensional synthetic quadratics validate our theoretical predictions and large-scale text experiments with LSTMs show DANA's improved loss exponents over SGD hold in a practical setting.
Two-Point Deterministic Equivalence for Stochastic Gradient Dynamics in Linear Models
Feb 07, 2025We derive a novel deterministic equivalence for the two-point function of a random matrix resolvent. Using this result, we give a unified derivation of the performance of a wide variety of high-dimensional linear models trained with stochastic gradient descent. This includes high-dimensional linear regression, kernel regression, and random feature models. Our results include previously known asymptotics as well as novel ones.
The High Line: Exact Risk and Learning Rate Curves of Stochastic Adaptive Learning Rate Algorithms
May 30, 2024We develop a framework for analyzing the training and learning rate dynamics on a large class of high-dimensional optimization problems, which we call the high line, trained using one-pass stochastic gradient descent (SGD) with adaptive learning rates. We give exact expressions for the risk and learning rate curves in terms of a deterministic solution to a system of ODEs. We then investigate in detail two adaptive learning rates -- an idealized exact line search and AdaGrad-Norm -- on the least squares problem. When the data covariance matrix has strictly positive eigenvalues, this idealized exact line search strategy can exhibit arbitrarily slower convergence when compared to the optimal fixed learning rate with SGD. Moreover we exactly characterize the limiting learning rate (as time goes to infinity) for line search in the setting where the data covariance has only two distinct eigenvalues. For noiseless targets, we further demonstrate that the AdaGrad-Norm learning rate converges to a deterministic constant inversely proportional to the average eigenvalue of the data covariance matrix, and identify a phase transition when the covariance density of eigenvalues follows a power law distribution.
4+3 Phases of Compute-Optimal Neural Scaling Laws
May 23, 2024



We consider the three parameter solvable neural scaling model introduced by Maloney, Roberts, and Sully. The model has three parameters: data complexity, target complexity, and model-parameter-count. We use this neural scaling model to derive new predictions about the compute-limited, infinite-data scaling law regime. To train the neural scaling model, we run one-pass stochastic gradient descent on a mean-squared loss. We derive a representation of the loss curves which holds over all iteration counts and improves in accuracy as the model parameter count grows. We then analyze the compute-optimal model-parameter-count, and identify 4 phases (+3 subphases) in the data-complexity/target-complexity phase-plane. The phase boundaries are determined by the relative importance of model capacity, optimizer noise, and embedding of the features. We furthermore derive, with mathematical proof and extensive numerical evidence, the scaling-law exponents in all of these phases, in particular computing the optimal model-parameter-count as a function of floating point operation budget.
Mirror Descent Algorithms with Nearly Dimension-Independent Rates for Differentially-Private Stochastic Saddle-Point Problems
Mar 05, 2024
We study the problem of differentially-private (DP) stochastic (convex-concave) saddle-points in the polyhedral setting. We propose $(\varepsilon, \delta)$-DP algorithms based on stochastic mirror descent that attain nearly dimension-independent convergence rates for the expected duality gap, a type of guarantee that was known before only for bilinear objectives. For convex-concave and first-order-smooth stochastic objectives, our algorithms attain a rate of $\sqrt{\log(d)/n} + (\log(d)^{3/2}/[n\varepsilon])^{1/3}$, where $d$ is the dimension of the problem and $n$ the dataset size. Under an additional second-order-smoothness assumption, we improve the rate on the expected gap to $\sqrt{\log(d)/n} + (\log(d)^{3/2}/[n\varepsilon])^{2/5}$. Under this additional assumption, we also show, by using bias-reduced gradient estimators, that the duality gap is bounded by $\log(d)/\sqrt{n} + \log(d)/[n\varepsilon]^{1/2}$ with constant success probability. This result provides evidence of the near-optimality of the approach. Finally, we show that combining our methods with acceleration techniques from online learning leads to the first algorithm for DP Stochastic Convex Optimization in the polyhedral setting that is not based on Frank-Wolfe methods. For convex and first-order-smooth stochastic objectives, our algorithms attain an excess risk of $\sqrt{\log(d)/n} + \log(d)^{7/10}/[n\varepsilon]^{2/5}$, and when additionally assuming second-order-smoothness, we improve the rate to $\sqrt{\log(d)/n} + \log(d)/\sqrt{n\varepsilon}$. Instrumental to all of these results are various extensions of the classical Maurey Sparsification Lemma, which may be of independent interest.
Implicit Diffusion: Efficient Optimization through Stochastic Sampling
Feb 08, 2024



We present a new algorithm to optimize distributions defined implicitly by parameterized stochastic diffusions. Doing so allows us to modify the outcome distribution of sampling processes by optimizing over their parameters. We introduce a general framework for first-order optimization of these processes, that performs jointly, in a single loop, optimization and sampling steps. This approach is inspired by recent advances in bilevel optimization and automatic implicit differentiation, leveraging the point of view of sampling as optimization over the space of probability distributions. We provide theoretical guarantees on the performance of our method, as well as experimental results demonstrating its effectiveness in real-world settings.
Hitting the High-Dimensional Notes: An ODE for SGD learning dynamics on GLMs and multi-index models
Aug 17, 2023We analyze the dynamics of streaming stochastic gradient descent (SGD) in the high-dimensional limit when applied to generalized linear models and multi-index models (e.g. logistic regression, phase retrieval) with general data-covariance. In particular, we demonstrate a deterministic equivalent of SGD in the form of a system of ordinary differential equations that describes a wide class of statistics, such as the risk and other measures of sub-optimality. This equivalence holds with overwhelming probability when the model parameter count grows proportionally to the number of data. This framework allows us to obtain learning rate thresholds for stability of SGD as well as convergence guarantees. In addition to the deterministic equivalent, we introduce an SDE with a simplified diffusion coefficient (homogenized SGD) which allows us to analyze the dynamics of general statistics of SGD iterates. Finally, we illustrate this theory on some standard examples and show numerical simulations which give an excellent match to the theory.
Only Tails Matter: Average-Case Universality and Robustness in the Convex Regime
Jun 22, 2022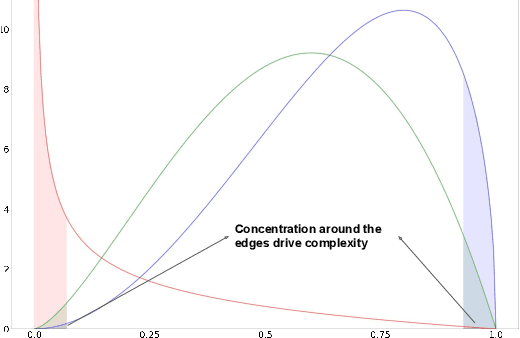


The recently developed average-case analysis of optimization methods allows a more fine-grained and representative convergence analysis than usual worst-case results. In exchange, this analysis requires a more precise hypothesis over the data generating process, namely assuming knowledge of the expected spectral distribution (ESD) of the random matrix associated with the problem. This work shows that the concentration of eigenvalues near the edges of the ESD determines a problem's asymptotic average complexity. This a priori information on this concentration is a more grounded assumption than complete knowledge of the ESD. This approximate concentration is effectively a middle ground between the coarseness of the worst-case scenario convergence and the restrictive previous average-case analysis. We also introduce the Generalized Chebyshev method, asymptotically optimal under a hypothesis on this concentration and globally optimal when the ESD follows a Beta distribution. We compare its performance to classical optimization algorithms, such as gradient descent or Nesterov's scheme, and we show that, in the average-case context, Nesterov's method is universally nearly optimal asymptotically.